
从图嵌入算法到图神经网络
作者 | luv_dusk
来源 | CSDN
引言
图
相关概念
路径相关算法
图嵌入算法
常见概念
演变历程
图卷积网络
GNN
GraphSAGE
Spectral CNN
ChebNet
其他
图注意力网络
图自编码器
图生成网络
图时空网络
总结
前沿探索

引言
图
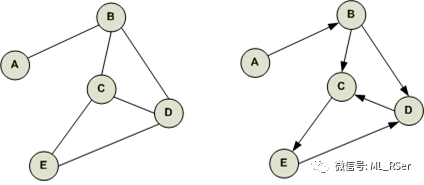
图 (Graph) 是最基础的几种计算机数据结构之一,由若干个节点 (Node, or Vertex) 构成;节点与节点相连,构成 边 (Edge),代表了两者之间的依赖关系。根据图中边的方向,概念上可将图分为两种:有向图 (Directed Graph, or Digraph) 和 无向图 (Undirected Graph, or Undigraph),如下所示,左侧为无向图,右侧为有向图:
当边被赋予权重,则图可称为权重图 (Weighted Graph):
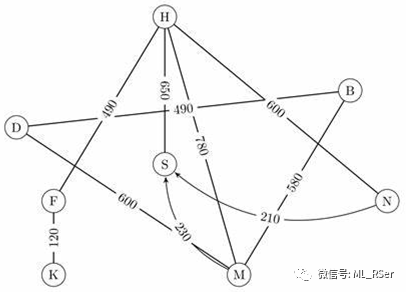
一个形象的例子是城市地图,每一个交叉路口是一个节点,道路是一条边,而权重指的则是道路的长度。但如果我们希望用权重大小代表拥挤程度,在地图上看到每条道路的拥堵情况,那么一条边显然不足以满足我们的要求。这时就引申出了多重图 (Multigraph):
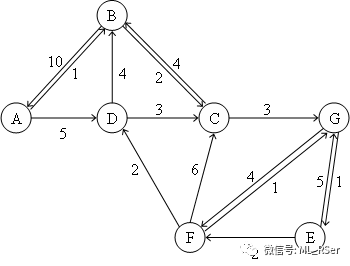
概念上,多重图必然是有向图和权重图;但需要注意的是,多重图中两个节点之间的边,既可以单向,也可以双向,i.e. 节点 A和B之间可以有两条或以上A→B的边;两条或两条以上的单向边成为平行边(Parallel Edges),而平行边的数量称为重数(Multiplicity)。
此外,还有一些其他类型图的定义,包括混合图(Mixed Graph),指的是既包含无向边也包含有向边的图;连通图(Connected Graph),指的是任意两个节点都有路径 (一个或多个边相连) 相连的无向图;强连通图(Strongly-connected Graph),指的是任意两个节点都有路径相连的有向图;循环图(Cyclic Graph),指的是存在首尾相连的路径,可以串起所有节点的图;以及最后的完全图(Complete Graph),指的是所有节点之间都有边相连的无向图。
清楚这些图的概念,是我们理解算法、熟悉算法应用场景的前提。
伴随着图一起诞生的,是与路径相关的算法,其中部分算法可以帮助我们从图中提取更多的特征信息融入到节点中,从而丰富图的架构,在图嵌入或图神经网络算法中达到更好的效果。
拓扑排序 (Topological Sorting)

应用于有向非循环图,是对图中的所有节点 Vi (i=1,...,n)进行统一排序,使得对于任意边 (Va→Vb),满足a<b。经过拓扑排序的图,能加速目标检索的效率,同时能够快速获取两个节点间的上下游位置,应用场景包括学位课程之间的先修关系、面对对象程序类之间的继承,以及工程项目之间的调度等。需要注意的是,一个有向非循环图可能存在不止一种拓扑排序的结果。算法原理在于通过迭代,将无入度的节点从原图中抽出放入排序序列中,直至所有节点全部抽出。
深度优先搜索 (DFS):
