在自然语言处理、计算机视觉和二者的交叉领域中,通过训练大量与任务无关的数据集,建立大规模的通用模型来解决许多任务,已经成为主流方法。这些模型可以适应新的任务(例如翻译) ,利用不相关的数据(例如使用高资源语言来改进低资源语言的翻译) ,甚至可以通过将图像投影到语言空间来纳入新的模式。
这些方法的成功很大程度上来自于可扩展模型架构、大量未标注的任务无关数据以及高性能计算基础设施的不断改进。至关重要的是,标度律表明,规模带来的性能提升尚未达到饱和点。
在最近的一项工作中,谷歌研究院的成员们提出,类似的进展在强化学习领域是可能发生的,并且他们采取可扩展的方法的初步步骤,生成了表现优越的通才型智能体。与视觉和语言领域相反,强化学习通常倡导使用更小的模型,模型也通常用于解决单一任务,或在同一环境中的多个任务。重要的是,跨越多种环境的训练的研究数量并不多,很少有人研究横跨不同动力学、奖励、视觉效果和智能体实施方式的东西。
论文链接:https://arxiv.org/pdf/2205.15241.pdf
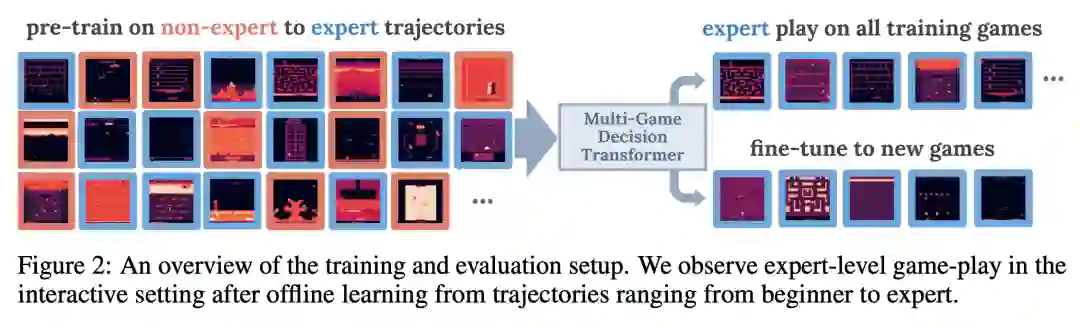
具体地说,研究者调研了是否可以从大量的专家和非专家经验中训练一个单一的模型(具有单一的一组参数)在多种环境中行动。他们在一组 41 个 Atari 游戏上进行训练,用来满足多样性方面的要求,并提出了一个问题:「模型能从玩很多视频游戏的过程中学到一些通用的东西吗?」
为了训练这个模型,研究者只使用了先前从 Agarwal et al. [1]中收集到的轨迹,但是交互式地评估了本研究的智能体。研究者表示,他们并不是在追求特定游戏智能体所能达到的精通程度或效率,因为这项研究仍处于早期阶段。相反,他们要探索的是,在语言和视觉领域观察到的相同趋势,是否也适用于大规模的通才型强化学习?
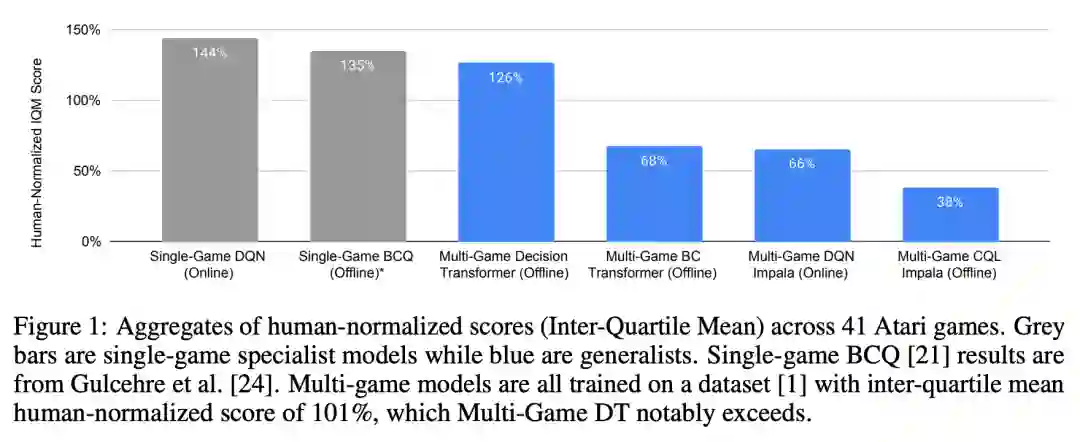
