【用户模拟器】原理篇一:统计建模的方法

用户模拟器系列文章将会向大家介绍用户模拟器的结构、特点、基于统计建模和深度建模的方法及其优缺点,同时后续的实践篇将会介绍用户模拟器在贝壳IM场景中的应用。
一、用户模拟器简介
近几年来,强化学习在任务导向型对话系统中得到了广泛的应用,而强化学习训练需要对话系统和用户进行交互得到对话数据和累积得分来进行。在IM场景中,和真实用户的交互成本昂贵,数据回流周期慢,不足以支持模型的快速迭代,因此必须构建一个用户模拟器(User Simulator, US)作为对话系统的交互环境来进行闭环训练。有了用户模拟器便可以产生任意多的数据,对话系统可以对状态空间和动作空间进行充分地探索以寻找最优策略。
用户模拟器是对话系统形成闭环训练的重要组成部分,它和对话系统结构类似,但最大的区别在于增加了用户目标的建模。好的用户模拟器不仅能够生成连贯的动作,而且还能够体现多样性和泛化能力。
1.1 特点
一个效果良好的用户模拟器一般需要具备以下 3 个特征:
-
有一个总体的对话目标,能够生成上下文连贯的用户动作; -
有足够的泛化能力,在语料中未出现的对话情形里也能生成合理的行为; -
可以给出定量的反馈评分用于指导模型学习优化。
1.2 结构
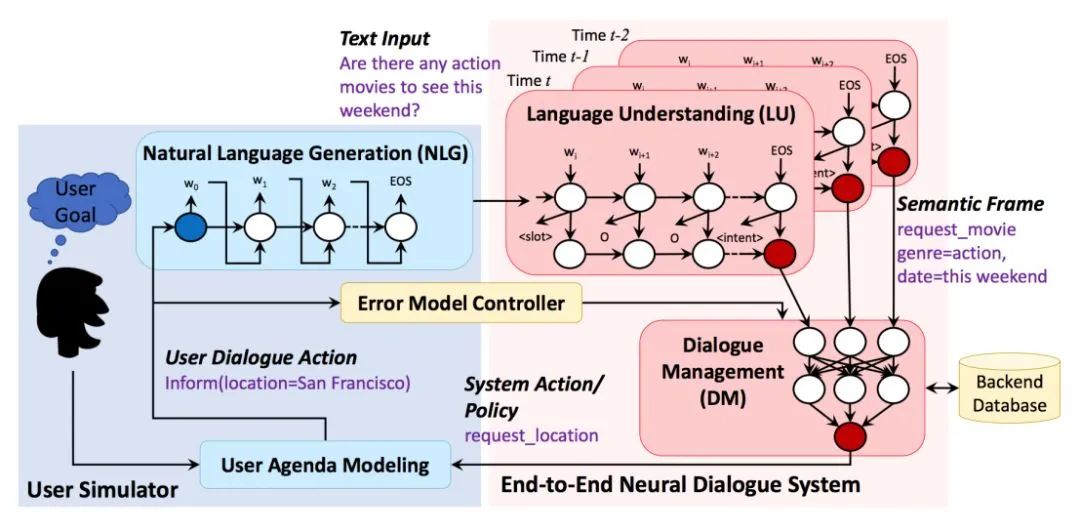
典型的用户模拟器包含以下 4 个基本组成部分:
1.2.1. 用户目标(User Goal)
用户模拟的第一步就是生成一个用户对话的目标,对话系统对此是不可知的,但它需要通过多轮对话交互来帮助用户完成该目标。一般来说,用户目标由两种槽位确定: 可告知槽(informable slots)和可问询槽(requestable slots),可告知槽一般由槽值对构成,是用户用于查询的约束条件,可问询槽则是用户希望向系统问询的属性。例如:用户目标是 “inform(type=movie, genre=action, location=San Francisco, date=this weekend),request(price)” 表达的是用户的目标是想要找一部本周在 San Francisco 上映的动作片,找到电影后再进一步问询电影票的价格属性。有了明确的对用户目标的建模,我们就可以保证用户的回复具有一定的任务导向,而不是闲聊。
1.2.2. 用户模型(User Model)
用户模型对应着对话系统的对话管理模块,它的任务是根据对话历史生成当前的用户动作。用户动作是预先定义好的语义标签,例如 “inform, request, greet, bye” 等等。用户动作的选择应当合理且多样,能够模拟出真实用户的行为。用户模型是用户模拟器的核心组成部分。
1.2.3. 误差模型(Error Model)
它接在 User Model 下游,负责模拟噪声,对用户行为进行扰动以模拟真实交互环境下的不确定性。简单的方式有:随机用不正确的意图替换正确的意图、随机替换为不正确的槽位、随机替换为不正确的槽值等;复杂的方式有模拟基于 ASR 或 NLU 混淆的错误。
1.2.4. 自然语言生成(NLG)
