【智能自动化学科前沿讲习班第1期】University of Central Florida 的Guojun Qi:LS-GAN

整理:张慧
GAN前传
GAN是一种通过对输入的随机噪声z (比如高斯分布或者均匀分布),运用一个深度网络函数G(z),从而希望得到一个新样本,该样本的分布,我们希望能够尽可能和真实数据的分布一致(比如图像、视频等)。
在证明GAN能够做得拟合真实分布时,Goodfellow做了一个很大胆的假设:用来评估样本真实度的Discriminator网络(下文称D-网络)具有无限的建模能力,也就是说不管真实样本和生成的样本有多复杂,D-网络都能把他们区分开。这个假设呢,也叫做非参数假设。
当然,对于深度网络来说,只要不断的加高加深。
但是,正如WGAN的作者所指出的,一旦真实样本和生成样本之间重叠可以忽略不计(这非常可能发生,特别当这两个分布是低维流型的时候),而又由于D-网络具有非常强大的无限区分能力,可以完美地分割这两个无重叠的分布,这时候,经典GAN用来优化其生成网络(下文称G-网络)的目标函数--JS散度-- 就会变成一个常数!
我们知道,深度学习算法,基本都是用梯度下降法来优化网络的。一旦优化目标为常数,其梯度就会消失,也就会使得无法对G-网络进行持续的更新,从而这个训练过程就停止了。这个难题一直以来都困扰着GAN的训练,称为梯度消失问题。
为解决这个问题,WGAN提出了取代JS散度的Earth-Mover(EM)来度量真实和生成样本密度之间的距离。该距离的特点就是,即便用具有无限能力的D-网络完美分割真实样本和生成样本,这个距离也不会退化成常数,仍然可以提供梯度来优化G-网络。不过WGAN的作者给出的是定性的解释,缺少定量分析,这个我们在后面解释LS-GAN时会有更多的分析。
现在,我们把这个WGAN的优化目标记下来,下文我们会把它与本文的主角LS-GAN 做一番比较。
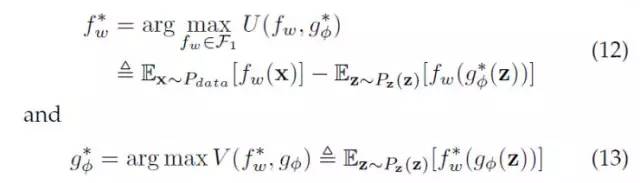
这里 f-函数和 g-函数 分别是WGAN的批评函数(critics)和对应的G-网络。批评函数是WGAN里的一个概念,对应GAN里的Discriminator。该数值越高,代表对应的样本真实度越大。
由于假设中的无限建模能力,使得D-网络可以完美分开真实样本和生成样本,进而JS散度为常数;而WGAN换JS散度为EM距离,解决了优化目标的梯度为零的问题。
但是WGAN在上面的优化目标(12)里,有个对f-函数的限定:它被限定到所谓的Lipschitz连续的函数上的。那这个会不会影响到上面对模型无限建模能力的假设呢?