研究发现,在对离线专家数据集和非专家数据集进行训练之后,智能体可以在所有游戏中同时达到人类级别性能的 126%,如图 1 所示。此外,研究者还发现了与语言和视觉领域相似的趋势:用很少的数据快速适应从未见过的游戏(第 4.5 节) ,性能和模型大小之间的幂律关系(第 4.4 节) ,以及为更大的模型提供更快的训练进度。
值得注意的是,并非所有现有的多环境训练方法都有效。他们研究了几种方法,包括将问题处理为基于离线决策 Transformer 的序列建模 [14,34]、在线 RL [51]、离线时间差分方法[41]、对比表征[54] 和行为克隆[58]。
研究者发现,基于决策 Transformer 的模型在多环境下提供了最好的性能和扩展特性。然而,为了实现对专家和非专家轨迹的训练,有必要使用从语言建模引导生成技术来生成专家级别的动作,这与标准的决策 Transformer 有很大的不同。
为了回答一系列假设提问,研究者进行了多项实验,如下:
研究比较了多博弈机制和单游戏机制下不同在线和离线算法,发现单游戏专家模型仍然是最高效的。在多博弈通用模型中,多博弈决策 Transformer 模型最接近专家性能,多博弈在线 RL 与非 Transformer 模型排在第二位,而离线非 Transformer 模型很难获得好的表现。
可以注意到,多博弈在线 C51 DQN 中位数得分为 68% (附录 D) ,这与多博弈 Impala 中位数得分为 70% 的得分相似,这是根据 [20] 报告的结果计算得出的。
在大型语言和视觉模型中,最低可实现的训练损失通常随着模型大小的增加而可预测地减少。Kaplan et al. [37]证明了一个语言模型的容量 (next-token 自回归生成模型的 NLP 术语) 与其性能之间的经验幂律关系(在对抗数据上的负对数似然)。这些趋势在许多数量级的模型尺寸中得到了验证,包括从几百万参数的模型到数千亿参数的模型。
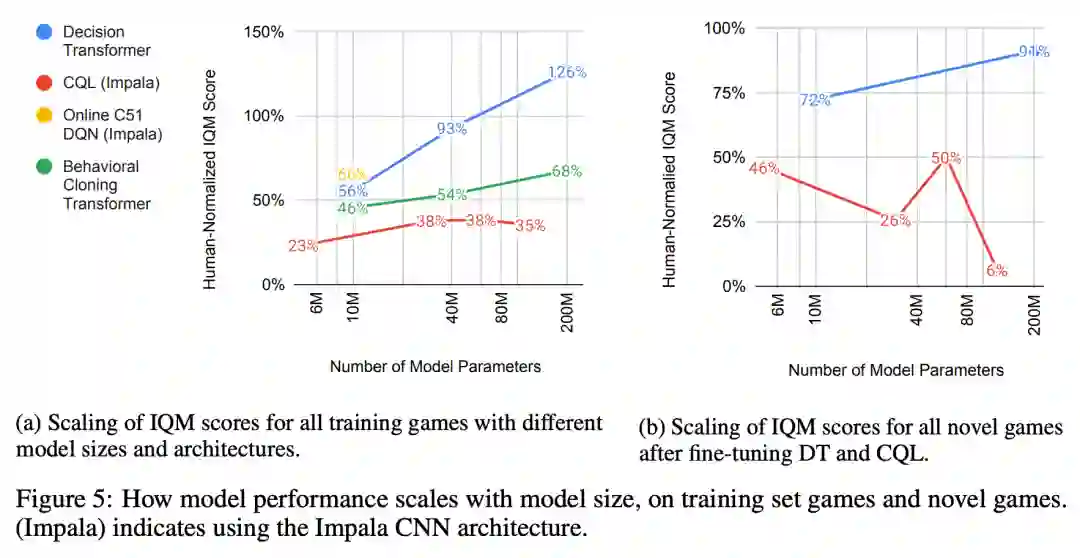
