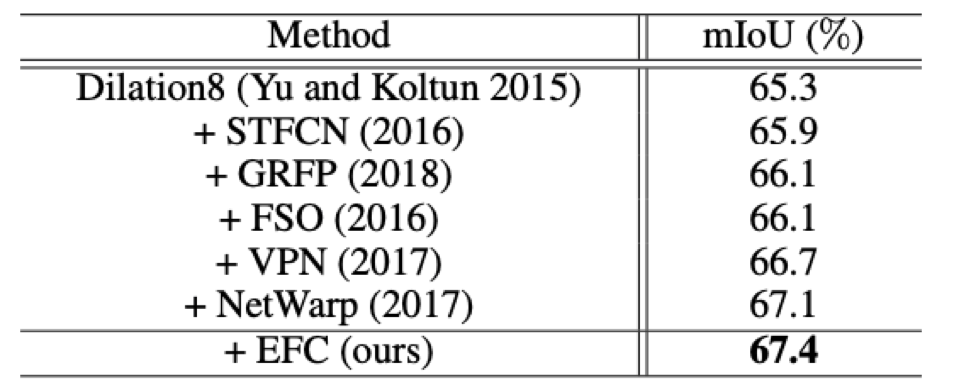
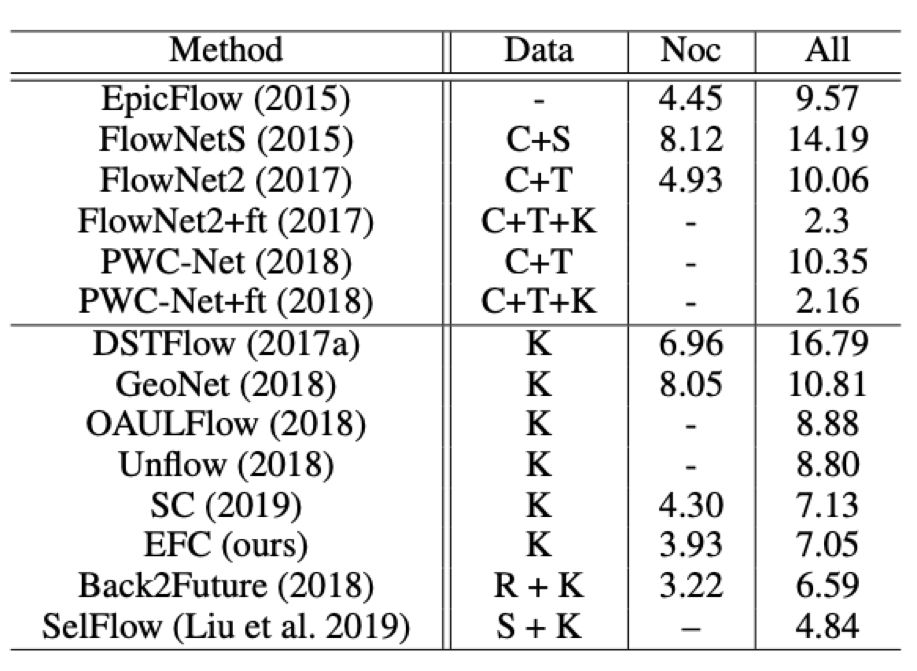
本文介绍商汤科技在AAAI 2020 上的论文《Every Frame Counts: Joint Learning of VideoSegmentation and Optical Flow》,他们在这篇工作中提出了一种新的视频语义分割和光流联合学习算法。
![]()
论文地址:https://arxiv.org/pdf/1911.12739.pdf
视频语义分割的一个主要的挑战是缺少标注数据。
在大多数基准数据集中,每个视频序列(20帧)往往只有一帧是有标注的,这使得大部分监督方法都无法利用剩余的数据。
为了利用视频中的时间-空间信息,许多现有工作使用预先计算好的光流来提升视频分割的性能,然而视频分割和语义分割仍然被看作是两个独立的任务。
在这篇文章中,作者提出了一个新颖的光流和语义分割联合学习方案。
语义分割为光流和遮挡估计提供了更丰富的语义信息,而非遮挡得光流保证了语义分割的像素级别的时序一致性。
作者提出的语义分割方案不仅可以利用视频中的所有图像帧,而且在测试阶段不增加额外的计算量。
视频语义分割通过利用前后帧的语义信息,往往有着比图像分割更高的准确率,因此在机器人和自动驾驶领域有着丰富的应用。
然而目前的视频语义分割主要面临两个挑战:
缺少标注数据和实时性的问题。
一方面由于标注工作耗时耗力,一个视频片段往往只标注一帧,导致很多方法难以利用全部的数据,或者需要使用额外的数据集做预训练;
另一方面由于对前后帧之间进行信息交互往往为模型引入额外的模块,导致视频分割效率低。
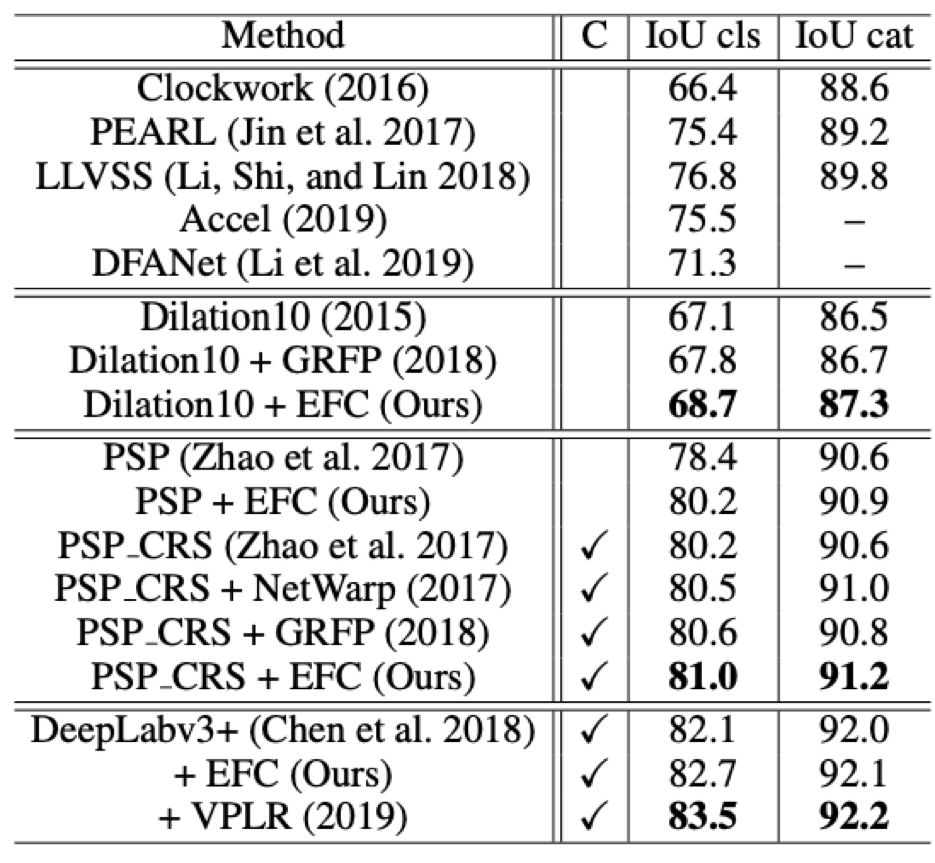
