苹果首次披露Siri声纹识别技术

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
苹果最初于 iPhone 6(iOS 8)上正式引入“Hey Siri”轻盈。这项功能允许用户在无需按下 home 键的情况下轻松激活 Siri。当用户说出“Hey Siri,今天的天气如何?”时,手机会在听到“Hey Siri”表达后被唤醒,并将其余语音作为 Siri 请求进行处理。
这项功能的意义,在于确保当用户无暇腾出双手时(例如驾车或烹饪时)仍可访问放在身边的手机设备,并通过“Hey Siri”短语触发 Siri 语音助手功能。大家可以想象,在使用智能烤箱时,用户完全可以在手持火鸡烤盘的同时通过 Siri 为烤箱设定计时器。
在 iPhone 6 上,“Hey Siri”功能只能在手机充电时使用 ; 但在后续推出的 iPhone(6S 及以上)与 iPad 机型当中,这项功能开始以低功耗方式提供永久在线的持续接听能力。这意味着“Hey Siri”功能可随时随地为用户服务。
但很明显,“Hey Siri”必须能够准确分辨说话者的语音内容并判断其是否与自身相关,而这也就是所谓“关键短语检测”问题。我们解决方案中所采用的技术方法与实现细节已经在此前发布的《苹果机器学习杂志》文章 [1] 中进行了详尽说明。在这项工作中,我们假设存在“Hey Siri”探测器,并着力探讨语音识别系统如何逐步根据用户习惯实现个性化调整。我们利用深层神经网络对早期建模工作加以描述,而这亦成为后续 ICASSP2018 论文 [2] 中相关改进的实现基础——在这一轮改进中,我们利用递归神经网络、多风格训练以及课程学等方式建立起更为强大的语音表达识别能力。
“Hey Siri”一词的选定可谓顺理成章。事实上,在此项功能发布之前,用户们也会利用 home 键激活 Siri,并有意无意地在自己的表述之前加上“Hey Siri”字眼。然而,这种简洁而清晰的结构也带来了新的挑战。具体来讲,我们的早期离线实验结果显示,相较于理想中的合理调用比率,这样简单的激活语音会带来大量意外激活状况。意外激活主要分为以下三种情况:1)用户说出了类似的短语 ; 2)其他用户说出了“Hey Siri”; 3)其他用户说出类似短语。最后一种则是三大错误激活情况中最令人恼火的问题。为了减少这种错误激活比例,我们努力对每一台设备进行个性化设置,确保其在大多数情况下仅在机主说出“Hey Siri”时才有所反应。为此,我们需要利用说话人识别领域的技术成果。
说话人识别(简称 SR)的总体目标在于确定语音来源者的实际身份。我们关注的是“谁在说话”,而非“说了什么”——这也正是说话人识别与语音识别间的核心差异。利用先验已知短语(例如‘Hey Siri’)实现的说话人识别方案通常被称为文本依赖型方案 ; 而在其它情况下,则被称为非文本依赖型方案。
我们将模仿者接受(特立独行 IA)率与虚假排斥(简称 FR)率相结合,用以衡量说话人识别系统的具体效能。但与此同时,我们也需要充分保证系统的关键短语触发质量——反复重试对机主而言显然很不友好。对于关键短语触发系统与说话人识别系统,当目标用户说出“Hey Siri”且其身处嘈杂环境当中(例如坐在车中或身处行人众多的步道上)时,设备往往无法被正确唤醒。而单纯关注关键短语触发系统,我们发现有些系统会被非“Hey Siri”语音错误唤醒,例如“are you serious”或者“in Syria today”等读音接近的表述。一般来讲,FA 以小时为单位进行测量。
在说话人识别场景当中,我们假定所有传入的话语都包含有“Hey Siri”部分。具体来讲,这意味着与说话人有关的个性化判断步骤发生在系统已经正确识别出“Hey Siri”并受到触发之后。为此,我们将模仿者接受(简称 IA)视为一类说话人识别错误,并努力避免将此类错误与由关键短语触发系统所引发的非“Hey Siri”激活错误相混淆。当然,在实际使用当中,说话人识别步骤不可能完全回避由触发系统产生的错误。而且尽管效果令人印象深刻,但这并不是我们预先设定的系统训练目标——我们将在稍后进一步讨论这个问题。最后,选定的操作点或一组决策阈值将对 FA、FR 以及 IA 率产生决定性影响——阈值越高,FR 成本越高,而 FA 与 IA 率越低 ; 反之亦然。
说话人识别系统的应用涉及两个步骤:登记与识别。在登记阶段,用户需要说出几条样本短语。这些短语将用于为用户的语音创建统计模型。而在识别阶段,系统会将传入的话语同用户训练模型进行比较,并根据该话语是否属于现有模型这一具体判断决定接受或拒绝。
“Hey Siri”个性化(简称 PHS)的主要设计讨论围绕两种用户登记方法展开:显式与隐式。在显式登记过程中,用户需要多次说出目标触发短语,并由设备上的说话人识别系统利用这些口头表达内容训练 PHS 说话人配置文件。这种方式能够确保每位用户在开始使用“Hey Siri”功能之前都建立起经过严格训练的 PHS 配置文件,从而显著降低内部审计成本。然而,在显式登记期间,录音内容中往往会包含非常微小的环境声变化。初始配置文件通常应由纯语音创建完成,但现实世界中的情况几乎不可能达到这样的理想状态。
接下来是隐式登记概念,其主要利用机主一段时间内说出的话语建立说话人简档。由于这些录音是在现实世界环境下生成的,因此往往能够提高说话人话语特征的稳定性。然而,这种方式的风险在于可能接受模仿者的语音,或者将真实机主的输入内容视为错误信息。如果在初步录入时包含此类干扰信息,则有可能导致得出的配置文件不够准确,且无法忠实还原机主的声音特征。这意味着设备可能会错误拒绝机主的激活语音,或者错误接受其他模仿者的声音(或者二者兼而有之)。在这种情况下,语音激活功能将变得毫无意义。
我们目前的实现方案结合了这两种登记步骤。其利用显式登记建立初始说话人配置文件,且依次使用以下五条显式登记短语:
“Hey Siri”
“Hey Siri”
“Hey Siri”
“Hey Siri, how is the weather today?”