研究者调查了交互式游戏中的表现是否存在类似的趋势(而不仅仅是训练损失),并显示类似的幂律性能趋势,如图 5(a)。多博弈决策 Transformer 的性能实现了两个数量级的增加,而其他方法要么饱和,要么性能增长缓慢得多。他们还发现,较大的模型训练更快,在观察相同数量的 token 后,能达到更高的游戏性能。附录 G 中进一步讨论了这些结果。
尽管雅达利游戏是一项自然而且动机良好的任务,但是由于它与人类如何将知识转移到新游戏的相关性问题,对于快速适应新游戏的预训练还没有被广泛探讨。Nachum 和 Yang 针对 Atari 的大型离线数据和小型专家数据进行了预训练,并与基于互模拟的一系列状态表征学习目标进行了比较,但是他们的预训练和微调使用的是同一个游戏。相反,本文研究者感兴趣的是经过训练的智能体迁移到新游戏的能力。
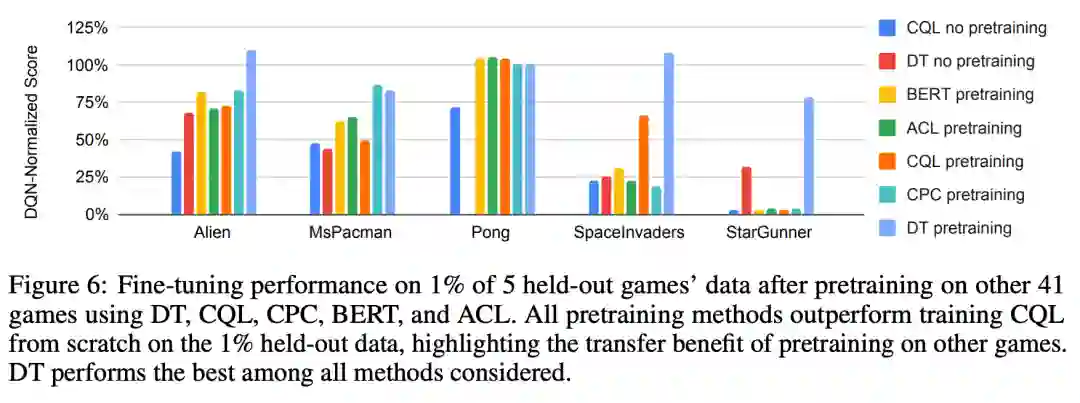
图 6 展示了对抗游戏中的微调性能。带有 DT 目标的预训练在所有游戏中表现最好,所有预训练的方法都比从零开始的训练有效,这证实了本研究的假设,即针对其他游戏的预训练确实有助于智能体快速学习一项新游戏。CPC 和 BERT 的表现不如 DT,这表明仅仅学习状态表征不足以达到理想的迁移效果。虽然 ACL 为 BERT 增加了一个动作预测辅助损失,但效果不明显,这表明在离线数据上正确建模动作对于获得良好的传输性能非常重要。此外,研究者还发现微调性能会随着 DT 模型变大而提高,而 CQL 微调性能与模型大小并不一致(参见图 5b)。
多博弈决策 Transformer 是否改进了训练数据?
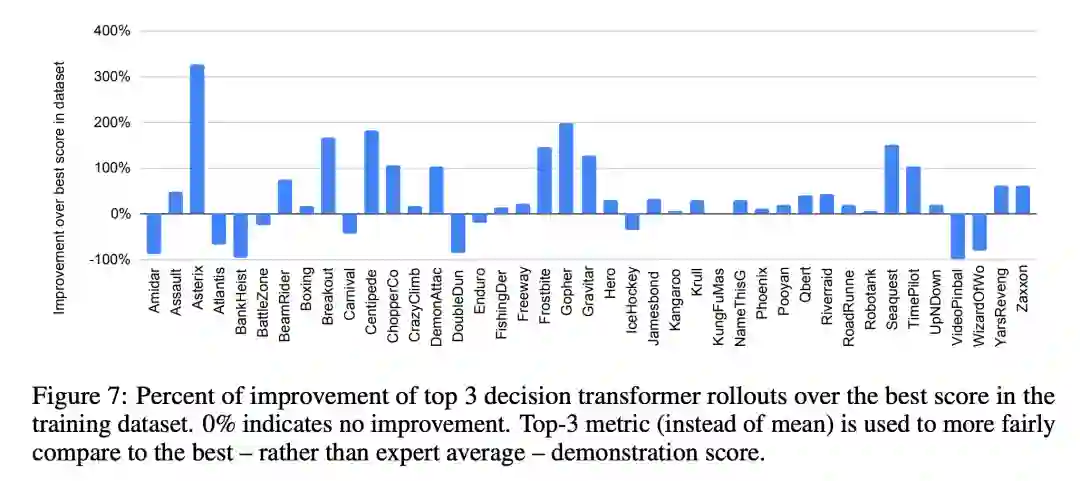
研究者想要评估的是,带有专家行动推理的决策 Transformer 是否能够超越最好的演示在训练中展现的能力。为了做到这一点,研究者看了表现 top 3 的决策 Transformer 模型的 rollout。他们使用了 top 3 的 rollout,而不是所有 rollout 的平均值,以更公平地比较最好的演示,而不是一个普通的专家演示。图 7 中展示了对比单个游戏的最佳演示得分提高的百分比,在一些比赛中,实现了训练数据的显著改善。
