PluggableDevice 已完成架构,解决加速器与 TensorFlow 无缝集成难题


发布人:Penporn Koanantakool 和 Pankaj Kanwar
随着 ML 生态系统中加速器 (GPU、TPU) 数量的激增,我们迫切需要将新加速器与 TensorFlow 进行无缝集成。在本文中,我们将介绍 PluggableDevice 架构,此架构可提供一种通过 TensorFlow 注册设备的插件机制,且无需更改 TensorFlow 代码。
PluggableDevice
https://github.com/tensorflow/community/blob/master/rfcs/20200624-pluggable-device-for-tensorflow.md
PluggableDevice 架构已在 TensorFlow 社区内完成了协同设计和开发。此架构利用了我们在 Modular TensorFlow 方面取得的进展,并且使用 StreamExecutor C API 构建而成。PluggableDevice 机制在 TensorFlow 2.5 中可以使用。
Modular TensorFlow
https://github.com/tensorflow/community/pull/77
StreamExecutor C API
https://github.com/tensorflow/community/pull/257


在此之前,任何新设备的集成都需要对核心 TensorFlow 进行更改。之前无法进行扩容是因为以下几个原因:
复杂的构建依赖项和编译器工具链。尝试使用新的编译器并非易事,而且会增加产品的技术复杂性。
开发速度较慢。更改需要 TensorFlow 团队审核代码,这一过程比较耗时间。较高的技术复杂性也会增加新功能的开发和测试时间。
需要测试大量构建配置。针对特定设备进行的更改可能会影响其他设备或 TensorFlow 的其他组件。每个新设备都会成倍增加测试配置的数量。
容易损坏。由于缺少通过明确定义的 API 制定的协定,因此特定设备更容易遭到损坏。
PluggableDevice 机制无需针对特定设备对 TensorFlow 代码进行更改。该机制可以通过 C API 与 TensorFlow 二进制文件进行稳定的交流。插件开发者为插件维护单独的代码仓库和分发软件包,并负责测试他们的设备。在这种情况下,TensorFlow 的构建依赖项、工具链和测试过程都不会受到影响。集成的强度也有所提高,因为只有对 C API 或 PluggableDevice 组件的更改才会影响代码。
PluggableDevice 机制有四个主要组件:
PluggableDevice 类型:TensorFlow 中的新设备类型,允许从插件包中注册设备。在设备放置阶段,其优先级高于原生设备。
自定义算子和内核:插件通过内核和算子注册 C API 将其自己的算子和内核注册到 TensorFlow 中。
内核和算子注册 C API
https://github.com/tensorflow/community/blob/master/rfcs/20190814-kernel-and-op-registration.md
设备执行和内存管理:TensorFlow 通过 StreamExecutor C API 管理插件设备。
StreamExecutor C API
https://github.com/tensorflow/community/blob/master/rfcs/20200612-stream-executor-c-api.md
自定义计算图优化 pass:插件可以通过计算图优化 C API 注册一个自定义计算图优化 pass,而 pass 将在所有标准 Grappler 过程之后运行。
优化 C API
https://github.com/tensorflow/community/blob/master/rfcs/20201027-modular-tensorflow-graph-c-api.md
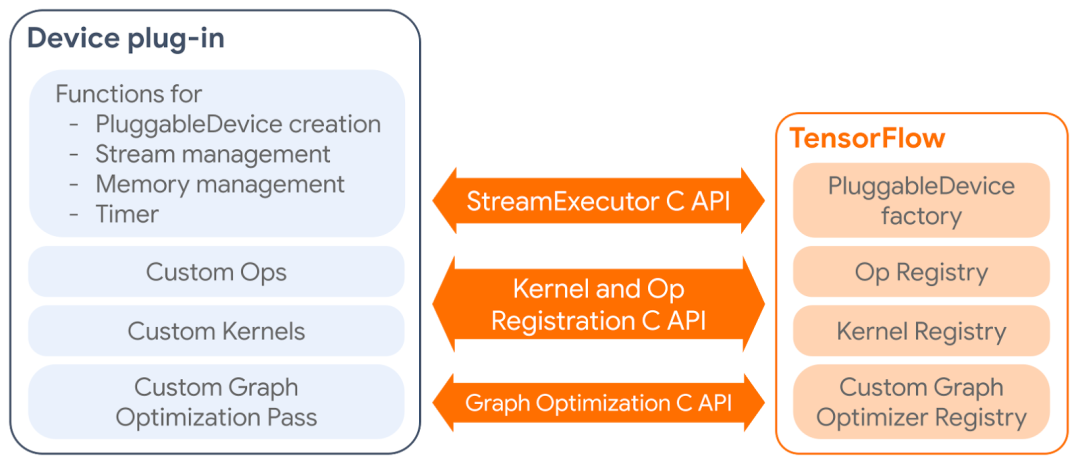
设备插件如何与 TensorFlow 进行交互
为了能够像在 TensorFlow 中使用原生设备一样使用特定设备,用户只需为该设备安装设备插件包。以下代码段展示了如何安装和使用新设备的插件,以 Awesome Processing Unit (APU) 为例。为简便起见,假设此 APU 插件只有一个 ReLU 的自定义算子。
pip install tensorflow-apu-0.0.1-cp36-cp36m-linux_x86_64.whl
…
Successfully installed tensorflow-apu-0.0.1
$ python
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf # TensorFlow registers PluggableDevices here
>>> tf.config.list_physical_devices()
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:APU:0', device_type='APU')]
>>> a = tf.random.normal(shape=[5], dtype=tf.float32) # Runs on CPU
>>> b = tf.nn.relu(a) # Runs on APU
>>> with tf.device("/APU:0"): # Users can also use 'with tf.device' syntax
... c = tf.nn.relu(a) # Runs on APU
>>> @tf.function # Defining a tf.function
... def run():
... d = tf.random.uniform(shape=[100], dtype=tf.float32) # Runs on CPU
... e = tf.nn.relu(d) # Runs on APU
>>> run() # PluggableDevices also work with tf.function and graph mode.
我们很激动地宣布,Intel 将成为我们发布 PluggableDevice 的首批合作伙伴之一。Intel 为此项目做出了重大贡献,提交了超过 3 份实现整体机制的 RFC。该公司将发布面向 TensorFlow 的 Intel 扩展程序 (ITEX) 插件包,将 Intel XPU 带入 TensorFlow 以加速 AI 工作负载。我们还希望其他合作伙伴能够对 PluggableDevice 加以利用,并发布更多插件。
我们将为有兴趣利用此基础架构的合作伙伴发布有关如何开发 PluggableDevice 插件的详细教程。若工程师对 PluggableDevice 有任何疑问,可直接在 RFC PR [1,2,3,4,5,6],或 TensorFlow 论坛中发布问题,并带上 pluggable_device 标签。
1
https://github.com/tensorflow/community/pull/257
2
https://github.com/tensorflow/community/pull/262
3
https://github.com/tensorflow/community/pull/318
4
https://github.com/tensorflow/community/pull/133
5
https://github.com/tensorflow/community/pull/387
6
https://github.com/tensorflow/community/pull/389
TensorFlow 论坛
https://discuss.tensorflow.org/

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