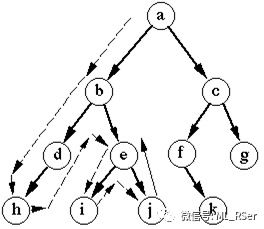
-
广度优先搜索 (BFS):
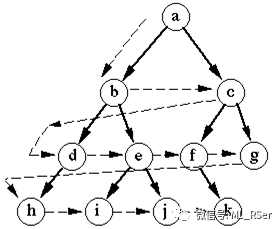
依据从源点出发,路径上的节点数量,将全图分为不同的层级,逐层向下检查。相对于深度优先搜索,广度优先搜索能够保证在边的数量上两个节点间检索到的路径最短。
Dijkstra 算法:
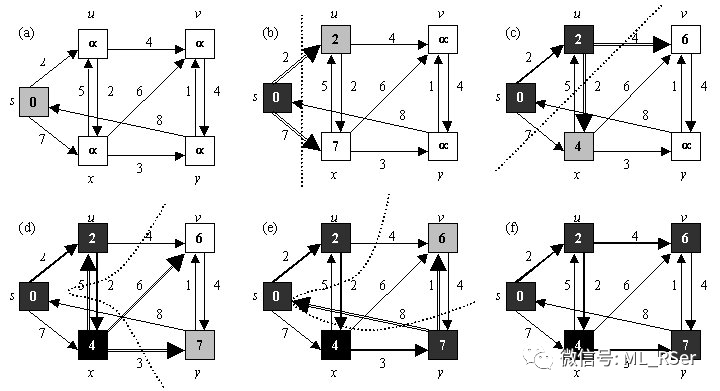
Floyd-Warshall 算法:
Prim-Jarnik 算法
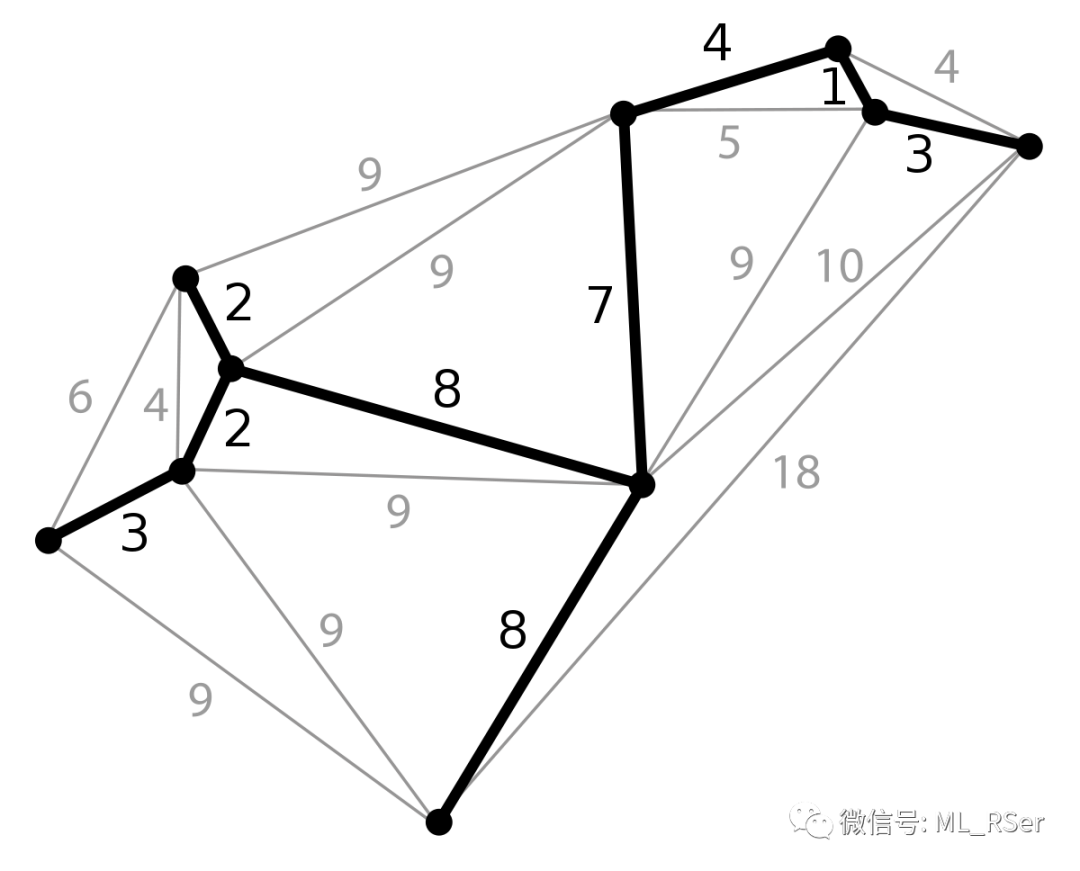
归属于最小生成树 (MST, abbr. Minimum-Spanning-Tree) 一类的算法,旨在求解连通所有节点的最短路径。由 Dijkstra 算法调整而来,以所有零入度节点作为云的初始状态,不断找寻离云内节点最近的邻点拉入到云内来,以此迭代,直至所有节点访问完毕。如果不存在零入度点,则随机挑选一个加入到云中。
3 图嵌入算法
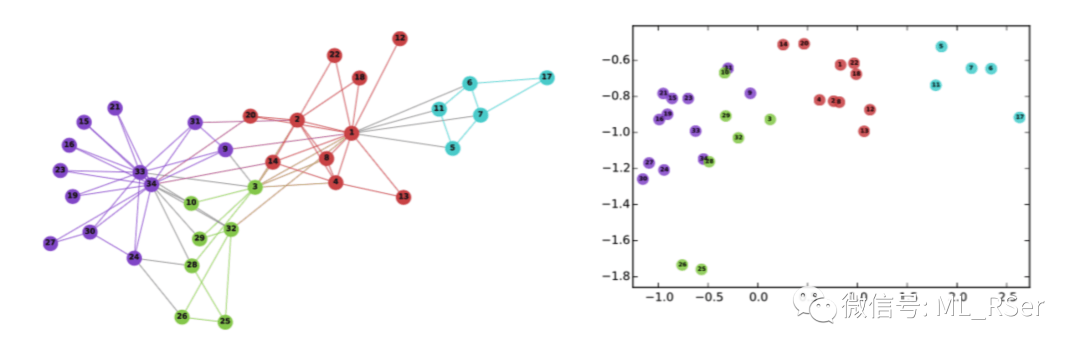
Graph Embedding Algorithms,目的在于学习图的结构或节点之间的邻接关系,对节点进行编码 (或对固有特征进行降维),将所有节点映射为等维度的向量,使其能够方便地应用于下游的聚类、分类、关联分析或可视化任务。因此,在实际应用中,图嵌入属于预处理工作,绝大多数图嵌入算法皆为无监督学习算法。
图(Graph):G(V,E)G(V,E)G(V,E)
节点(Node, or Vertex):V={v1,...,vn},包含全部节点
度(Degree):D={deg1,...,degn}包含每个节点的入度数量
边(Edge):E={eij}ni,j=1,包含所有的边;如果边是双向的,则分别表达为两条,e.g. vi↔vj 关系将对应 eij 与 eji ;如果边 vi→vj 不存在,则不会出现在 E 里面
邻点(Neighbors):N(vi),包含节点 vi的所有邻点
邻接矩阵(Adjacency Matrix):A={wij∣wij≥0}ni,j=1∈Rn×n ,记录图中边的权重信息;对于无向图,wij=wji;要求所有的边权重不得小于 0;对于不相邻的节点,wij=wji=0
一阶相似度(First-order Proximity):边的权重 wij ,代表两个节点的直接依赖关系
二阶相似度(Second-order Proximity):对于节点 vi和 vj,从邻接矩阵分别获取相应的一阶相似性wi=[wi1,...,win], sj=[wj1,...,wjn];wi与 wj的相似度即为二阶相似度,代表两个节点的邻居相似性
图嵌入(Graph Embedding):映射关系 f:vi→zi∈Rd,∀i∈[1,n],∀i∈[1,n],d 为超参数,决定最终的编码长度
特征表示(Feature Representation):Xi∈Rd0,对节点 vi的固有特征 (不包含边及其他节点信息) 进行简单编码后形成的向量,因此又称为特征向量
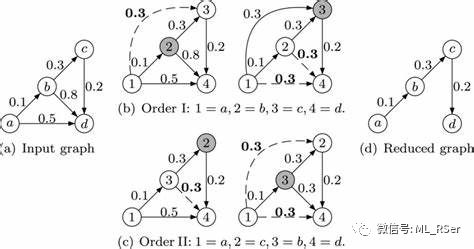
