龙蜥开源Plugsched:首次实现Linux kernel调度器热升级

Plugsched 是 Linux 内核调度器子系统热升级的 SDK,它可以实现在不重启系统、应用的情况下动态替换调度器子系统,毫秒级 downtime。Plugsched 可以对生产环境中的内核调度特性动态地进行增、删、改,以满足不同场景或应用的需求,且支持回滚。
基于 Plugsched 实现的调度器热升级,不修改现有内核代码,就能获得较好的可修改能力,天然支持线上的老内核版本。如果提前在内核调度器代码的关键数据结构中加入 Reserve 字段,可以额外获得修改数据结构的能力,进一步提升可修改能力。
Plugsched 开源链接:https://gitee.com/anolis/plugsched
那么 Plugsched 诞生的背景或者想要解决的问题是什么?我们认为有以下 4 点:
应用场景不同,最佳调度策略不同。 应用种类极大丰富,应用特征也是千变万化 (throughput-oriented workloads, 𝜇s-scale latency critical workloads, soft real-time, and energy efficiency requirements),使得调度策略的优化比较复杂,不存在“一劳永逸”的策略。因此,允许用户定制调度器满足不同的场景是必要的。
调度器迭代慢。 Linux 内核经过很多年的更新迭代,代码变得越来越繁重。调度器是内核最核心的子系统之一,它的结构复杂,与其它子系统紧密耦合,这使得开发和调试变得越发困难。此外,Linux 很少增加新的调度类,尤其是不太可能接受非通用或场景针对型的调度器,上游社区在调度领域发展缓慢。
内核升级困难。 调度器内嵌 (built-in)在内核中,上线调度器的优化或新特性需要升级内核版本。内核发布周期通常是数月之久,这将导致新的调度器无法及时应用在生产系统中。再者,要在集群范围升级新内核,涉及业务迁移和停机升级,对业务方来说代价昂贵。
无法升级子系统。kpatch 和 livepatch 是函数粒度的热升级方案,可修改能力较弱,不能实现复杂的逻辑改动;eBPF 技术在内核网络中广泛应用,但现在调度器还不支持 ebpf hook,将来即使支持,也只是实现局部策略的灵活修改,可修改能力同样较弱。
Plugsched 能将调度器子系统从内核中提取出来,以模块的形式对内核调度器进行热升级。通过对调度器模块的修改,能够针对不同业务定制化调度器,而且使用模块能够更敏捷的开发新特性和优化点,并且可以在不中断业务的情况下上线。
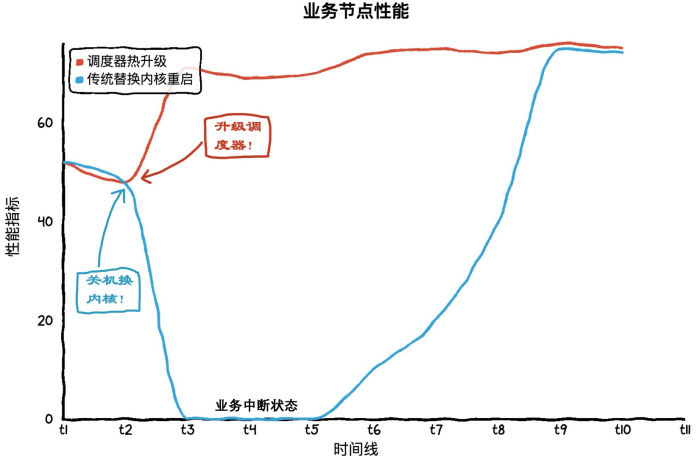
图 1 plugsched: 业务不中断
使用 plugsched 具有以下 6 大优势:
与内核发布解耦:调度器版本与内核版本解耦,不同业务可以使用不同调度策略;建立持续运维能力,加速调度问题修复、策略优化落地;提升调度领域创新空间,加快调度器技术演进和迭代
可修改能力强 :可以实现复杂的调度特性和优化策略,能人之所不能
维护简单:不修改内核代码,或少量修改内核代码,保持内核主线干净整洁;在内核代码 Tree 外独立维护非通用调度策略,采用 RPM 的形式发布和上线
简单易用:容器化的 SDK 开发环境,一键生成 RPM,开发测试简洁高效
向下兼容:支持老内核版本,使得存量业务也能及时享受新技术红利
高效的性能:毫秒级 downtime,可忽略的 overhead。
Plugsched 相比 kpatch 和 livepatch 可修改能力更强,热升级范围更广,plugsched 是子系统范围的热升级,而后者是函数级别的热升级。对于 plugsched 而言,无论是 bugfix,还是性能优化,甚至是特性的增、删、改,都可胜任。 鉴于 plugsched 较强的可修改能力,它可应用到以下场景:
快速开发、验证、上线新特性,稳定后放入内核主线
针对不同业务场景做定制优化,以 RPM 包的形式发布和维护非通用调度器特性
统一管理调度器热补丁,避免多个热补丁之间的冲突而引发故障
Group Identity 是阿里云用于混部场景的调度特性,它基于 CFS 调度器增加了一颗存储低优先级任务的红黑树,而且会对每一个 cgroup 分配一个默认优先级,用户也可自行配置其优先级,当队列中存在高优先级任务时,低优先级任务会停止运行。我们利用 plugsched 对 anck 4.19 的一个老版本内核(没有该调度特性)进行调度器热升级,并将 Group Identity 调度特性移植到生成的调度器模块中,涉及 7 个文件,2500+ 行的修改量。
安装该调度器模块后,在系统中创建两个 cpu cgroup A 和 B,并绑定同一个 CPU,分别设置最高和最低优先级,然后各自创建一个 busy loop 任务。理论上,当 A 中有任务执行时,B 中的任务会停止运行。此时用 top 工具查看该 CPU 利用率,发现只有一个利用率是 100% 的 busy loop 任务,说明模块中的 Group Identity 特性已生效;而动态卸载该模块后,出现了两个各占 50% CPU 的 busy loop 任务,说明模块已经失效。
阿里云某客户使用的旧版本内核,由于该内核调度器对 load 的统计算法不合理,导致 CPU 利用率过高,虽然修复补丁已经合入内核主线,但是新内核版本还未发布,而且业务方也不打算更换内核,因为集群中部署了大量的业务,升级内核成本较高。
除此之外,客户的内核开发人员对其混部业务场景(Group Identity 调度特性)进行了针对性的优化,想将优化内容合入内核主线。但是,阿里云内核开发人员发现,该优化内容在其它场景中有性能回退,属于非通用优化,因此不允许将优化内容合入主线。