“Hey Siri, it’s me.”
这种多话语登记方式能够帮助用户了解此项功能的不同使用方式(单次模式与双次模式),且每位用户都能够在 FA 率受控且可管理的前提下使用此项功能。
在下一节当中,我们将描述如何利用隐式登记机制更新说话人配置文件。展望未来,我们希望能够在接下来的版本当中不再设置任何明确登记步骤——用户只需从空白配置文件起步直接使用“Hey Siri”功能,并随着越来越多“Hey Siri”请求的出现实现配置文件的填充与更新。这无疑将成为选择跳过“Hey Siri”初始设置流程的用户们的福音。系统概述
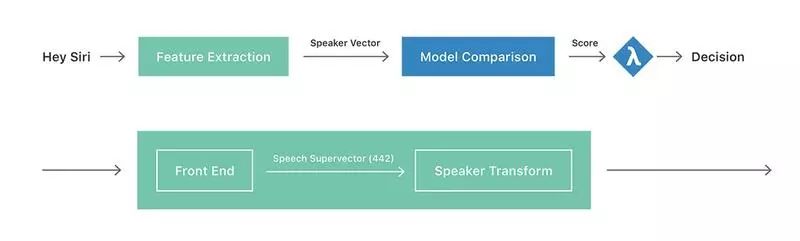
图一:Hey Siri 个性化流程图
图一的上半部分显示了我们的 PHS 系统高层流程。其中绿色框体代表将时长不定的“Hey Siri”声音实例转换为固定长度的说话人矢量。此矢量亦可被视为一条说话人嵌入。而在 Feature Extraction(特征提取)框体处,我们分两个步骤进行说话人矢量计算,具体如图一下半部分所示。第一步为将输入语音转换为固定长度的语音(超)矢量,其属于“Hey Siri”话语当中全部声学信息的总结——具体涵盖语音内容、背景环境记录以及说话人身份信息。在第二步中,我们则尝试以专注说话人特征的方式进行语音矢量转换,同时强调语音与环境因素的可变性。在理想情况下,我们可以对这种转换算法进行训练,从而识别不同环境下(例如厨房、车内、咖啡厅等)用户的“Hey Siri”实例与发声模式(例如清晨充满睡意的语音、正常语音以及高音量语音等)。我们的输出结果为说话人信息的低维表示,即说话人矢量。
在每一台启用“Hey Siri”功能的设备上,我们都会存储由一组说话人矢量组成的用户配置文件。如前所述,该配置文件在经历显式登记过程后将包含五个矢量。在图一中的模型比较阶段,我们为每条输入测试话语提取相应的说话人矢量,并针对配置文件内每条说话人矢量计算其余弦得分(即长度归一化点积)。如果这些分数的平均值大于预定阈值(λλ),则代表设备将被唤醒并处理后续命令。最后,作为隐式登记流程的组成部分,我们持续向用户配置文件当中添加说话人矢量,直到其矢量数达到 40 条。
除了说话人矢量之外,我们还会在手机上存储“Hey Siri”所对应的发声波形。在通过即时更新部署改进转换机制之后,每个用户配置文件都将能够利用该发声波形进行重建。
语音转换是所有语音识别系统中最重要的部分。给定一个语音向量,这个变换的目标是最大限度地减少语音之内的可变性,同时最大限度地增加语音之间的可变性。在我们最初的方法中,我们从独立于语音的“Hey Siri”探测器导出了语音向量 [1],它使用 13 维的梅尔倒频谱(Mel frequency cepstral coefficients,MFCC)作为声学特性,并将 28 个 HMM 状态参数化来建模“Hey Siri”的发音。然后通过将状态端连接成 28x13=364 维向量来获得语音向量。
这种方法与研究领域中的现有工作非常相似,其中一种最先进的方法,也使用了串接声学状态段作为其在语音中的初始表示。(注:在语音识别的说法中,这种被称为“超向量”,因为它是其他向量的串接。另一种众所周知的标识是“i-vector”,它可以视为超向量的低维表示,捕获最大可变性的方向 [3];即类似于主成分分析。虽然 i-vector 在独立于文本的语音识别问题取得了很大的成功,但我们发现,语音超向量在我们的文本相关场景中,语音超向量同样有效。)那么,目标就是找到这种表示的子空间,它可以作为可靠的语音表示。
继之前的工作之后,我们的语音转换的第一个版本通过线性判别分析(Linear Discriminant Analysis,LDA)使用来自 800 个生产用户的数据进行训练,每个用户提供了超过 100 个发音,并产生了一个 150 维的语音向量。尽管它相对简单,但这个初始版本相对于没有语音转换的基线,显著降低了 FA 率。