如果用户模拟器需要输出自然语言回复,就需要 NLG 模型将用户动作转换成自然语言表述。例如用户动作标签 “inform(type=movie, genre=action, date=this weekend)” 经过 NLG 模块后生成自然语句 “Are there any action movies to see this weekend?”。
1.3 难点
1.3.1. 对话行为一致性(Coherence)
对话行为要保证前后连贯,符合语境,避免出现不符合逻辑的对话行为。如何综合考虑对话上下文和 User Goal 等因素,保证用户行为序列在多轮交互过程中的一致性是一个有挑战的课题。
1.3.2. 对话行为多样性(Diversity)
模拟用户群的行为特性,需要建模这个群体的行为分布。例如某用户群是健谈的还是寡言的,是犹豫的还是果断的,各部分占比多少,这里引入用户群体画像特征,使得用户模拟器的行为更加丰富多样,贴近目标用户群体。
1.3.3. 对话行为的泛化性(Generalization)
目前来看,无论是基于统计建模方法还是深度学习建模的用户模拟器,在遇到语料中未曾出现的对话上下文时,表现出的泛化能力依旧比较有限。对话行为的泛化性直接体现了用户模拟器是否表现得如同真实用户一样处理更多未见的复杂的对话场景。
二、统计建模的方法
用户模拟器的实现主要有两种方法:统计建模的方法和深度学习建模的方法。统计建模的方法有:N-grams、图论模型、人工设计参数的贝叶斯网络和基于议程(Agenda-based)的方法等。
统计建模的方法大都利用了马尔科夫假设,即可以根据对话当前状态的某种表示来预测下一个用户操作。状态表示通常包括以前的系统操作,但也可能包括更长的对话历史记录和表示用户目标、用户记忆等其他变量。
2.1 N-grams
为了学习和评估对话策略,Eckert等人首先提出了基于n-gram的统计预测用户模型,论文:User modelling for spoken dialogue system evaluation。他们的开创性工作介绍了一个简单的语法模型,在考虑对话系统和用户行为历史的情况下,预测t时刻最可能的用户行为
,在实践中,数据稀疏可能会导致无法使用长对话历史记录。Eckert等人用bigram模型来近似整个对话历史,用
表示系统在t时刻的动作:
该bigram模型具有纯粹的概率性和完全独立于域的优点。它的缺点是对模拟的用户行为没有任何约束,任何用户操作都可能出现在任何系统操作之后,而无视对话历史。
生成的响应可能与前面的系统操作很好地对应,但是由于忽略了所有状态信息,因此它们在更长的对话上下文中常常没有意义。用bigram用户模型模拟的对话往往会持续很长一段时间,用户不断改变目标,重复信息或违反逻辑约束:
System: Where are you flying from?User model: I am flying from New York.System: Where do you want to go?User model: I’m going to New York.
