[ICCV2019] LearningToPaint:一个绘画 AI
来源:极市平台
Demo: YouTube
Arxiv: https://arxiv.org/abs/1903.04411
Github: hzwer/LearningToPaint (Colaboratory在线尝试)
如何让机器像画家一样,用寥寥数笔创造出迷人的画作?使用深度强化学习方法,我们让 AI 学会用数百个笔画重现纹理丰富的自然图像,AI 的训练过程不需要人类绘画的经验或笔画轨迹数据。
以人脸 (CelebA) 为例,需要一张 GPU,10 小时训练笔画渲染器,40 小时训练 AI,其间 AI 画了数百万张图片来学习。
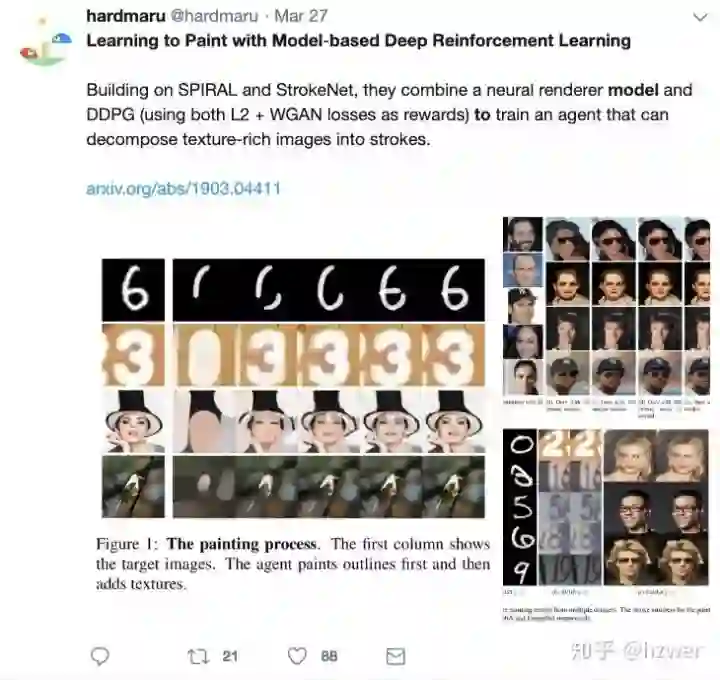
下面是我们的 AI 画不同类型的图片的效果,我们的 AI 最终学会了先画出大致轮廓,再填充细节的策略。

泛化的效果也不错,如果再把图片放大分块修一下细节,视觉效果会更好

介绍
小时候学素描,我觉得老师的水平非常高,因为他们能把静物和人都画的非常像。后来,我在网上看到一些画家的作品,比如丢勒(德国画家),早期的毕加索,才明白了一点什么叫做大师的素描。他们的画非常干净,线条表现力极强,用非常少的笔画数,非常简单的调子,构建出生动的形象。这是一般绘画爱好者花多少时间也难以模仿的,需要对事物结构的深刻理解,对画笔的控制能力和对笔画相互关系的极强把握。
计算机中,一张图片由 n x n 个像素点组成,每个点由 RGB 三个值确定颜色。从这个意义上来说,让计算机临摹一张画,最简单的方法就是逐个像素填充。而人在画画的时候,是用笔画去构建一张图片的。如何让计算机像人一样绘画?这是我在接触深度学习不久后就十分感兴趣的问题。
从强化学习的角度看,我们需要设计一个 AI,给它一个画布和目标图。AI 的每一步在画布上画一个笔画,当它画的笔画使画布和目标图更像时,我们就给它奖励,驱动它学习。我们可以设定一个笔画上限,让 AI 在给定的笔画数后终止。
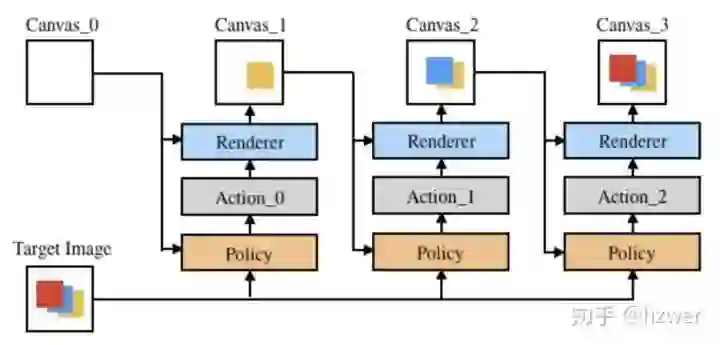
任务的困难
每一个笔画的动作空间很大,AI 要决策一个笔画的位置,形状,颜色,透明度,而每项参数都有非常多选择。如果我们强行将动作离散化,会损失控制的精度,同时还会面临组合爆炸的问题(每项参数选择数乘法原理)。一般的强化学习方法要求 AI 通过大量尝试来对环境进行建模,这是非常困难和耗时的。有兴趣的朋友可以了解一下 Deepmind 的 SPIRAL,使用了大量算力去解这个问题。
如果我们真的将 AI 接入一个绘画软件,笔画渲染是一个很耗时的操作,数据的获取会比较昂贵。
想要完成纹理丰富的自然图像绘画,需要的笔画数很多,这需要 AI 有比较强的计划能力。AI 需要考虑如何组合笔画,笔画的覆盖关系等。
算法
我们的基准算法是深度确定策略梯度 (DDPG) 算法,简单来说,DDPG 运用了演员-评论家(Actor - Critic) 框架,是一种是策略梯度算法和值函数方法的混合算法,其中策略网络被称为 Actor,而价值网络被称为 Critic。在画画这个任务中,Actor 每次画一个笔画,而 Critic 来为 Actor 的这个笔画做一个评价,Actor 的目标是得到更好的评价,Critic 的目标是评价得更准确。DDPG 的优点是能够在连续的动作空间上作决策,也就是说,我们可以设计一个 k 维向量 