图嵌入算法初步诞生于21世纪初,彼时的模型将更多的焦点放在降维上,嵌入的同时使得相邻的节点在最终的向量空间上更为接近,代表性的包括 Locally Linear Embedding (2000) 和 Laplacian Eigenmaps (2001) ,这一类算法充分利用所有的样本间权重,时间复杂度通常较高,最高可达 O(n^2),因此并不适合大规模图数据。2010 年以后,新诞生的图嵌入算法逐渐在时间复杂度上得到优化,转而应对现实生活中广泛存在的特征稀疏性问题,这其中的翘楚便是 Graph Factorization (2013),该算法旨在于邻接矩阵以及正则项之间寻求一个平衡点,使得生成的向量保留邻接矩阵的绝大多数信息;LINE (2015) 将该思想延续下去,并努力在嵌入向量中维持节点的一阶和二阶相似度;HOPE (2016) 更是引入了更高阶的相似度矩阵,通过广义奇异值分解保留高阶相似性。以上所有算法皆可归类于矩阵分解,又称为因子分解,其中心思想在于生成相似度矩阵,通过数学方法将矩阵中包含的邻接信息融入节点向量中。
另一个知名的流派是基于随机游走,以 DeepWalk (2014) 和 node2vec (2016) 作为代表。前者在节点的上下游随机走动,生成长度为 2k+1 的等长序列,作为节点的邻接特征导入 skip-gram 模型训练;后者在前者的基础上对随机游走在 DFS 和 BFS 的方向上施加权重,使生成的序列更为真实地体现节点的结构信息。
在这之后,图嵌入算法逐渐过渡到神经网络时代,涌现出一大批优质的图神经网络模型,包括 SDNE (2016) 与 GraphSAGE (2017) 等等,在工业界大放异彩。从此,基于神经网络的图嵌入算法不再仅仅局限于节点的邻接信息,而开始将节点本身的特征纳入模型考量,并逐渐从静态的直推式 (transductive) 学习向动态的归纳式 (inductive) 学习演变,无论是拟合能力还是泛化能力,都大大提升;部分图神经网络直接针对下游任务进行建模,已不再属于图嵌入的范畴。依据 Wu et. al (2019) 的定义,图神经网络可分为五大类:
图卷积网络(Graph Convolution Networks):简称为 GCN,是目前最主流的图神经网络算法,其余四种图神经网络皆由 GCN 演化而来。依据建模过程中是否应用到傅里叶变换,可将其分为基于谱 (Spectral-based) 和基于空间 (Spatial-based) 两个流派。
图注意力网络(Graph Attention Networks):引入注意力机制,将图网络整合为端到端的模型;具体的做法,是在 GCN 的聚合函数中加入可训练的权重参数,使得训练后的模型将更多的重心放在关键的邻点上。
图自编码器(Graph Auto-encoders):由一个编码器 (encoder) 和一个解码器 (decorder) 构成;在应对无固有特征的图时,编码器对邻接矩阵进行一定的预处理,包括融入更丰富的邻接信息 (e.g. 高阶相似度) 或是将邻接矩阵输入一套神经网络;在应对包含固有特征的图时,则直接使用 GCN 作为编码器对邻接矩阵进行编码;解码器对编码结果进行后续处理获得一阶及二阶相似度,通过计算损失函数对模型参数进行更新。