同一组作者Eckert等人和Levin等人在后期著作中,对上述bigram模型进行了改进,以考虑更现实的对话结构。论文:Automatic evaluation of spoken dialogue systems,A stochastic model of human-machine interaction for learning dialog strategies。不再是任何用户操作都可能出现在任何系统操作之后,只有合理的用户响应和系统操作对的概率被估计,而其他所有的概率都假定为零。例如,用于系统对插槽
的请求, 只估计用户实际为槽
提供值的概率,和为另一个槽
提供值的概率:
Levin等人选择的一组概率用户模型参数隐含地表征了模拟用户的合作程度和主动性。Levin模型对用户行为的约束比纯粹的Bigram模型更强,但它也对对话的格式做出了假设。如果对话管理器偏离了预期的简单混合主动填槽对话格式,则需要一组新的参数。
与Bigram模型一样,Levin模型并不能确保在对话过程中不同用户操作之间的一致性,因为有一个错误的假设,即每个用户响应只取决于前一个系统动作。因此,用户操作可能会违反逻辑约束,合成的对话通常会持续很长一段时间,用户会不断改变其目标或重复信息。
2.2 图论模型
Scheffler & Young 提出了一个基于图的模型来克服Levin模型缺乏目标一致性的缺点,同时保持用户行为的可变性。他们的工作结合了行为依赖于目标的确定性规则和概率建模,以覆盖模拟用户的会话行为。论文:Automatic learning of dialogue strategy using dialogue simulation and reinforcement learning.。
在Scheffler & Young的模型中,用户在对话过程中可能采取的所有“路径”都需要提前以网络的形式绘制出来。网络的弧线代表动作,节点代表“选择点”。后者中的一些被识别为概率选择点,表示模拟用户的“随机决策”。这些选择点的合适的概率值是由数据估计出来的。网络中剩余的节点是确定的选择点。在这些点上采取的路由取决于用户目标,该目标在对话过程中保持不变,并表示为一个由槽名-槽值对和相关状态变量组成的表。用户目标的显式表示确保用户始终按照他的目标行事。下图显示了选择点的概念,并使用了一个来自电影票预订域的示例:
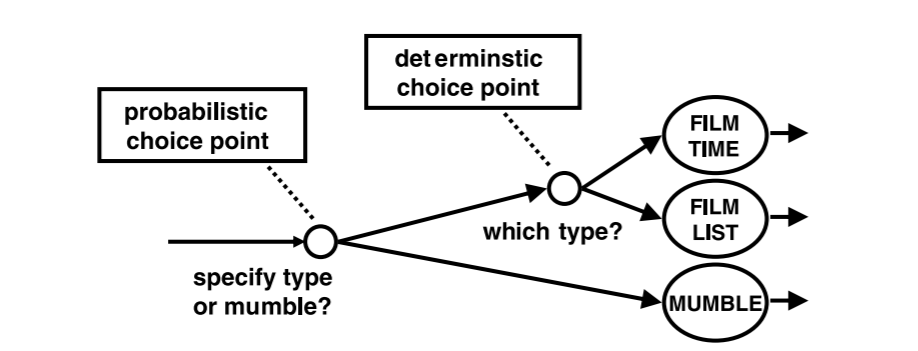
Scheffler & Young工作的主要缺点是对特定领域知识的高度依赖,详细说明所有可能的对话路径是关键问题。作者指出,如果原型对话系统可用,并且为原型对话管理的每个状态都很好地定义了可接受用户操作的范围,那么这个任务可以部分自动化。然而,识别概率性和确定性的选择点仍然需要手动设计。
2.3 贝叶斯网络
Pietquin等人将Scheffler & Young的研究成果与Levin模型相结合,试图避免人工构建选择点网络,同时确保行为符合用户的目标。他的工作的核心思想是将Levin等人选择的概率集设定在用户目标和内存的显式表示上。论文:A probabilistic description of man-machine spoken communication。
在Scheffler & Young的工作中,用户目标只是一个包含槽名-槽值对和相关状态变量的表。Pietquin使用状态变量对用户对每个插槽值的优先级进行排序,并跟踪用户在与系统对话期间提到某条信息的频率。尽管这些用户目标和内存模型相当粗糙,但该工作已经意识到,要准确预测用户行为,需要更好地理解用户状态及其对会话行为的影响。
在该工作中,Pietquin使用经验原则和常识手动选择所有的模型参数,由人工设定合适的概率值。Pietquin建议在未来的工作中,将用户模型中的条件依赖以图形化的方式可视化并以贝叶斯网络实现,如下图所示:
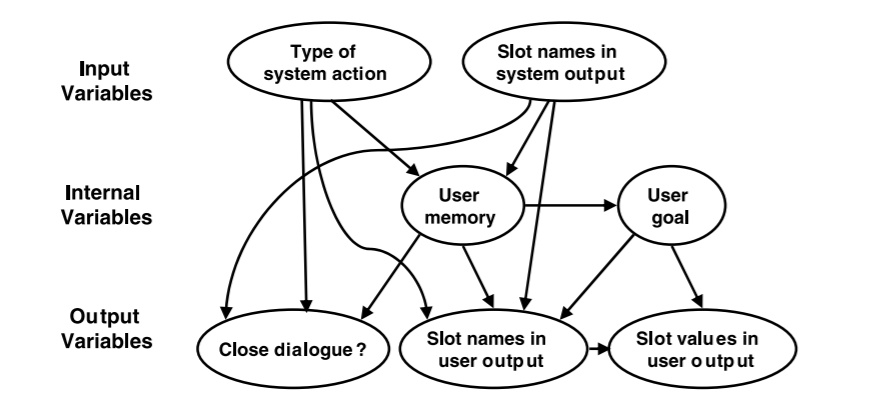
作者表明,该网络可以很容易地扩展到包括合作程度、主动性等因素。但是,直观上并不清楚哪些参数是这些用户属性建模的潜在候选参数,以及如何对它们进行人机对话数据训练。