第一类通过利用前后帧的时序信息来为视频分割加速,如Clockwork network (Shelhamer et al. 2016) ,DeepFeature Flow (Zhu et al. 2017) 和 (Li, Shi, and Lin 2018) 等,这类模型对前一帧的特征图或者分割结果进行简单处理即可得到下一帧的分割结果了,从而大大减少视频分割中的冗余和加速,但语义分割的准确率会有所降低;
第二类方法如 (Fayyaz et al. 2016) ,Netwarp (Gadde,Jampani, and Gehler 2017),PEARL (Jin et al. 2017) 等通过光流/RNN等模块将前后帧的特征进行融合或添加约束以学习到更强的表示能力,从而提高语义分割的准确率。
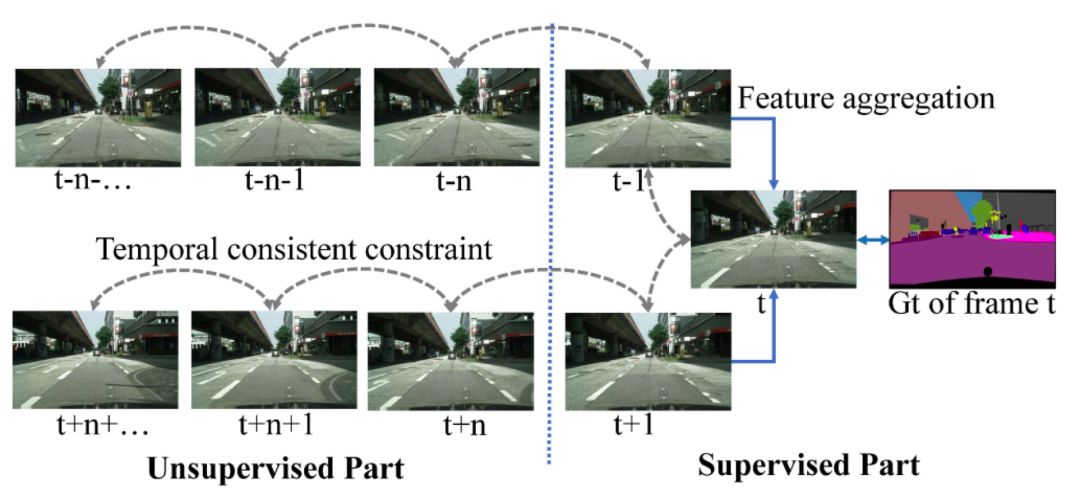
图1:和使用特征融合(feature aggregation)的方法往往只利用标注帧附近的少数帧相比,本文通过学习的光流来为视频帧添加时序一致性约束,通过这种约束可以间接把分割标注传导到其他无标注的帧上,从而利用全部的数据。
光流作为视频中前后帧之间像素级别的关联,在视频语义分割中一直有着重要的地位。
例如 (Li, Shi, and Lin 2018; Zhu et al. 2017; Shelhameret al. 2016) 通过光流来重新利用前一帧的特征图从而为视频分割加速;
(Fayyaz et al. 2016; Jin et al. 2017; Gadde,Jampani, and Gehler 2017; Nilsson and Sminchisescu 2018; Hur and Roth 2016) 通过光流指导的特征融合来获得更好的分割准确率。