图生成网络(Graph Generative Networks):2018 年以后出现的新的研究方向,目的是在图的节点和边经验分布的基础上,生成新的图,进行对抗式训练。
图时空网络(Graph Spatial-Temporal Network):旨在于时空图中学习模式 (pattern),应用在分类或是对未来特征的预测。
GNNPapers(https://github.com/thunlp/GNNPapers)详细列示了图神经网络诞生以来里程碑式的优秀模型,以及其在具体场景中的应用。
图卷积网络
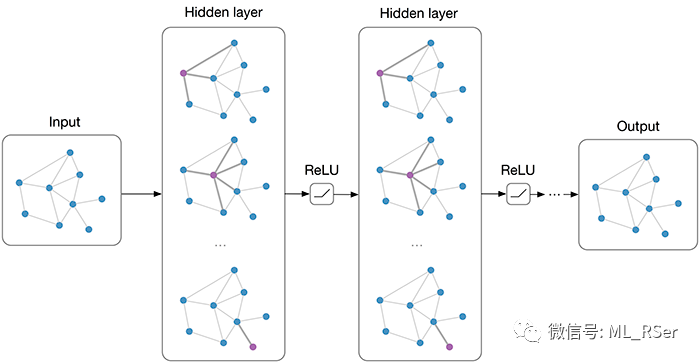
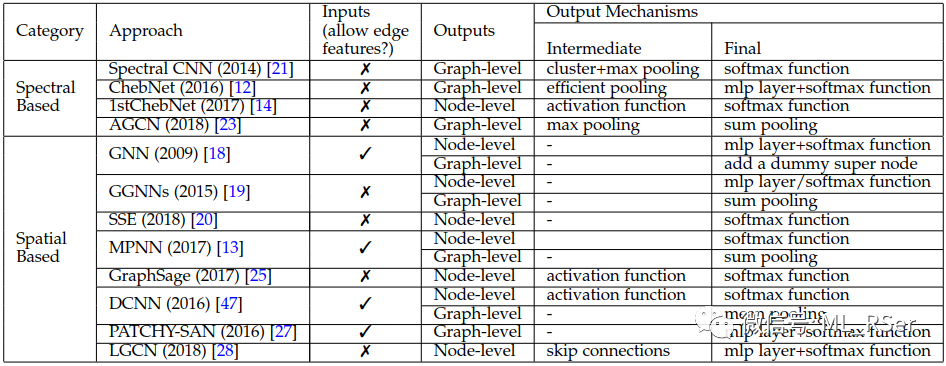
Graph Convolution Networks。在节点嵌入这一下游任务上,基于空间的 GCNs 从彼时大热的卷积神经网络中汲取思想,直接在原图的拓扑序列上进行卷积操作;而考虑到图结构的不稳定性,基于谱的 GCNs 则将所有节点映射到傅里叶域后进行卷积乘积,再经由傅里叶逆变换得到空间域下的嵌入向量。以下是 Wu et. al (2019) 对近年来图卷积网络的总结:
地址:https://ieeexplore.ieee.org/document/4700287
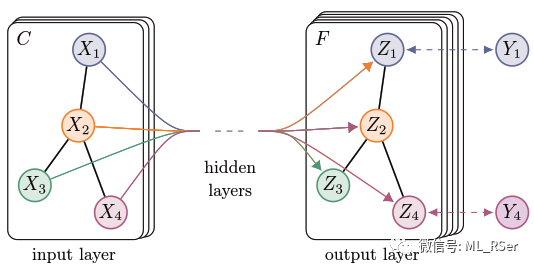
这篇论文首次提出图神经网络 (Graph Neural Network) 的概念,并将模型设计为有目的的监督学习模型,分为转换 (Transition) 和 输出 (Output) 两个部分。转换部分为每一个节点提取邻点信息,生成向量表示的 状态 (state);输出则将该状态映射至等维的向量表示,通过 softmax 归一化进行多分类预测。相关公式如下:
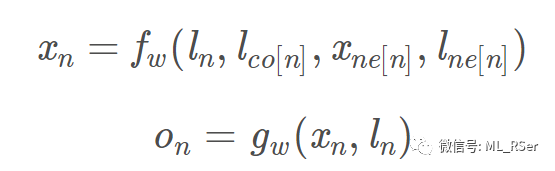
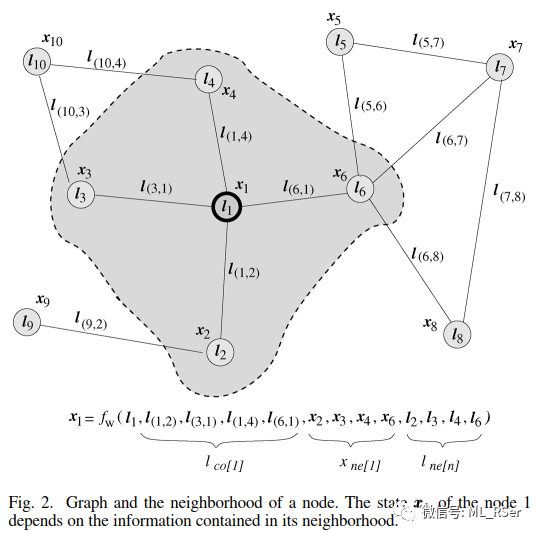
其中 f 和 g皆为可训练的全连接层,




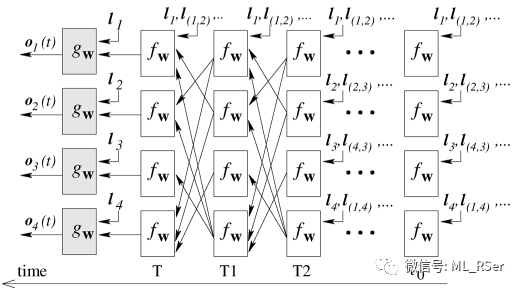
该模型除了可用于节点级别的分类,同样可用于图的级别,只需要为每张输入的图添加一个代表全局的特殊节点即可。由于模型应用到了在节点级别进行邻点采样作为输入的思想,与后来的图卷积神经网络不谋而合,论文作者虽没有自行提出卷积的概念,但本篇论文后来被认为是第一个图卷积网络的提出者。模型采用顺时针的方式为每个节点提取固定长度的邻点列表,对相对位置上空缺的邻点采取统一的无意义填充策略;这样的做法将算法的应用场景限制在了 2D 空间,且需要使用者进行更为繁琐的数据预处理,因而成为饱受诟病的之处,也为后续优化指引了方向。
论文链接:https://arxiv.org/abs/1706.02216
初代 GNN 中邻点采样的思想一直保留了下来,但 GraphSAGE 并不将采样信息局限在节点的拓扑结构里,而是使用节点的固有特征取而代之,对造成庞大参数量的扩散机制也选择了摒弃处理。根据下游任务的不同,GraphSAGE 采用不同的训练策略:应用于图嵌入时,使用负采样技术计算二阶相似度实现参数收敛;应用于分类任务时,使用 softmax 进行有监督学习。其中,无监督学习的表达式如下:
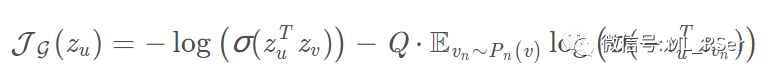
模型的特别之处,在于每一次迭代时,都重新对邻点进行采样,前馈公式如下:
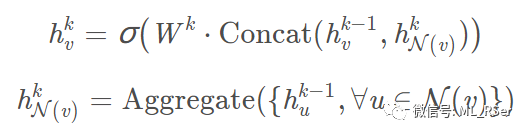
 为前馈层输出的隐藏向量,无监督学习使用最后一层计算损失函数。
为前馈层输出的隐藏向量,无监督学习使用最后一层计算损失函数。
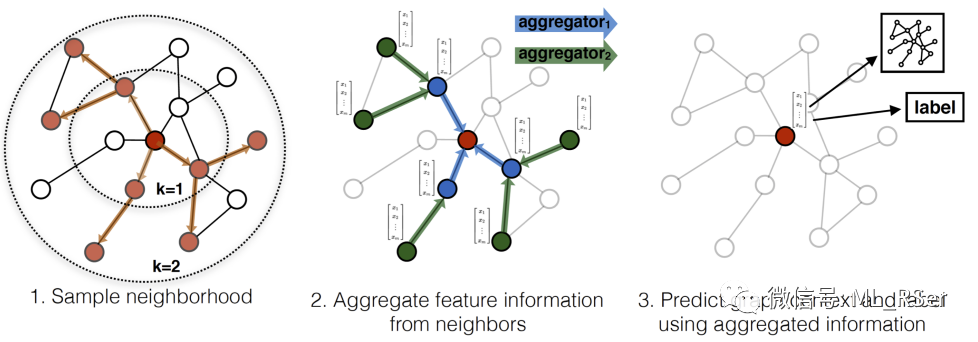
邻点采样的方法为设置固定的窗口大小,不足或过剩都采用随机的方式进行选取;采样完毕后使用聚合函数将邻点的隐藏向量聚合为一个等长的向量表示。论文中提出了三种聚合策略:
均值聚合 (MeanAggregator):直接对所有邻点 (包括自身) 的隐藏向量求均值;
LSTM 聚合 (LSTMAggregator):利用 LSTM 在时序信息处理上的优势,将采样得到的邻点序列打乱后依次输入 LSTM 中,取隐藏状态与节点本身的隐藏向量进行纵向合并;
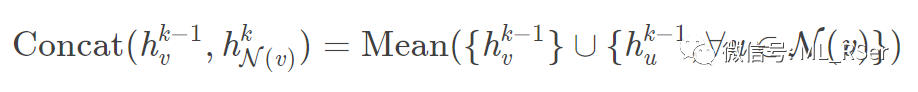
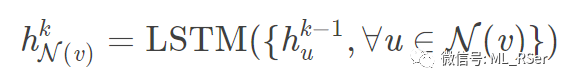
-
池化聚合 (PoolingAggregator):引入包含可训练参数的全连接层对每一个邻点的向量进行处理,将最后的输出进行最大池化;
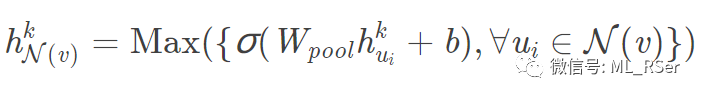
GraphSAGE 第一次提出使用 归纳式 (inductive) 的图神经网络代替 直推式 (transductive) 的旧模型,以提高其在实际应用中的效率;然而,其虽能够通过推理直接得出训练样本外节点的输出,但本质上无法在推理的同时进行参数的更新。这一问题引发了动态图的研究工作,至今依然是最为热门的方向。
论文地址:https://arxiv.org/abs/1312.6203
在有向图中,由于每个节点的邻点数目并不固定,因而直接在空间上对节点进行卷积操作难免与真实的分布形成差异,导致模型效果受阻。基于谱的图卷积网络能有效解决这一类问题。模型的思路在于仿照 CNN,分为多层进行前馈;每一层使用不同的卷积核在傅里叶域进行卷积,同时在得到空间域的表达后对其使用 max pooling 进行聚合。图的拉普拉斯矩阵可以通过两种常见的方式计算:未标准化的 L=D−W,以及标准化的
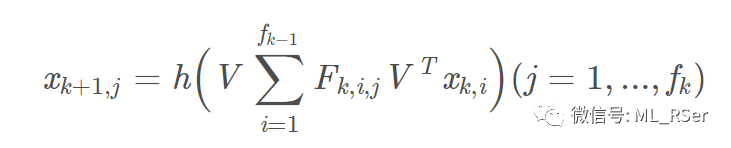
其中
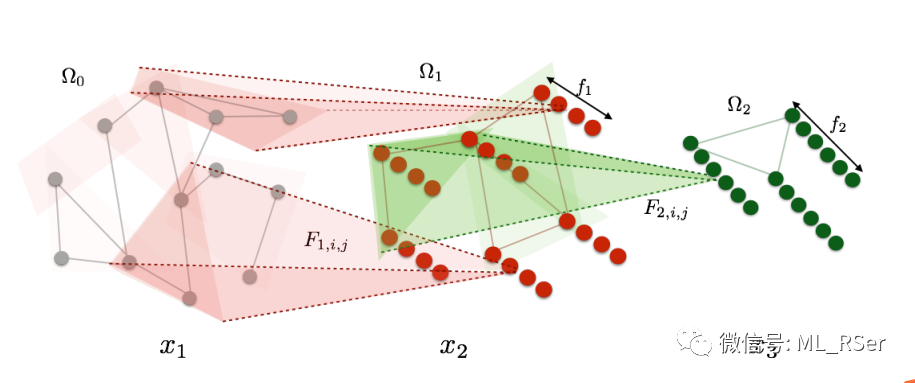
模型的优点是显而易见的,相比于基于空间的图卷积网络,无需进行邻点采样;相对于传统图模型,通过多层卷积大大提升特征提取能力。缺点是谱卷积在计算过程中需要对图的拉普拉斯矩阵进行特征分解,时间复杂度最高可达 
论文链接:https://arxiv.org/abs/1609.02907
泛化至节点的分类和嵌入任务上,该论文提出的半监督式 GCN 在许多下游任务榜单中实现了最优成绩,并因此迅速蹿红。卷积层的前馈公式如下:
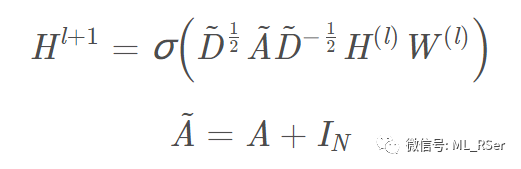