2.4 基于议程的方法
统计建模的方法中使用最为广泛的是基于议程(Agenda-based)的方法。基于议程的方法通过一个栈的结构把对话的议程定下来,对话的过程就是进栈和出栈的动作。该方法对用户状态表示、状态转移、Agenda 更新、Goal 更新进行了精细建模,逻辑清晰,可落地性强,业界很多工作都基于该方法进行扩展和优化。原文链接:http://svr-ftp.eng.cam.ac.uk/~sjy/papers/scyo09.pdf。
2.4.1 模型假设
用户和系统的对话可以表示为一系列状态转换和对话行为的序列。在任意时刻 t,用户在状态 S,采取动作 ,过渡到中间状态 S',收到对话系统回复的动作 ,然后转换到下一个状态 S'',然后重新开始下一循环。
假设采用马尔可夫状态表示,则可以将用户行为分解为三个模型:
-
用户动作选择模型 :用于建模用户动作选择; -
状态更新模型 :用于建模发出用户动作 后用户状态转移到 S' 的概率; -
状态转移模型 :用于建模接收到系统动作 后用户状态转移到 S'' 的概率。
2.4.2 工作机制
基于议程的用户模拟器模型工作流程主要就是用户目标和议程的初始化和动态更新。
2.4.2.1. 初始化
受基于议程的对话管理方法的启发,用户状态 被分解为议程A和目标G,即S=(A,G),其中G=(C,R)由约束C和请求R组成。
在对话过程中,目标G以一致的,目标明确的方式确保用户行为。C和R都可以方便地表示为【槽/值】对列表,如以下示例所示:
用户 Agenda 是一个类似堆栈的结构,它存储着待执行的用户对话行为(user dialogue act)。在对话开始时,使用系统数据库随机生成新的用户目标,然后会将用户目标中所有目标约束转换为告知行为(inform acts),所有的目标问询转换为问询行为(request acts)填充到用户 Agenda。在 Agenda 的底部,会添加一个 bye act 用于结束对话。上面用户目标对应的初始Agenda如下所示:
2.4.2.2. 动态更新
随着对话的进行,Agenda 和 Goal 会动态更新,并从 Agenda 的顶部弹出用户对话行为以形成本轮用户动作 。在接收到系统回复 后,根据写好的规则新的用户动作会被压入到 Agenda 的栈顶,不相关的用户动作会被删除。当需要考虑动作的优先级时,栈顶的用户动作也可以临时被缓存起来先执行优先级高的动作,从而为模拟器提供简单的用户记忆模型。下图给出了用户目标和 Agenda 变化的示例。

2.4.3 模型求解
2.2中用户目标和议程动态更新的过程依赖于2.1中分解得到的三个子模型的求解。
2.4.3.1. 用户动作选择模型
假定议程(长度为N)是根据优先级排序的,其中A[N]表示顶部,A[1]表示底部。因此,形成用户响应等同于从堆栈顶部弹出n个项。假设 表示 中的第i个对话行为,则最终用户行为如下所示:
用A[N-n+1..N] 代表在 Agenda 栈顶的 top-n 的用户动作 acts,则动作选择模型变为:
其中 δ 为狄拉克函数,该模型的直观理解是如果 在 top-n 的 acts 里,那么 P 趋于 1,此时 将会被选中并发出。top-n 的 n 的选取体现了用户模拟器的主动性程度,它可以从对话语料中统计得出,也可以根据经验指定一个小的数值。
2.4.3.2. 状态更新模型
其中 A' 代表选择后的 Agenda,N'=N-n 代表 A' 的大小,为了使 P 概率最大,则要求 A' 等于对 A 进行出栈操作后的结果 A[1..N'],G 保持不变。
2.4.3.3. 状态转移模型
已知 S=(A,G),根据概率的链式法则和条件独立性假设,在用户模拟器接收到 后,可以将状态转移模型 分解成 Agenda 更新模型和 Goal 更新模型。
如果不对 A'' 和 G'' 做限制,模型可能的状态转移空间太大,参数太多而不能直接人工指定,甚至通过大量的训练数据都不能获得一个可靠的参数估计。但如果假设 A'' 是从 A' 推导出来的,G'' 是从 G' 推导出来的,那么在每种情况下,仅需要有限个数的原子操作就能描述这个状态转移过程。