然而上述方法面临两个问题,一方面其往往使用现成的在其他数据集上训练的光流模型(FlowNet),导致了分割效率的降低;
另一方面上述方法往往只利用了标准帧附近的少数帧,没有充分利用整个数据集和发挥光流的作用。
为了解决上述两个问题,作者提出了一个光流和语义分割联合学习的框架,语义分割为光流和遮挡估计提供了更丰富的语义信息,而非遮挡得光流保证了语义分割的像素级别的时序一致性。
本文模型通过在视频中无监督学习光流并且使用光流对前后帧语义分割的特征图施加约束来使得两个任务互相增益并且没有显式的特征融合,这种隐式的约束可以帮助利用数据集中的全部数据并学到更鲁棒的分割特征以提高分割准确率,并且不会在测试阶段增加额外的计算量。
图 2:
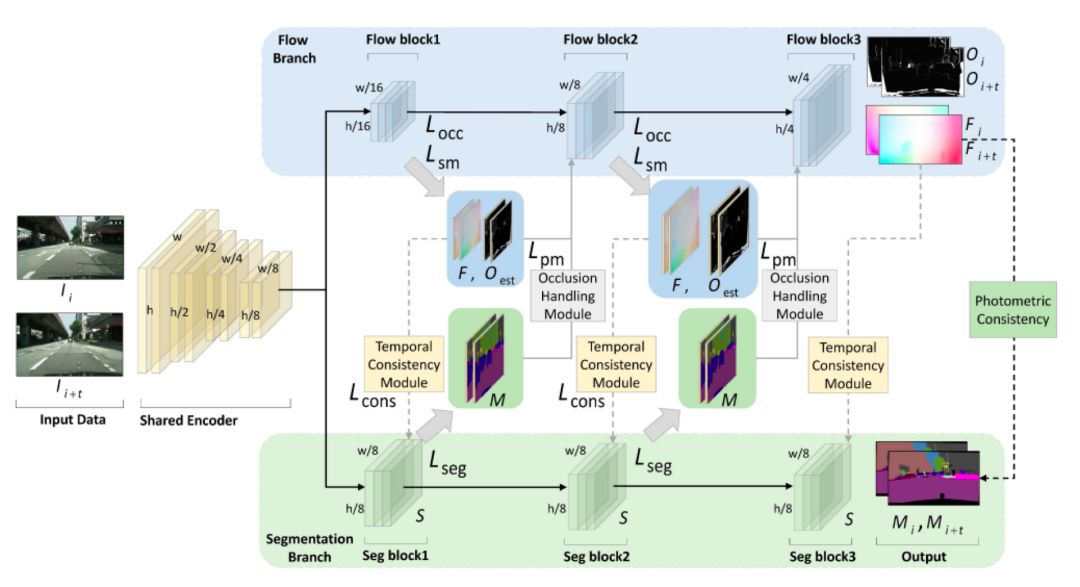
本文提出的联合学习框架,输入图片经过共享编码器后分为两个分支,第一个是光流分支,第二个是分割分支。
block代表模型的特征图,灰色的虚线代表时序一致性约束,灰色实线代表遮挡估计模块。
对于一对图片I_i和I_{i+t},设其对应的分割特征图为S,设学习到的光流为F,遮挡Mask为O,(S,F,O均包含三个block,如图所示),则两帧分割特征图可以通过光流warp进行转换:
S_i^{warp}= Warp(S_{i+t},F_{i->i+t})。
考虑到遮挡的截断区域无法使用光流进行对齐,因此这些区域不计算损失。
两帧的其他区域对应的分割特征图通过光流进行warp对齐后的一致性损失为第一帧的分割特征图和第二帧经过warp的分割特征图的非遮挡区域的2范数。
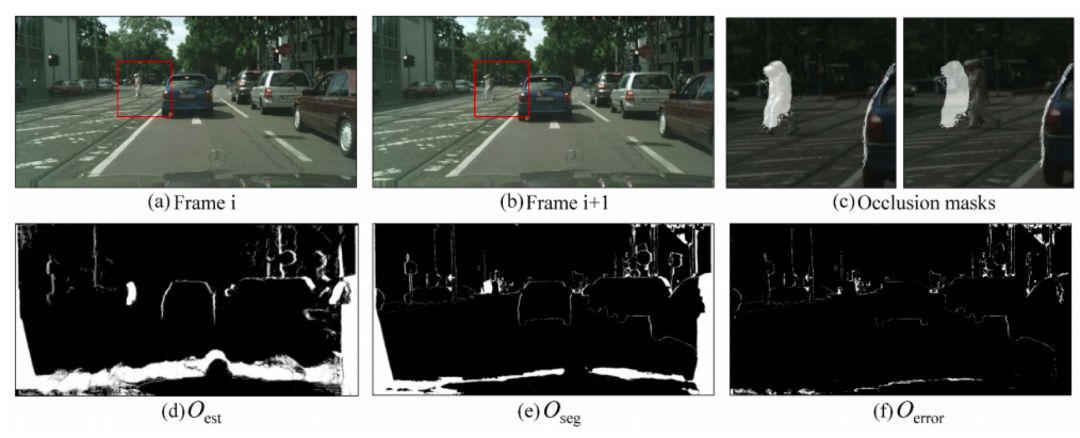
