首次曝光!在线视频衣物精确检索技术,开启刷剧败明星同款时代
阿里妹导读:CVPR是由全球最大的非营利专业技术学会IEEE(电气和电子工程师协会)举办的计算机视觉领域的国际顶会,2017CVPR收到超过2500篇论文投递,最终收录不到800篇,阿里巴巴集团iDST和AI LAB 有多篇论文被收录。
今天为大家深入解读被CVPR 2017收录的论文之一、来自阿里巴巴iDST 视频分析团队的《从视频到电商:视频衣物精确检索》。
《从视频到电商:视频衣物精确检索》围绕视频电商业务场景,提出了一个在线视频衣物精确检索系统。该系统能够满足用户在观看影视剧时想要同时购买明星同款的需求。
整个系统采用了目前最先进的衣物检测和跟踪技术。针对明星同款检索中存在的多角度、多场景、遮挡等问题,提出可变化的深度树形结构(ReconfigurableDeep Tree structure)利用多帧之间的相似匹配解决单一帧检索存在的遮挡、模糊等问题。该结构可以认为是对现有attention模型的一种扩展,可以用来解决多模型融合问题。

论文技术在天猫魔盒视频中应用
业务场景及研究问题:视频电商中的衣物精确匹配
早在2014年,阿里与优酷土豆发布视频电商战略,称未来可以实现边看边买,使得视频电商的概念,继微博电商,朋友圈电商之后浮出水面。电商平台拥有少量商品,而视频网站具有巨大的流量,二者结合是发展的必然结果。电商平台可以借助视频网站的流量来实现导流和平台下沉,而视频网站则需要通过广告点击和商品成交来实现流量变现,因此二者的结合可谓一拍即合。
视频电商的商业主旨是打造以视频为入口的购物服务,视频中出现所有物体都可能是商品,提供包括边看边买、明星同款、广告投放等服务,它集娱乐、休闲、购物于一体,给用户构造出一种“身临其境”情境营销,或者是明星同款的冲动式消费。视频电商目前已经不是停留在概念层次了,视频网站向电商的导流转化也一直在不断的尝试中。
影视剧中的服饰存在较大的差异性和异构性,同一个目标往往展现出较大的差异。服饰购物图像通常具有杂乱、多样的背景,而且常在户外拍摄。多样化的背景可能是建筑物,街道、风景、汽车等多种情况。由于自然场景下受到光线、角度、大小、分辨率、几何学和光度学的变化等影响,使得服饰呈现出现的外形极为复杂,即使是同一件服饰也会出现变化较大的效果。
同时在线网站为更好地展示服饰的效果,通常聘请时尚模特穿着所售商品,模特/人物姿势变化也是导致服饰变化的一个重要因素。由于以上这些因素,使得视频明星同款搜索成为了一个极具挑战性的技术问题。
网络结构及技术细节
AsymNet网络结构:整个Asymnet深度神经网络结构如图1所示。当用户通过机顶盒(天猫魔盒)观看视频时,该网络将从电商网站(淘宝、天猫)检索到与之匹配的衣服,并推荐给用户。
为忽略复杂背景对检索结果的影响,更准确的进行服装定位,我们首先应用服饰检测技术,提取得到服饰区域一组候选框。然后对这些候选框进行跟踪,得到明星同款在视频中的的运动轨迹。对于衣物候选区域和运动轨迹我们分别利用用图像特征网络(IFN)和视频特征网络(VFN)进行特征学习。
考虑到服装的运动轨迹,衣物精确检索问题被定义为不对称(多对单)匹配问题,我们提出可变化的深度树形结(Reconfigurable Deep Tree Structure),利用多帧之间的相似匹配解决单一帧检索存在的遮挡、模糊等问题。后续本文将详细介绍模型的各个部分。