Agenda 更新模型
Agenda 从 A' 转移 A'' 的过程可以看做一系列入栈操作,将用户 dialogue acts 添加到栈的顶部。接下来会进行“清理”工作,比如:删除冗余的 dialogue acts,null() acts 以及 Goal 中那些已经被填充的 request slots 关联的 request() acts。为了简化起见,只考虑入栈操作,栈底部 1 到 N' 的元素是保持不变的,那么 Agenda 更新模型可以改写为以下公式:
该公式表示 A'' 新增 N''-N' 个元素,而栈底元素不变。作者假设在 中的每一个系统 act 只会触发一个入栈操作,令 N''=N'+M,可得:
上式表示的是每一个系统 act 会触发一个入栈操作,同时该操作还和 Goal 有关。此时,模型已经足够简单,都可以通过编写人工规则来实现当接收到系统 act 后的逻辑,比如:当 中的元素 x=y 和 G'' 里的约束条件冲突时,可以将以下任意一个用户 act 压入栈 A'':negate(),inform(x=z),deny(x=y, x=z) 等。
Goal 更新模型
Goal 更新模型 描述的是当给定 的情形下,约束条件 C' 和问询内容 R' 是如何变化的。假定当给定 C'' 的情形下,R'' 是条件独立于 C'' 的,那么可以得到:
为了控制 R' 转移到 R'' 的空间大小,可以假设问询的槽位是相互独立的,并且每个槽只能利用 的信息来更新,或者保持不变。利用 R[k] 表示第 k 个可问询槽,M( ,C'') 表示 中的槽信息与 Goal 约束条件的匹配情况。
为了简化 P(C''| ,R',C'),作者假设 C'' 是通过添加新约束条件,改变约束条件的槽值或者什么都不改变得到的。转移过程也不用考虑所有的情形,可以简化为只考虑 的一些二值标识,比如:“ 是否在请求约束条件的槽?”,“ 是否在告知没有找到满足约束条件的元素?”等。这样模型可以简化到可以通过人工编写规则实现,落地性很强。
基于议程的方法具有明显的优点:
-
可以冷启动,在缺乏标注对话语料时可以根据专家经验进行设计; -
用户行为完全可控,基于议程的方法通过一个栈的结构把对话的议程定下来,对话的过程就变成进栈和出栈的动作,上下文关联性很强,保证了用户动作生成的一致性,一般不会出现异常用户行为。
但是,该方法也存在一些缺点:
-
在对话行为灵活性和多样性比较欠缺,在实操层面可以通过引入一些随机性提升灵活度; -
需要专家手动构建,代价大,覆盖度不够。
基于议程的方法一般适用于话术简单清晰的填槽式对话任务。
三、总结
本文主要介绍了用户模拟器的结构、特点和实现的难点,并详细介绍了几种基于统计建模来实现用户模拟器的方法。通过统计分析和人工编写规则尽管落地性强,精准率高,但是成本很高,因此寻求数据驱动的模型化方法是一个很好的途径。下一期我们将详细探索基于深度学习建模的方法。
四、参考文献
-
https://blog.csdn.net/c9yv2cf9i06k2a9e/article/details/98549007 -
https://blog.csdn.net/qq_28385535/article/details/104249156 -
A survey of statistical user simulation techniques for reinforcement-learning of dialogue management strategies -
Agenda-Based User Simulation for Bootstrapping a POMDP Dialogue System -
The Hidden Agenda User Simulation Model
作者介绍
刘娜,2019年6月毕业于北京邮电大学自动化学院,毕业后加入贝壳找房语言智能与搜索部,主要从事NLP及强化学习相关工作。
下期精彩
【用户模拟器】原理篇二:深度建模的方法

推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