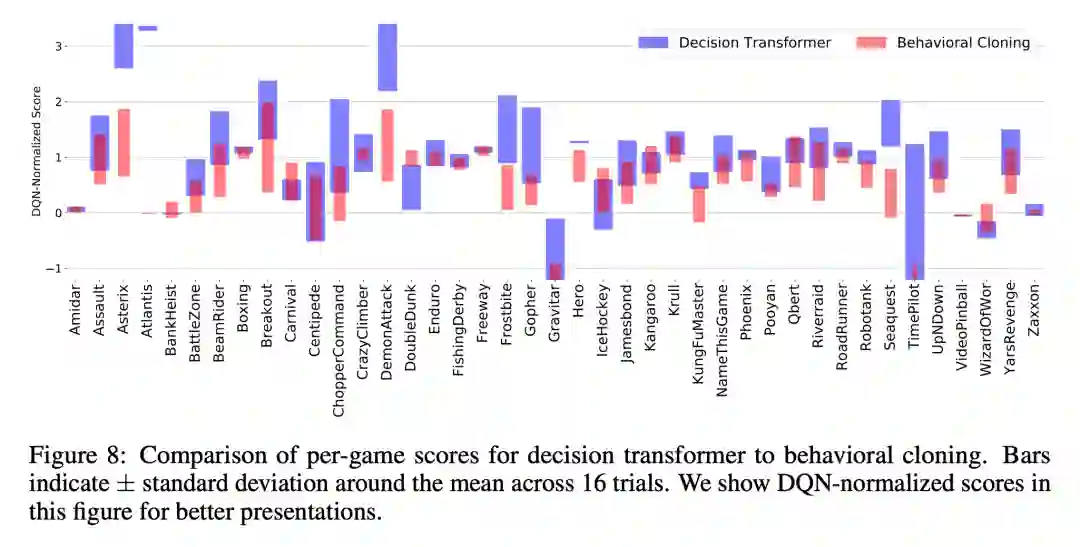
图 8 展示了所有游戏得分的平均值和标准差。虽然行为克隆有时可能会产生高回报的 episode,但这种情况此时不太可能发生。研究者发现,在 41 个游戏中,有 31 个游戏的决策 Transformer 的性能优于行为克隆。
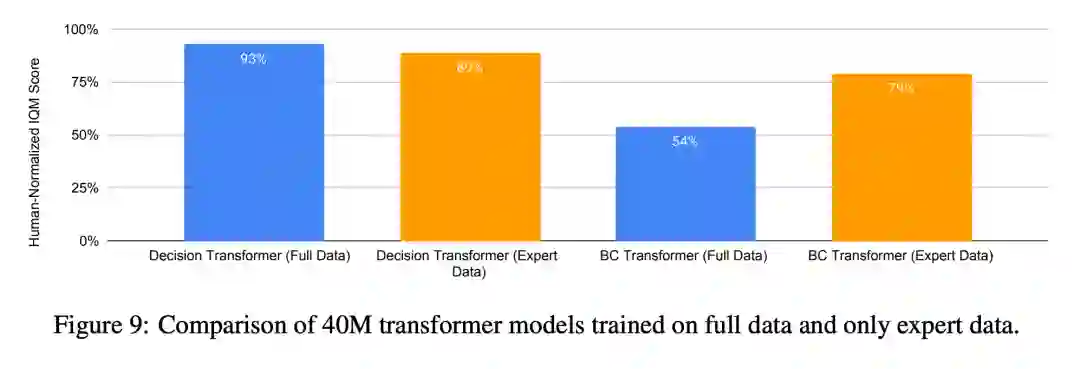
与从专家示范中学习相比,从包括一些专家数据但主要是非专家数据的大型多样化数据集中学习有助于学习和提高性能。为了验证这个假设,研究者根据 episodic returns 过滤了每个游戏的训练数据,并且只保留前 10% 的轨迹,以生成一个专家的数据集 (详情见附录 E)。他们使用了这个专家数据集来训练多博弈决策 Transformer(DT-40M) 和基于 Transformer 的行为克隆模型(BC-40M)。图 9 比较了这些模型训练的专家数据和 DT-40M 训练的所有数据。
决策 Transformer 是一个 Upside-Down RL (UDRL)实现,它使用 Transformer 体系架构,并将 RL 视为序列建模问题。为了理解 Transformer 体系架构的好处,研究者将其与使用前馈、卷积 Impala 网络的 UDRL 实现进行比较。
图 10 展示了使用 Impala 架构的决策 Transformer 相对于 UDRL 的明显优势。在比较 UDRL (Impla)和 CQL (在评估的每个模型尺寸上使用相同的 Impla)时,可以观察到 UDRL (impla)优于 CQL。结果表明,本文方法的好处不仅来自于使用的网络架构,同时来自于 UDRL 公式。
尽管由于设计空间的因素,将 Transformer 与所有可能的卷积架构进行比较是不可行的,但研究者相信这些经验性的结果仍然显示了一个明显的趋势,对于 UDRL 和 Transformer 架构都是有益的。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com