为了解决环境探索建模困难的问题,我们预训练了一个神经网络笔画渲染器,可以快速地根据笔画的参数给出渲染在画布上的笔画,支持在 GPU上并行。
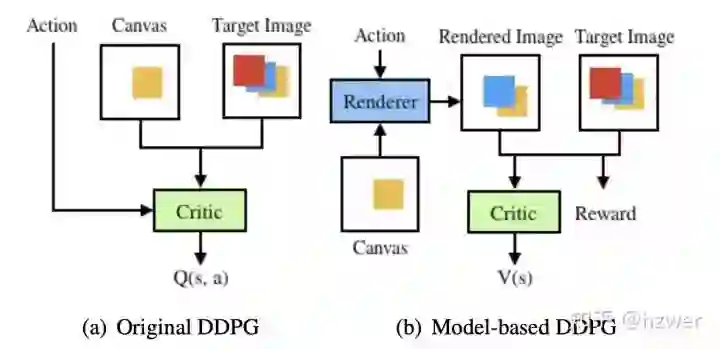
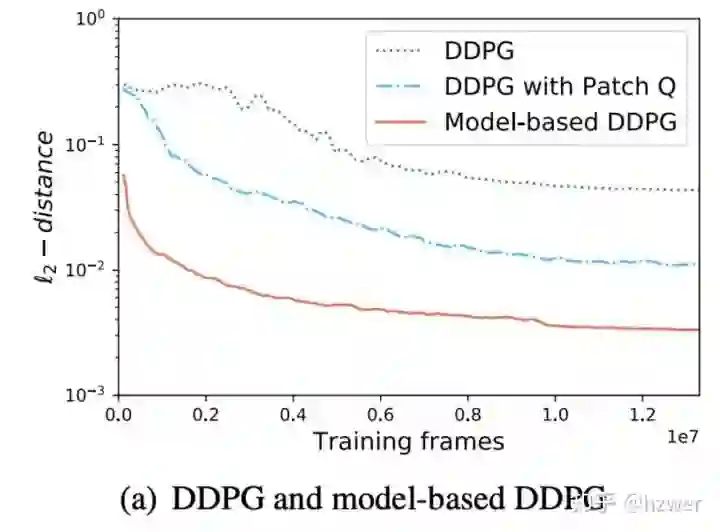
训练技巧
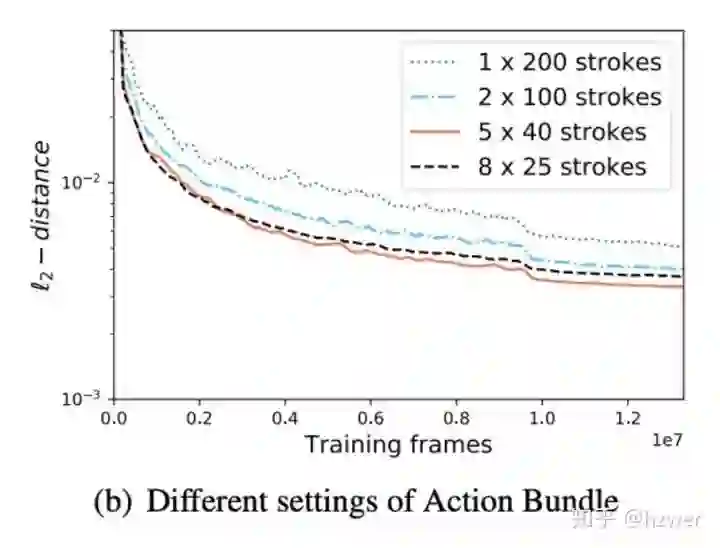
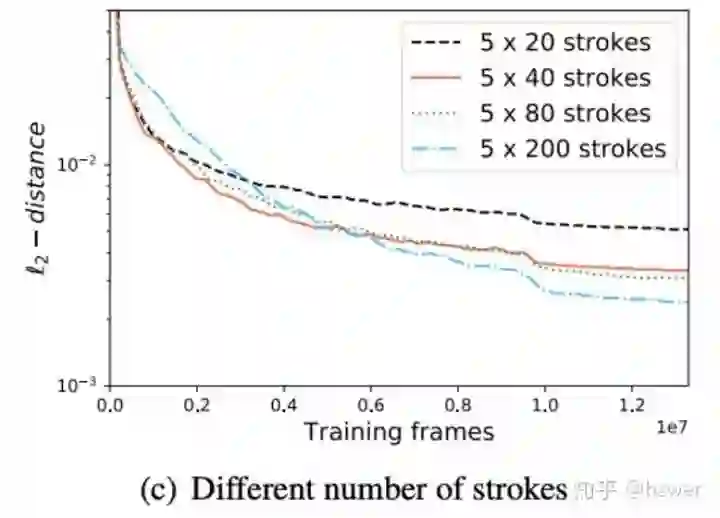
动作束 (Action Bundle)。Actor 一次决策多个笔画,一方面,实验证明 Actor 有这样的能力,并且能显式地让 Actor 学习了笔画的组合;另一方面,减少网络的推断次数可以加速,步数减少还能加快 Critic 网络的收敛。实验证明,让 Actor 一次出 5 个笔画比较合适,一次出太多笔画会提高对 Actor 能力的要求。下图是 200 笔画人脸的训练曲线,分别一次出 1, 2, 5, 8 个笔画,纵坐标是 AI 结束绘画时画布和目标图的 L2 距离。
2. Wasserstein 生成对抗损失函数 (WGAN Loss)。我们需要度量画布和目标图的相似度以给出奖励函数,我们发现 WGAN Loss 是一种比欧几里得距离更好的度量,使得最后画出来的图细节更丰富。
3. 网络结构设计。Actor 和 Critic 是输入缩小版本的 ResNet-18。Batch Normalization (BN) 可以加快 Actor 训练,而在 Critic 上效果不明显。Critic 使用带 TReLu 激活函数的 Weight Normalization (WN with TReLu)。渲染器用 Sub-pixel 来代替反卷积显著消除棋盘效应。GAN 的判别器网络用了类似 PatchGAN 的结构,加上 WN with TReLu。我们的方法对于超参数也不太敏感,基本都使用了跟别人论文类似的超参数。具体细节见 paper。
效果
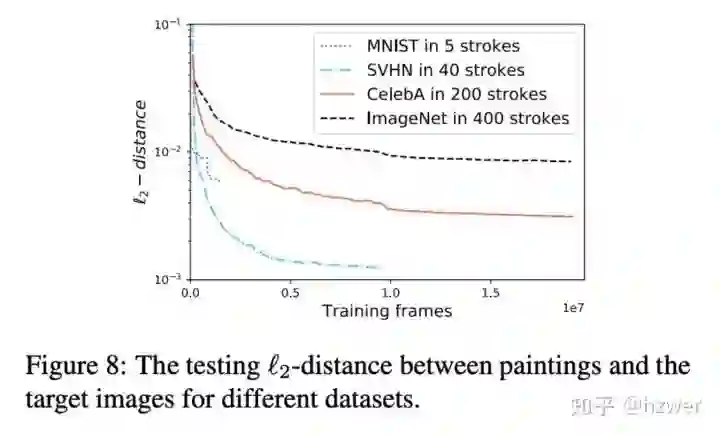
我们使用在几个数据集上做了实验,包括手写数字 (MNIST),街景门牌 (SVHN),名人人脸 (CelebA),自然场景图像 (ImageNet) ,限制的笔画数分别是 5, 40, 200, 400。