其实,这个对f-函数的Lipschitz连续假设,就是沟通LS-GAN和WGAN的关键,因为LS-GAN就是为了限制GAN的无限建模能力而提出的。
仔细研究Goodfellow对经典GAN的证明后,可以发现,之所以有这种无限建模能力假设,一个根本原因就是GAN没有对其建模的对象--真实样本的分布--做任何限定。
换言之,GAN设定了一个及其有野心的目标:就是希望能够对各种可能的真实分布都适用。结果呢,就是它的优化目标JS散度,在真实和生成样本可分时,变得不连续,才使得WGAN有了上场的机会,用EM距离取而代之。
所以,某种意义上,无限建模能力正是一切麻烦的来源。LS-GAN就是希望去掉这个麻烦,取而代之以“按需分配”建模能力。
LS-GAN
下面我们从算法,理论和实验这三个方面对LS-GAN模型进行一个介绍。

(1)算法分析
首先我们看看LS-GAN的真容:
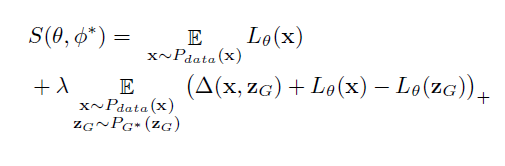
这个是用来学习损失函数的目标函数。我们将通过最小化这个目标来得到一个“损失函数" (下文称之为L-函数)。L-函数在真实样本上越小越好,在生成的样本上越大越好。
另外,对应的G-网络,通过最小化下面这个目标实现:
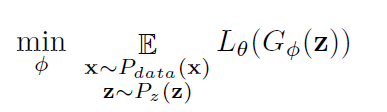
这里注意到,在公式S(θ,φ*)中,对L-函数的学习目标 S中的第二项,它是以真实样本x和生成样本的一个度量△(x,zG)为各自L-函数的目标间隔把x和zG分开。
这有一个很大的好处:如果生成的样本和真实样本已经很接近,我们就不必要求他们的L-函数非得有个固定间隔,因为,这个时候生成的样本已经非常好了,接近或者达到了真实样本水平。
这样呢,LS-GAN就可以集中力量提高那些距离真实样本还很远,真实度不那么高的样本上了。这样就可以更合理使用LS-GAN的建模能力。在后面我们一旦限定了建模能力后,也不用担心模型的生成能力有损失了。
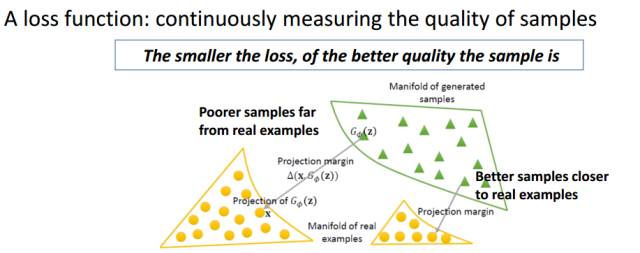
上图就是对LS-GAN这种建模能力的图示。

(2)理论证明
有了上面的准备,我们先把LS-GAN要建模的样本分布限定在Lipschitz 密度上,即如下的一个假设:
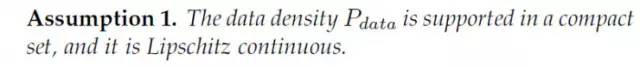
Lipschitz密度就是要求真实的密度分布不能变化的太快。密度的变化随着样本的变化不能无限地大,要有个度。不过这个度可以非常非常地大,只要不是无限大就好。
好了,这个条件还是很弱地,大部分分布都是满足的。比如,你把一个图像调得稍微亮一些,它看上去仍然应该是真实的图像,在真实图像中的密度在Lipschitz假设下不应该会有突然地、剧烈地变化。
然后,有了这个假设,就能证明LS-GAN,当把L-函数限定在Lipschitz连续的函数类上,它得到的生成样本的分布和真实样本是完全一致!
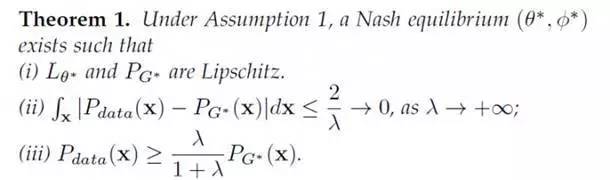
前面我们说了,经典GAN事实上对它生成的样本密度没有做任何假设,结果就是必须给D-网络引入无限建模能力,正是这种能力,在完美分割真实和生成样本,导致了梯度消失,结果是引出了WGAN。
现在,我们把LS-GAN限定在Lipschitz密度上,同时限制住L-函数的建模能力到Lipschitz连续的函数类上,从而证明了LS-GAN得到的生成样本密度与真实密度的一致性。
那LS-GAN和WGAN又有什么关系呢?
