利用对抗技术来权衡推荐精度与用户隐私

目录
-
前言 -
动机 -
框架 实验结果
前言
任何需要做两方权衡并且最终寻求一种平衡的问题其实都可以转化为对抗学习的范式,比如图像生成任务中既要保证生成图片的质量又要确保判别器的识别精度;推荐任务中既要保证用户的隐私不受侵害又要确保推荐质量的可靠。
动机
框架
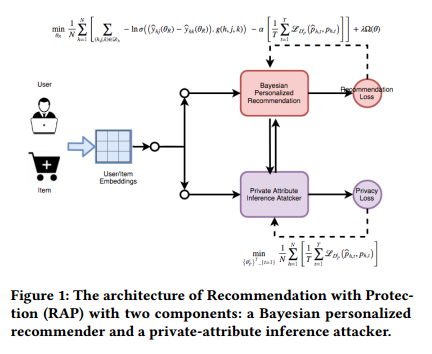
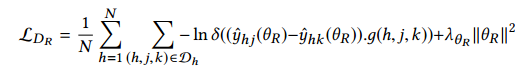
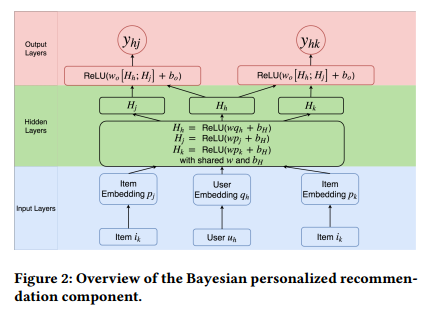
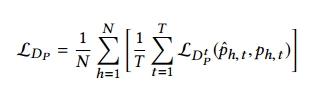
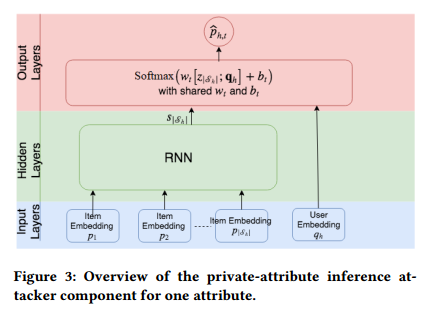

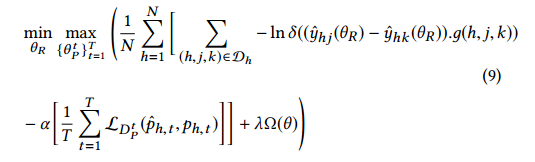
实验结果
-
Original:该方法是RAP算法的退化版本,即没有考虑PAA部分。 -
LDP-SH:该方法基于 -差分隐私来对用户-项目交互数据增加噪声 -
BlurMe:此方法在输入推荐系统之前扰乱了用户-项目交互矩阵,通过给用户添加与实际属性相反的项目,然后给这样项目填充为平均分。
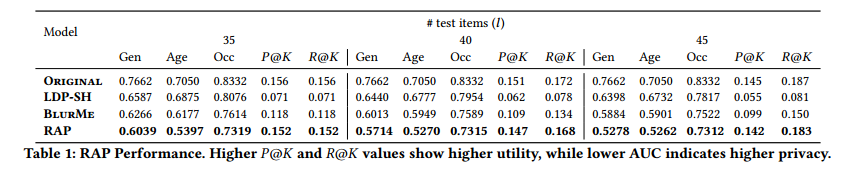
推荐阅读

登录查看更多
相关内容

专知会员服务
47+阅读 · 2020年6月3日
Arxiv
4+阅读 · 2020年2月13日



相关VIP内容
专知会员服务
47+阅读 · 2020年6月3日
相关资讯
相关论文
Arxiv
4+阅读 · 2020年2月13日