我们对比了用不同的笔画数画人脸的结果,从 100 个笔画到 1000 个笔画,笔画数越多,细节的恢复越好。
比较有趣的是,我们还可以设计不同形状的笔画来得到十分有趣的结果,比如限制 AI 只能画圆,或者只能画三角形等。

相关工作
有一个类似的任务叫 stroke-based rendering,大多数解法是每个笔画基于贪心选择,或者使用大量的搜索等,最后效果也很棒,参见 Aaron Hertzmann 的一些文章,图形学方向也有不少工作研究了笔画的设计,动画生成等。
与我们类似的工作有 SPIRAL,这也是我们文中对比的。BMVC 2018 的 Doodle - SDQ 用 DQN 来画简笔画 ,ICLR 2019 的 StrokeNet 提出了类似的笔画渲染器。还有早一些的 Sketch-RNN 系列工作。用神经网络建模绘画的方法有点像 NIPS 2018 的 World Models,David Ha 还发推宣传了我们的 AI。
总结
用深度强化学习的方法做了一个看起来效果还不错的 AI,仅需要修改最大笔画数,就可以适于不同到数据集,以后仗着它街头卖艺,希望大家能够喜欢。我们尽量让这套方法看起来简洁干净,但难免还有许多缺点,欢迎大家提建议。
具体算法细节可以看我们的 Arxiv,其中还有另外一些对比实验,和形式化的定义推导等。
最后推荐一下我们的ICCV2019论文,解读及代码汇总开源项目:
https://github.com/extreme-assistant/iccv2019
欢迎Star哦~
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得