WGAN在学习f-函数时,也限定了其f-函数必须是Lipschitz连续的。不过WGAN导出这个的原因是EM距离不容易直接优化,而用它的共轭函数作为目标代替之。
也就是说,这个对f-函数的Lipschitz连续性的约束,完全是“技术”上的考虑,没有太多物理意义上的考量。
而且,WGAN的作者也没有在他们的论文中证明:WGAN得到的生成样本分布,是和真实数据的分布是一致的。如下所示:
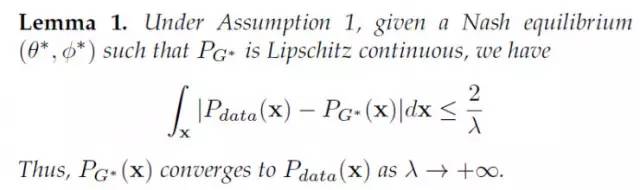
换言之: WGAN在对f-函数做出Lipschitz连续的约束后,其实也是将生成样本的密度假设为Lipschiz 密度。这点上,和LS-GAN是一致的!两者都是建立在Lipschitz密度基础上的生成对抗网络。
我们来仔细看看LS-GAN和WGAN对L-函数和f-函数的学习目标:
LS-GAN:
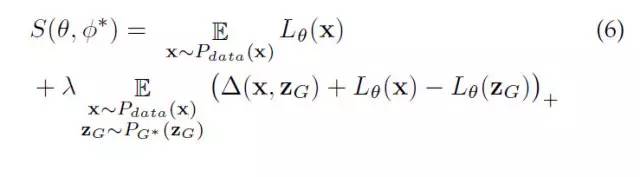
WGAN:
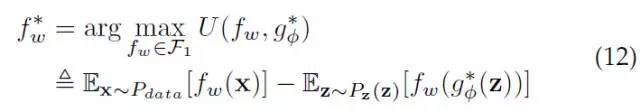
形式上来看,LS-GAN和WGAN也有很大区别。WGAN是通过最大化f-函数在真实样本和生成样本上的期望之差实现学习的,这种意义上,它可以看做是一种使用“一阶统计量"的方法。
LS-GAN则不同。观察LS-GAN优化目标的第二项,由于非线性的函数的存在,使得我们无法把L-函数分别与期望结合,像WGAN那样得到一阶统计量。因为如此,才使得LS-GAN与WGAN非常不同。
LS-GAN可以看成是使用成对的 “真实/生成样本对”上的统计量来学习f-函数。这点迫使真实样本和生成样本必须相互配合,从而更高效的学习LS-GAN。
如上文所述,这种配合,使得LS-GAN能够按需分配其建模能力:当一个生成样本非常接近某个真实样本时,LS-GAN就不会在过度地最大化他们之间L-函数的差值,从而LS-GAN可以更有效地集中优化那些距离真实样本还非常远地生成样本,提高LS-GAN模型优化和使用效率。
梯度消失问题
那LS-GAN是否也能解决经典GAN中的梯度消失问题呢?即当它的L-函数被充分训练后,是否对应的G-网络训练目标仍然可以提供足够的梯度信息呢?