其中 A˜∈R N×N 为添加了自连接关系的邻接矩阵,D˜ 为度矩阵,W 为可训练参数,H 为卷积层的输出。为了在模型参数中引入无标签节点的信息,模型在损失函数中引入了正则项:
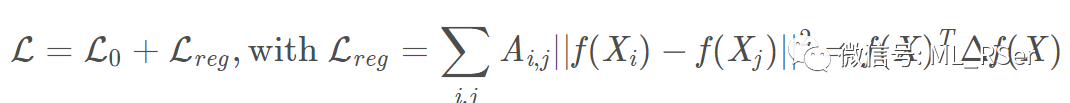
其中L0为监督学习损失,Δ=D−A 为未标准化的拉普拉斯矩阵。
模型的一大贡献在于通过设定感受野宽度为 1,并增加模型深度,来对前代基于切比雪夫多项式的谱卷积进行进一步优化;其余优点自不用再提,缺陷在于训练时并未对原始输入进行压缩,端对端地对整张图进行处理。尽管模型已进行优化,但层数的增加依然使其耗时过长。为此,后续的优化主要以加速训练为主,e.g. 在每一层进行采样计算。
其他
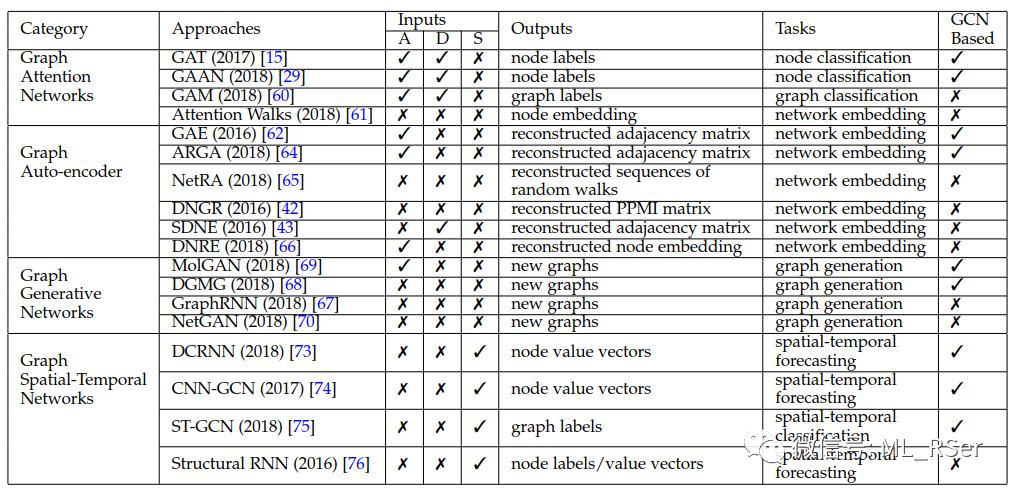
abbr. Graph Attention Networks。Attention 机制自 Google 于 2014 年提出后便广泛应用于序列建模任务中,尤其在自然语言处理领域。应用于图神经网络,Attention 机制有两种用法,第一种是用在邻点序列的生成上,第二种是用在邻点向量的聚合上;两种方法都使得模型将更多的焦点放在有重要相似度的两个邻点上。由于 Attention 机制的思想在各个领域都是共通的,在展开论文之前我们先对其进行一定的介绍。Attention 机制的核心在于三个要素:Query, Key 和 Value,公式如下,
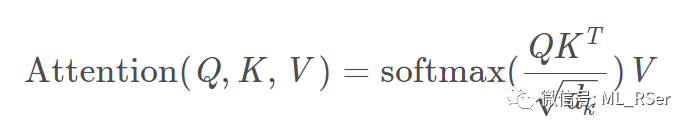
其中分母的 dk 为缩放的维度,默认为 1。通过点积计算 Query 和 Key 的相似度,将相似度结果作为权重对 Value 进行加总,这便是最常见的 Attention 形式。在此基础上进行变形,将 Query, Key, Value 经过多组线性变换后分别进行独立的 Attention 计算,对得出的结果进行合并,这样的 Attention 机制称为 Multi-Head Attention:
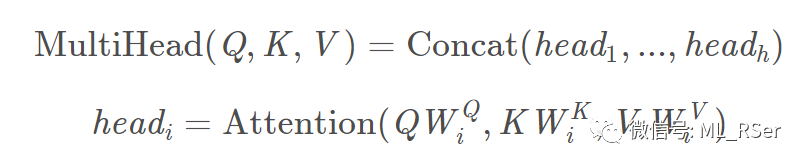

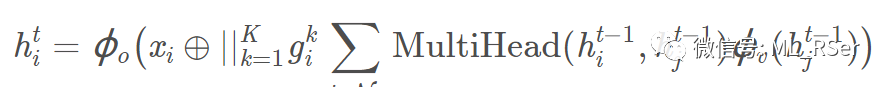
其中 ϕ为全连接前馈层;Attention Walks (2018) 将 Attention 思想应用于 DeepWalks,为共现矩阵附加权重,影响随机游走的方向。由于 Attention 组块无法自行训练,在模型流程中引入 Attention 机制后,必须将其设置为端到端的模型,因而图注意力网络的训练通常是有监督的。

abbr. Graph Auto-encoders,在 GCNs 的基础上,将任务专注于图嵌入,不再进行特定的分类任务。GAE 的共性在于使用 encoder 得到潜在向量,并以 decoder 判断潜在向量中包含的相似度信息是否与相似度矩阵保持一致。decoder 通常为全连接层;而 encoder 则以 MLP 或 GCN 为主流,一些变形包括接入 Attention 机制,或直接以 LSTM+Attention 作为编码器。以第一代图自编码器 GAE (2016) 为例,GAE 应用 GCN 作为编码器,通过重构邻接矩阵,在一阶相似度的层面拟合模型:
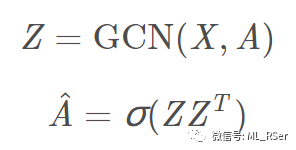
但基于一阶相似度的模型无法应对现实生活中广泛存在的高度稀疏的数据,因而 SDNE (2017) 在有监督的一阶相似度基础上,在损失函数中引入二阶相似度,以期完整地保留图的结构信息:
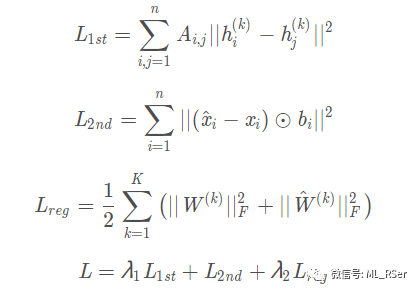
其中



 、判别器
、判别器
 ,以及奖励网络
,以及奖励网络
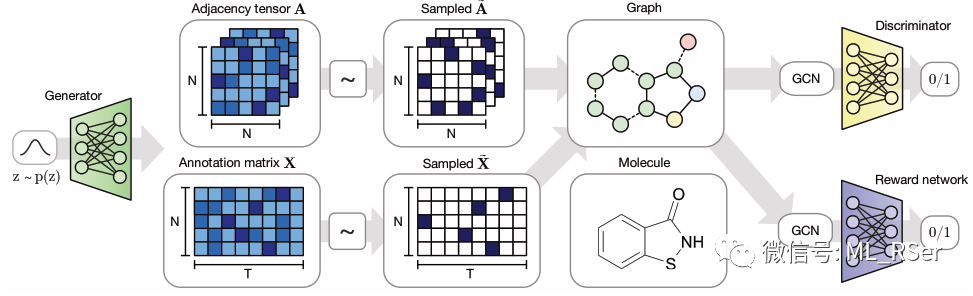
 。生成器在参数的基础上生成完整的图结构,与样本数据共同导入判别器中;判别器辨识真假,激励生成器生成符合样本图分布的新图;奖励网络在判别器运作的同时,对图的真实性和合理性进行评分,避免生成器生成不具备现实意义的图。
。生成器在参数的基础上生成完整的图结构,与样本数据共同导入判别器中;判别器辨识真假,激励生成器生成符合样本图分布的新图;奖励网络在判别器运作的同时,对图的真实性和合理性进行评分,避免生成器生成不具备现实意义的图。
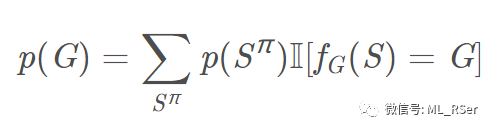
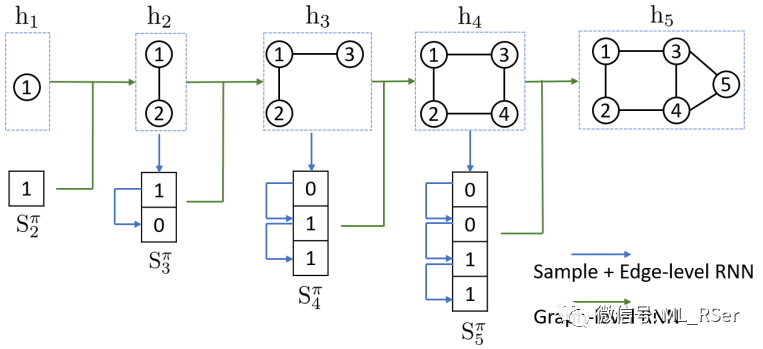
 表示从序列到图的映射关系;对于无向图,
表示从序列到图的映射关系;对于无向图,
 决定了唯一的图结构。相对于基于对抗式训练的生成式模型,GraphRNN 的优势在于能够同时保留原图信息,并高效地生成几乎任意长度的图。
决定了唯一的图结构。相对于基于对抗式训练的生成式模型,GraphRNN 的优势在于能够同时保留原图信息,并高效地生成几乎任意长度的图。
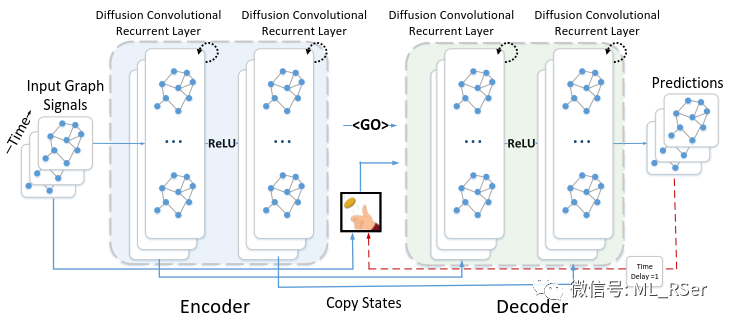
 的概率重新开始新的序列;而扩散卷积的过程中对每一条序列进行双向处理。第 ppp 个卷积核的相关表达式:
的概率重新开始新的序列;而扩散卷积的过程中对每一条序列进行双向处理。第 ppp 个卷积核的相关表达式:
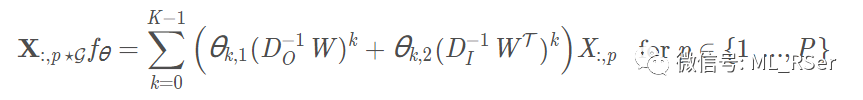
其中


总结
图神经网络相对于传统的卷积神经网络和循环神经网络的不同之处,在于其高度的可塑性和多样性。例如,有不同的卷积策略、不同的采样策略、不同的相似度矩阵/邻接矩阵计算方式,任何一个环节的改变都会对最终的模型效果产生质的区别,因而难有适用于大面积场景的高泛化性明星模型的出现。在实践中,应当依据明确的场景需求来设计网络。以下呈现笔者总结的模型择优策略,供读者参考:
-
【1】任务目的:图分类【2】、节点分类【3】、节点嵌入【4】、关系预测【15】 -
【2】数据规模:大型【9】、小型【10】 -
【3】数据规模:大型【5】、小型【7】 -
【4】使用邻接矩阵或是使用节点的固有特征:邻接矩阵【14】、节点特征【13】
【5】使用邻接矩阵或是使用节点的固有特征:邻接矩阵【6】、节点特征【13】 -
【6】邻接矩阵是否稀疏:是【11】、否【12】 -
【7】使用邻接矩阵或是使用节点的固有特征:邻接矩阵【8】、节点特征【13】 -
【8】使用能进行节点级别分类任务的 <基于谱的图卷积网络>, e.g. 1stChebNet -