于是,客户的内核开发人员使用 plugsched 将优化修复内容全部移植到调度器模块中,最后规模部署。该案例可以体现出 plugsched 的与内核发布解耦、定制化调度器的优势。
目前,plugsched 默认支持 Anolis OS 7(内核 ANCK-4.19 版本) 系统,其它操作系统需要调整边界配置。为了减轻搭建运行环境的复杂度,我们提供了容器镜像和 Dockerfile,开发人员不需要自己去搭建开发环境。为了方便演示,这里购买了一台阿里云 ECS(64CPU + 128GB),并安装 Anolis OS 7.9 ANCK 系统发行版,我们将演示对其内核调度器进行热升级的过程。
1、登陆云服务器后,先安装一些必要的基础软件包:
# yum install anolis-repos -y # yum install podman kernel-debuginfo-$(uname -r) kernel-devel-$(uname -r) --enablerepo=Plus-debuginfo --enablerepo=Plus -y
2、创建临时工作目录,下载系统内核的 SRPM 包:
# mkdir /tmp/work # uname -r 4.19.91-25.2.an7.x86_64 # cd /tmp/work
# wget https://mirrors.openanolis.cn/anolis/7.9/Plus/source/Packages/kernel-4.19.91-25.2.an7.src.rpm
3、启动并进入容器:
# podman run -itd --name=plugsched -v /tmp/work:/tmp/work -v /usr/src/kernels:/usr/src/kernels -v /usr/lib/debug/lib/modules:/usr/lib/debug/lib/modules docker.io/plugsched/plugsched-sdk # podman exec -it plugsched bash # cd /tmp/work
4、提取 4.19.91-25.1.al7.x86_64 内核源码:
# plugsched-cli extract_src kernel-4.19.91-25.2.an7.src.rpm ./kernel
5、进行边界划分与提取:
# plugsched-cli init 4.19.91-25.2.an7.x86_64 ./kernel ./scheduler
6、提取后的调度器模块代码在 ./scheduler/kernel/sched/mod 中,简单修改 __schedule 函数,然后编译打包成调度器 rpm 包:
diff --git a/kernel/sched/mod/core.c b/kernel/sched/mod/core.c
index f337607..88fe861 100644
--- a/kernel/sched/mod/core.c
+++ b/kernel/sched/mod/core.c
@@ -3235,6 +3235,8 @@ static void __sched notrace __schedule(bool preempt)
struct rq *rq;
int cpu;
+ printk_once("scheduler: Hi, I am the new scheduler!\n");
+
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
# plugsched-cli build /tmp/work/scheduler
7、将生成的 rpm 包拷贝到宿主机,退出容器,并安装调度器包,调度器日志显示新修改的调度器已经生效:
# cp /usr/local/lib/plugsched/rpmbuild/RPMS/x86_64/scheduler-xxx-4.19.91-25.2.an7.yyy.x86_64.rpm /tmp/work
# exit
exit
# rpm -ivh /tmp/work/scheduler-xxx-4.19.91-25.2.an7.yyy.x86_64.rpm
# dmesg | tail -n 10
[ 878.915006] scheduler: total initialization time is 5780743 ns
[ 878.915006] scheduler module is loading
[ 878.915232] scheduler: Hi, I am the new scheduler!
[ 878.915232] scheduler: Hi, I am the new scheduler!
[ 878.915990] scheduler load: current cpu number is 64
[ 878.915990] scheduler load: current thread number is 626
[ 878.915991] scheduler load: stop machine time is 243138 ns
[ 878.915991] scheduler load: stop handler time is 148542 ns
[ 878.915992] scheduler load: stack check time is 86532 ns
[ 878.915992] scheduler load: all the time is 982076 ns
我们通过以上知道了 Plugsched 是什么、应用案例,那它实现原理是什么?