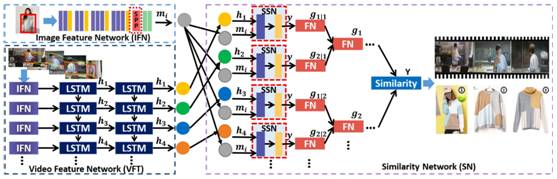
图 1 Asymnet深度神经网络结构
图像特征网络(IFN):传统CNN网络要求输入图像为固定的227x227(因为CNN网络中的卷积层需要有一个确定的预定义的维度)。在视频电商业务场景中,因为衣物检测候选框为任意大小,尺度变化很大,传统CNN网络无法进行有效的特征学习。
针对这一问题,我们利用空间金字塔池化结构(SPP)体系结构,如图2所示。它通过空间池聚合最后一个卷积层的特征,从而使池区域的大小与输入的大小无关。
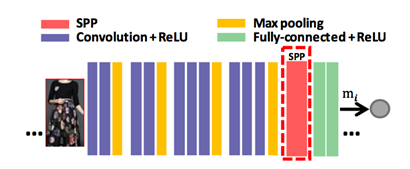
图 2 Asymnet图像特征网络(IFN)
视频特征网络 (VFN):为了更好的考虑视频的空间序列模式,进一步提高衣物检索的性能。基于 LSTM,我们提出了视频特征网络 (VFN),如图3所示。其中实验验证明两层堆叠式 LSTM 结构能够在视频特征学习中得到最佳性能。
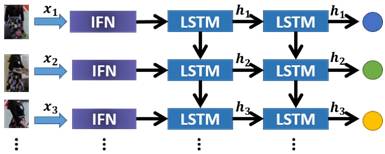
图 3 Asymnet视频特征网络(VFN)
相似性网络:明星同款匹配不同于近似衣物检索,精确匹配要求完全一致。在完全一致的要求下,传统的通过相似性计算来进行检索的方法,不能满足明星同款精确匹配要求。已有的方法通常将精确匹配问题转换为一个二分类问题,但这种方式适应性差,只能利用单一时刻的视频帧。
为了能够利用整个衣物运动轨迹,我们提出了如下的可变化的深度树形结构(ReconfigurableDeep Tree structure)将匹配问题转换为逻辑回归问题。匹配网络拟采用基于混合专家系统的逻辑回归网络。该结构可以认为是对现有attention模型的一种扩展,可以用来解决多模型融合问题。
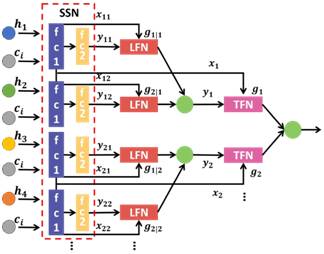
图 4 Asymnet相似性网络
整个模型的目标函数是综合考虑每一帧的匹配结果,得到基于整个衣物运动序列和电商衣物的相似性,整个系统可以建模为对如下目标公式进行求解:
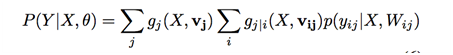
类似于attention机制,我们提出如下后验概率模型,来对上式进行求解:
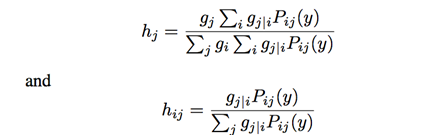
得到如下梯度并采用端到端方式进行网络学习。
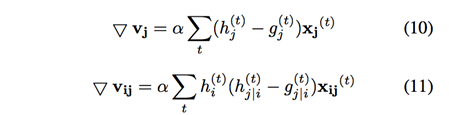
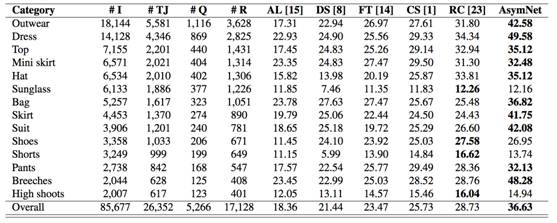
试验结果:我们利用业务数据和最新的衣物检索方法进行了对比,试验结果如下表所示。相对于alexnet,Asymnet在前20的检索精确率指标上,其性能几乎提高了进一倍。
相对于其他2种网络CS和RC,我们发现RC的性能略优于CS,因为RC具有较强的识别能力差异较小(采用多任务学习)。甚至在对于某些类别(无明显差别)RC在精确率上甚至略好于AsymNet,但是总的来说AsymNet比目前现有的方法拥有更好的性能。因为Asymnet可以处理现有的视频的时空动态变化,并结合自动视频帧的自动调节炉排判别信息的融合策略。
点击文末“阅读原文”,即可下载论文内容。

你可能还喜欢
点击下方图片即可阅读



从来往到钉钉,从技术Leader到产品负责人,陶钧到底经历了什么?

关注「阿里技术」
把握前沿技术脉搏





