如何利用动态信息数据构建用户画像?
写在前面 / 本文仅供学习交流,不做商业用途。


什么是用户画像?
Alan Cooper(交互设计之父)最早提出了persona的概念:“Personas are a concrete representation of target users.”Persona是真实用户的虚拟代表,是建立在一系列真实数(Marketing data,Usability data)之上的目标用户模型。
通过用户调研去了解用户,根据他们的目标、行为和观点的差异,将他们区分为不同的类型,然后每种类型中抽取出典型特征,赋予名字、照片、一些人口统计学要素、场景等描述,就形成了一个人物原型(personas)。
为何要建立用户画像 personas?
Cooper认为建立Personas的好处有:
Creates a common language
Users are no longer elastic
Provides a target - no longer designing for everyone in the world
End debates about prioritization and implementation
简而言之,用户画像(persona)为了让团队成员在产品设计的过程中能够抛开个人喜好,将焦点关注在目标用户的动机和行为上进行产品设计。 因为,产品经理为具体的人物做产品设计要远远优于为脑中虚构的东西做设计,也更来得容易。

用户画像的价值
精准营销
精准营销是用户画像或者标签最直接和有价值的应用。这部分也是我们广告部门最注重的工作内容。当我们给各个用户打上各种“标签”之后,广告主(店铺、商家)就可以通过我们的标签圈定他们想要触达的用户,进行精准的广告投放。
助力产品
一个产品想要得到广泛的应用,受众分析必不可少。产品经理需要懂用户,除了需要知道用户与产品交互时点击率、跳失率、停留时间等行为之外,用户画像能帮助产品经理透过用户行为表象看到用户深层的动机与心理。
行业报告与用户研究
通过对用户画像的分析可以了解行业动态,比如90后人群的消费偏好趋势分析、高端用户青睐品牌分析、不同地域品类消费差异分析等等。这些行业的洞察可以指导平台更好的运营、把握大方向,也能给相关公司(中小企业、店铺、媒体等)提供细分领域的深入洞察。
如何构建用户画像
一个标签通常是人为规定的高度精炼的特征标识,如年龄段标签:25~35岁;地域标签:北京;用户标签,向我们展示了一种朴素、简洁的方法用于描述用户信息。使得用户画像模型具备实际意义。能够较好的满足业务需求。
1.数据源分析
构建用户画像是为了还原用户信息,因此数据来源于:所有用户相关的数据。
将用户数据划分为静态信息数据、动态信息数据两大类。
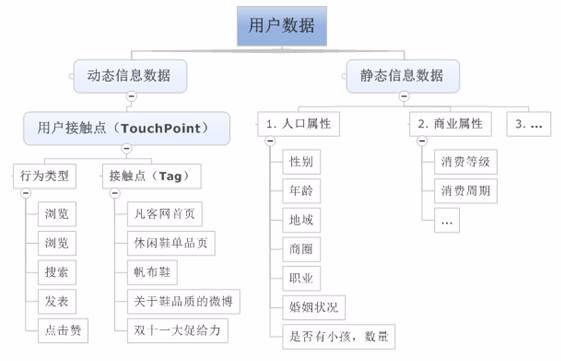
静态信息数据:用户相对稳定的信息,如图所示,主要包括人口属性、商业属性等方面数据。这类信息,自成标签,如果企业有真实信息则无需过多建模预测,更多的是数据清洗工作,因此这方面信息的数据建模不是本文重点。
动态信息数据:用户不断变化的行为信息,如果存在上帝,每一个人的行为都在时刻被上帝那双无形的眼睛监控着,广义上讲,一个用户打开网页,买了一个杯子;与该用户傍晚溜了趟狗,白天取了一次钱,打了一个哈欠等等一样都是上帝眼中的用户行为。当行为集中到互联网,乃至电商,用户行为就会聚焦很多,如上图所示:浏览凡客首页、浏览休闲鞋单品页、搜索帆布鞋、发表关于鞋品质的微博、赞“双十一大促给力”的微博消息。等等均可看作互联网用户行为。
本文以互联网电商用户,为主要分析对象,暂不考虑线下用户行为数据(分析方法雷同,只是数据获取途径,用户识别方式有些差异)。在互联网上,用户行为,可以看作用户动态信息的唯一数据来源。如何对用户行为数据构建数据模型,分析出用户标签,将是本文着重介绍的内容。
2.目标分析
用户画像的目标是通过分析用户行为,最终为每个用户打上标签,以及该标签的权重。如,红酒 0.8、李宁 0.6。