调度器子系统在内核中并非是一个独立的模块,而是内嵌在内核中,与内核其它部分紧密相连。
Plugsched 采用“模块化”的思想: 它提供了边界划分程序,确定调度器子系统的边界,把调度器从内核代码中提取到独立的目录中,开发人员可对提取出的调度器代码进行修改,然后编译成新的调度器内核模块,动态替换内核中旧的调度器。对子系统进行边界划分和代码提取,需要处理函数和数据,而后生成一个独立的模块。
对于函数而言, 调度器模块对外呈现了一些关键的函数,以这些函数为入口就可以进入模块中,我们称之为接口函数。通过替换内核中的这些接口函数,内核就可以绕过原有的执行逻辑进入新的调度器模块中执行,即可完成函数的升级。模块中的函数,除了接口函数外,还有内部函数,其它的则是外部函数。
对于数据, 调度器模块默认使用并继承内核中原有的数据,对于调度器重要的数据,比如运行队列状态等,可以通过状态重建技术自动重新初始化,这类数据属于私有数据,而其它则是共享数据。为了灵活性,plugsched 允许用户手动设置私有数据,手动设置的私有数据会在模块中保留定义,但需要对它们进行初始化。
对于结构体而言,plugsched 将只被调度器访问的结构体成员分类为内部成员,其它为非内部成员。调度器模块允许修改内部成员的语义,禁止修改非内部成员的语义。如果结构体所有成员都是内部成员,则调度器模块允许修改整个结构体。但是,建议优先使用结构体中的保留字段,而不是修改现有成员。
Plugsched 主要包含两大部分,第一部分是调度器模块边界划分与代码提取部分,第二部分是调度器模块热升级部分, 这两部分是整个方案的核心。其整体设计方案如下:
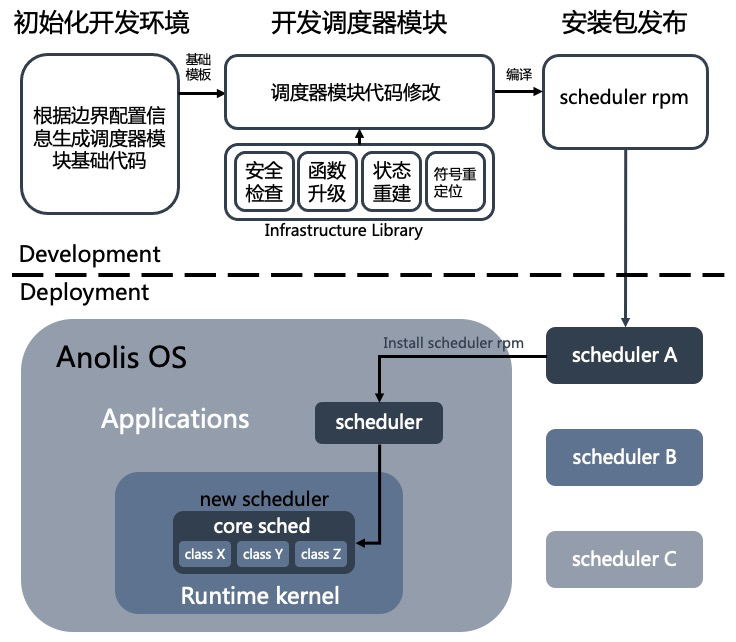
图 2 plugsched 整体架构
首先进行的是调度器模块边界划分和代码提取流程,由于调度器本身并不是模块,因此需要明确调度器的边界才能将它模块化。边界划分程序会根据边界配置信息(主要包含代码文件、接口函数等信息)从内核源代码中将调度器模块的代码提取到指定目录,然后开发人员可在此基础上进行调度器模块的开发,最后编译生成调度器 RPM 包,并可安装在对应内核版本的系统中。安装后会替换掉内核中原有的调度器,安装过程会经历以下几个关键过程:
符号重定位: 解析模块对部分内核符号的访问
栈安全检查: 类似于 kpatch,函数替换前必须进行栈安全检查,否则会出现宕机的风险。plugsched 对栈安全检查进行了并行和二分优化,提升了栈安全检查的效率,降低了停机时间
接口函数替换: 用模块中的接口函数动态替换内核中的函数
调度器状态重建: 采用通用方案自动同步新旧调度器的状态,极大的简化数据状态的一致性维护工作
基于以上介绍,整体来看,Plugsched 使得调度器从内核中解放出来,开发人员可以对调度器进行专项定制,而不局限于内核通用调度器;内核维护也变得更加轻松,因为开发人员只需要关注通用调度器的开发与迭代,定制化调度器可通过 RPM 包的形式进行发布;内核调度器代码也会变得简洁,无需再被各个场景的优化混淆起来。
未来,plugsched 会支持新版本内核和其它平台,持续对其易用性进行优化,并提供更多的应用案例。最后,欢迎更多的开发者能参与到 plugsched 中。
本文作者: 龙蜥社区内核开发人员陈善佩、吴一昊、邓二伟。

你也「在看」吗?👇