文中所说的遮挡意味着两帧图片中光度的不一致性,它一般由图像中遮挡,截断(汽车离开相机拍摄)和移动目标导致,这里作者使用无监督的方式学习遮挡区域,通过反向光流推测出可能无法对齐的像素位置O,模型根据此学习得到O_{est};
两帧的分割结果通过光流warp不一致的区域设为O_{seg},O_{seg}应包括遮挡区域和光流估计错误的区域,因此O_{error} = O_{seg}-O_{est}应为光流估计的重点区域。
在计算光流估计的损失函数时,作者不考虑遮挡区域(O_{est})的损失,而加大重点区域(O_{error})的权重,遮挡估计的示意图如图3所示。
在训练时,作者从每个视频小段中随机选择10对图片来进行训练,其中五对包含标注帧,而另外五对均不包含标注帧。
对于标注帧,直接使用监督的语义分割损失来进行学习;
对于不包含标注帧的情况,通过两帧的一致性约束来对模型进行约束和学习。
通过这种约束学习,标注信息可以从一帧传播到其他的未标注帧,而即使是两个未标注帧也可以通过一致性来学习。
图4:
Cityscapes验证集分割结果,从上至下分别为原图,本文算法分割结果,PSPNet分割结果和GT。
可以看出本文算法对移动目标(汽车,自行车)和出现频次较少目标(横向卡车)分割效果较好。
图5:KITTI数据集上光流估计结果,从上至下分别为原图,本文算法估计结果,GeoNet估计结果和GT。
可以看出本文算法对移动目标的边缘估计更为准确。
AAAI 2020 报道:
新型冠状病毒疫情下,AAAI2020 还去开会吗?
美国拒绝入境,AAAI2020现场参会告吹,论文如何分享?
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
![]()
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页