【9】使用能进行图级别分类任务的 <基于空间的图卷积网络>,e.g. PATCHY-SAN, DCNN -
【10】使用能进行图级别分类任务的 <基于谱的图卷积网络>,e.g. Spectral CNN, ChebNet【3】数据规模:大型【5】、小型【7】 -
【11】使用 SDNE 等高效应对稀疏数据的 <基于空间的图自编码器> 对节点进行编码后进入【13】 -
【12】使用能进行节点级别分类任务的 <基于空间的图卷积网络>,e.g. DCNN -
【13】使用 GraphSAGE -
【14】数据规模:大型【15】、小型【16】 -
【15】使用 SDNE -
【16】使用 <传统图嵌入算法>,e.g. HOPE, node2vec
出于 GraphSAGE 和 SDNE 的一些优秀特性,笔者在部分场景里优先推荐使用;此处没有提到图注意力网络,是由于注意力机制作为一种建模思想,几乎可以应用于任何以分类作为下游任务的图神经网络,而并非现在既有的应用了注意力机制的示范模型;没有提到图生成网络和图时空网络是由于其应用场景较为局限,目的也更为明确。
前沿探索
本文呈现的皆为 2018 年及以前,经受住实践考验的经典图神经网络。依据 2019 年以后发布的论文,前沿研究主要关注以下几个方面:
动态图 (dynamic graph):目前绝大多数图嵌入算法和图神经网络都是静态的、直推式的,当我们引入新的节点,希望预测节点的分类或为其进行嵌入时,e.g. 新注册用户的加入,需要将整张图重新进行训练,这无疑相当低效。针对动态图的研究期望能解决这一类问题。
异质图 (heterogeneous graph):将图神经网络应用在知识图谱等领域时需要面对的问题 —— 节点和边可能不只一类。如何为这样的图进行节点嵌入,HAN (2019) 提供的解决方案是将隐藏向量的聚合分为两步进行。
边的特征:传统图嵌入算法仅利用了边的权重信息,GraphSAGE 引入了节点的固定特征,下一步有研究者将注意力放在如何将前两者与边的特征结合上。
References
[1] Palash Goyal, E. F. (2017). Graph Embedding Techniques, Applications, and Performance: A Survey. Retrieved from https://arxiv.org/abs/1705.02801 [2] Zonghan Wu, S. P. (2019). A Comprehensive Survey on Graph Neural Networks. Retrieved from https://arxiv.org/abs/1901.00596

推荐阅读

登录查看更多
相关内容
专知会员服务
46+阅读 · 2020年2月23日
Arxiv
8+阅读 · 2020年4月14日
Arxiv
4+阅读 · 2019年11月5日
Arxiv
14+阅读 · 2019年3月5日



相关VIP内容
专知会员服务
46+阅读 · 2020年2月23日
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月14日
Arxiv
4+阅读 · 2019年11月5日
Arxiv
14+阅读 · 2019年3月5日