在WGAN里,其作者给出G-网络的训练梯度,并证明了这种梯度在对应的f-函数被充分优化后,仍然存在。
不过,仅仅梯度存在这点并不能保证WGAN可以提供足够的梯度信息训练 G-网络。为了说明WGAN可以解决梯度消失问题,WGAN的作者宣称:“G-网络的训练目标函数”在对其网络链接权重做限定后, 是接近或者最多线性的。这样就可以避免训练目标函数饱和,从而保证其能够提供充足的梯度训练G-网络。
好了,问题的关键时为什么G-网络的训练目标函数是接近或者最多线性的,这点WGAN里并没有给出定量的分析,而只有大致的定性描述,这里我们引用如下:


现在,让我们回到LS-GAN,看看如何给出一直定量的形式化的分析。在LS-GAN里,我们给出了最优的L-函数的一种非参数化的解:
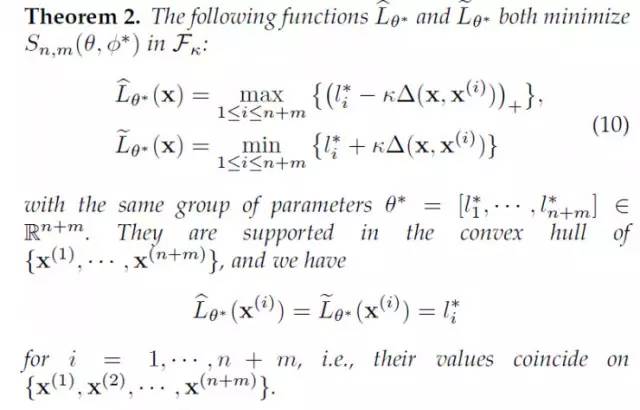
这个定理比较长,简单的来说,就是所有的最优 L-GAN的解,都是在两个分段线性的上界和下界L-函数之间。如下图所示:
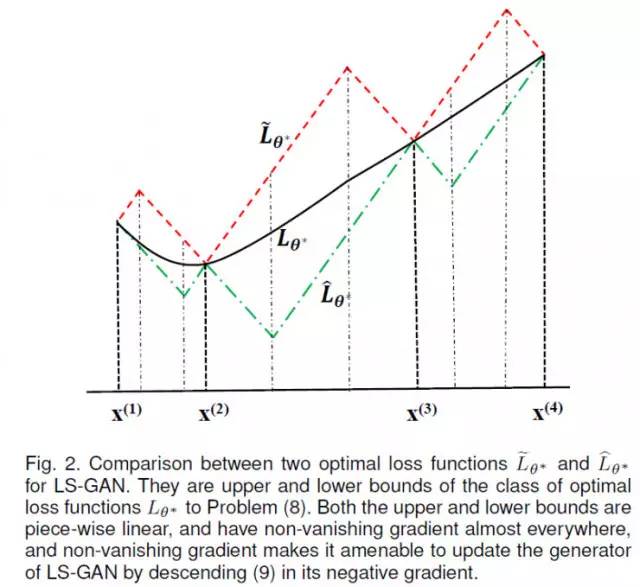
红线是上界,绿线是下界。任何解出来最优L-函数,一定在这两个分段线性的上下界之间,包括用一个深度网络解出来L-函数。
也就是说,LS-GAN解出的结果,只要上下界不饱和,它得到的L-函数就不会饱和。而这里看到这个L-函数的上下界是分段线性的。这种分段线性的函数几乎处处存在非消失的梯度,这样适当地控制L-函数的学习过程,在这两个上下界之间地最优L-函数也不会出现饱和现象。
(3)实验结果
最后,我们看看LS-GAN合成图像的例子,以及和DCGAN的对比。
看看在CelebA上的结果:

如果我们把DCGAN和LS-GAN中Batch Normalization 层都去掉,我们可以看到DCGAN模型崩溃,而LS-GAN仍然可以得到非常好的合成效果:
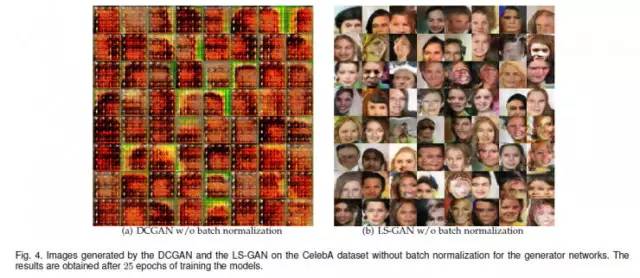
不仅如此,LS-GAN在去掉batch normalization后,如上图(b)所示,也没有看到任何mode collapse现象。
对LS-GAN进行有监督和半监督的推广