标签,表征了内容,用户对该内容有兴趣、偏好、需求等等。
权重,表征了指数,用户的兴趣、偏好指数,也可能表征用户的需求度,可以简单地理解为可信度,概率。
3.数据建模方法
一个事件模型包括:时间、地点、人物三个要素。每一次用户行为本质上是一次随机事件,可以详细描述为:什么用户,在什么时间,什么地点,做了什么事。
什么用户:关键在于对用户的标识,用户标识的目的是为了区分用户、单点定位。
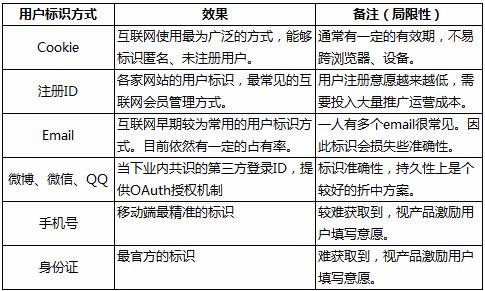
以上列举了互联网主要的用户标识方法,获取方式由易到难。视企业的用户粘性,可以获取的标识信息有所差异。
什么时间:时间包括两个重要信息,时间戳+时间长度。时间戳,为了标识用户行为的时间点,如,1395121950(精度到秒),1395121950.083612(精度到微秒),通常采用精度到秒的时间戳即可。因为微秒的时间戳精度并不可靠。浏览器时间精度,准确度最多也只能到毫秒。时间长度,为了标识用户在某一页面的停留时间。
什么地点:用户接触点,Touch Point。对于每个用户接触点。潜在包含了两层信息:网址 + 内容。网址:每一个url链接(页面/屏幕),即定位了一个互联网页面地址,或者某个产品的特定页面。可以是PC上某电商网站的页面url,也可以是手机上的微博,微信等应用某个功能页面,某款产品应用的特定画面。如,长城红酒单品页,微信订阅号页面,某游戏的过关页。
内容:每个url网址(页面/屏幕)中的内容。可以是单品的相关信息:类别、品牌、描述、属性、网站信息等等。如,红酒,长城,干红,对于每个互联网接触点,其中网址决定了权重;内容决定了标签。
注:接触点可以是网址,也可以是某个产品的特定功能界面。如,同样一瓶矿泉水,超市卖1元,火车上卖3元,景区卖5元。商品的售卖价值,不在于成本,更在于售卖地点。标签均是矿泉水,但接触点的不同体现出了权重差异。这里的权重可以理解为用户对于矿泉水的需求程度不同。即,愿意支付的价值不同。
标签 权重
矿泉水 1 // 超市
矿泉水 3 // 火车
矿泉水 5 // 景区
类似的,用户在京东商城浏览红酒信息,与在品尚红酒网浏览红酒信息,表现出对红酒喜好度也是有差异的。这里的关注点是不同的网址,存在权重差异,权重模型的构建,需要根据各自的业务需求构建。所以,网址本身表征了用户的标签偏好权重。网址对应的内容体现了标签信息。
什么事:用户行为类型,对于电商有如下典型行为:浏览、添加购物车、搜索、评论、购买、点击赞、收藏 等等。不同的行为类型,对于接触点的内容产生的标签信息,具有不同的权重。如:
购买权重计为5,浏览计为1
红酒 1 // 浏览红酒
红酒 5 // 购买红酒
综合上述分析,用户画像的数据模型,可以概括为下面的公式:
用户标识 + 时间 + 行为类型 + 接触点(网址+内容),某用户因为在什么时间、地点、做了什么事,所以会打上**标签。
用户标签的权重可能随时间的增加而衰减,因此定义时间为衰减因子r,行为类型、网址决定了权重,内容决定了标签,进一步转换为公式:
标签权重=衰减因子×行为权重×网址子权重
举例:用户A,昨天在品尚红酒网浏览一瓶价值238元的长城干红葡萄酒信息。
标签:红酒,长城
时间:因为是昨天的行为,假设衰减因子为:r=0.95
行为类型:浏览行为记为权重1
地点:品尚红酒单品页的网址子权重记为 0.9(相比京东红酒单品页的0.7)
假设用户对红酒出于真的喜欢,才会去专业的红酒网选购,而不再综合商城选购。
则用户偏好标签是:红酒,权重是0.950.7 1=0.665,即,用户A:红酒 0.665、长城 0.665。
上述模型权重值的选取只是举例参考,具体的权重值需要根据业务需求二次建模,这里强调的是如何从整体思考,去构建用户画像模型,进而能够逐步细化模型。

作者:iPM秋野
转载链接:http://www.jianshu.com/p/48b620d2f174