LS-GAN和GAN一样,本身是一种无监督的学习算法。LS-GAN的另一个突出优点是,通过定义适当的损失函数,它可以非常容易的推广到有监督和半监督的学习问题。
比如,我们可以定义一个有条件的损失函数,这个条件可以是输入样本的类别。当类别和样本一致的时候,这个损失函数会比类别不一致的时候小。
于是,我们可以得到如下的Conditional LS-GAN (CLS-GAN)

我们可以看看在MNIST, CIFAR-10和SVHN上,针对不同类别给出的合成图像的效果:

半监督的训练是需要使用完全标注的训练数据集。当已标注的数据样本比较有限时,会使得训练相应模型比较困难。
进一步,我们可以把CLS-GAN推广到半监督的情形,即把已标记数据和未标记数据联合起来使用,利用未标记数据提供的相关分布信息来指导数据的分类。
为此,我们定义一个特别的半监督的损失函数:
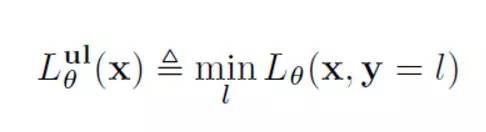
对给定样本x,我们不知道它的具体类别,所以我们在所有可能的类别上对损失函数取最小,作为对该样本真实类别的一个最佳的猜测。
这样,我们可以相应的推广CLS-GAN,得到如下的训练目标 最优化损失函数
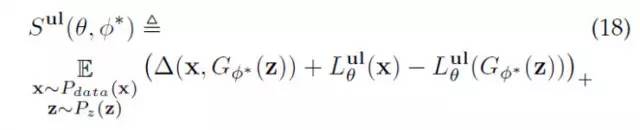
该训练目标可以通过挖掘各个类别中可能的变化,帮助CLS-GAN模型合成某类中的更多的“新”的样本,来丰富训练数据集。这样,即便标注的数据集比较有限,通过那些合成出来已标记数据,也可以有效的训练模型。
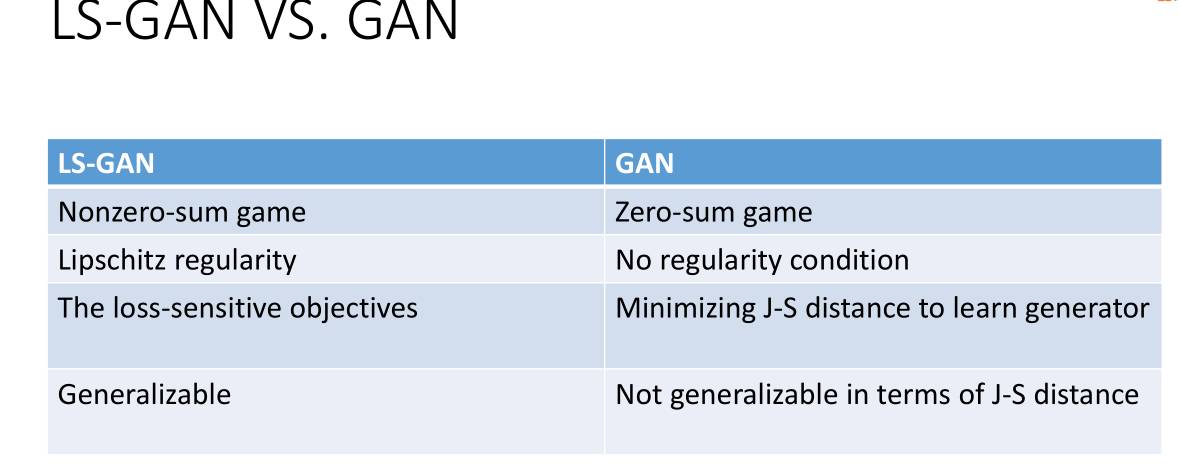
总结一下,LS-GAN和经典的GAN 的不同点和相同点。
不同点:
经典的GAN是一个零和的游戏,而LSGAN 是非零和的游戏,即用来训练L和G的函数不是零和的关系。另一方面,经典的GAN 在最小化Jensen-shannon散度意义下是不具有正则化这样的性质的,即没有正则化条件的,而LS-GAN是基于lipschitz正则化条件的。在这方面经典的GAN 是通过最小化J-S散度来学习样本生成器。而LSGAN 是通过最小化loss sensitive目标函数,最后,在最小化J-S散度意义下GAN 是不具有泛化性的,而LS-GAN在定义的这种目标函数下是具有泛化性的。