通过使用显式注册数据,增强前端语音向量,并将其转换为一种具有深度神经网络(DNN)形式的非线性判别技术,进一步提高了转换的效果。通过对语音识别研究社区的知识支持,更高阶的倒谱系数可以捕获更多语音特定的信息,我们将 MFCC 的数量从 13 个增加到 26 个。此外,由于前 11 个 HMM 状态实际上只是模拟了静音,我们将其从考虑中移除。这就产生了一个包含 26x17=442 维的新的语音向量。然后,我们训练了一个来自 16000 个用户的 DNN,每个用户提供了大约 150 句话。网络体系结构由 100 个神经元隐藏层组成,并具有 sigmoid 激活(即 1x100S),其后是具有线性激活的 100- 神经元隐藏层,以及具有 16000 个输出节点的 softmax 层。该网络训练使用语音向量作为输入,并将每个语音对应的 1 个热向量为目标。对 DNN 进行训练后,将最后一层(softmax)移除,并将线性激活层的输出用做语音向量。这个过程如图 2 所示。

图二. DNN 训练和语音向量生成过程
在我们的超参数优化实验中,我们发现一个具有 sigmoid 激活(即 4x256S)神经元层的网络结构,随后 100 个神经元的线性层得到了最好的结果。我们通过对每层的权重应用 8 位量化来补偿所需的额外内存,以适应更大的网络参数数量的增加。
除 FR 和 IA 率外,我们还可以通过单一等错误率(equal error rate,EER)值总结语音识别系统的性能;这是 FR 等于 IA 的点。在没有理想的操作点的情况下,可以包括不同的成本和 / 或目标与冒充者测试语音的先验概率,那么 ERR 将成为总体性能的一个很好的指标。
表 1. 不同语音转换的性能
a. 语音识别性能

b. 个性化的“Hey Siri”性能(端到端)

表 1 显示了使用上述三种不同的语音转换获得的 ERR。该实验使用来自生产数据的 200 个随机选择的用户来执行。用户的平均音调从 75Hz 到 250Hz 不等。表 1 a 的前两行表明,通过改进的前端(语音向量)和神经网络(语音向量)所带来的非线性建模,使得语音识别性能得以显著的提高。而第三行显示了更大的网络性能。这些结果得到了一项独立调查的证实,研究者在不同的数据集上探索了类似的方法,并获得了类似的性能改进。
由于 ERR 仅在语音识别任务中测量,在这个任务中,输入音频被假定为包含“Hey Siri”的实例,由此观察到的改进并不一定能保证端到端“Hey Siri”应用程序的性能改进。表 1 b 显示了使用各种余韵转换的完整特征的 FA、FR 和 IA 率。该实验使用来自播客和其他来源的 2800 小时的负类(非触发)数据,以及 150 名男性和女性用户的正类(触发)数据进行。我们的结果似乎表明,改进的 DNN 语音转换显著地提高了“Hey Siri”的整体性能。
尽管平均语音识别的性能有了显著的提高,但有证据表明,在混响(大房间)和嘈杂(汽车、刮风)等环境中的性能仍然更具挑战性。我们目前的研究工作之一是侧重于理解并量化这些困难条件下的退化,其中传入的测试语音的环境与用户语音的描述严重不匹配。在我们的后续工作 [2] 中,我们以多风格训练的形式展示了成功,去重一部分训练数据,增加了不同类型噪声和混响。
在其核心,“Hey Siri”功能的目的是让用户能够发出召唤 Siri 的请求。本文所描述的工作仅利用语音的触发短语(即“Hey Siri”),这是语音识别的一部分;但是,我们还可以利用语音中的 Siri 请求部分(例如,“…, how’s the weather today?”),以文本独立的语音识别的形式来使用。在论文 Generalised Discriminative Transform via Curriculum Learning for Speaker Recognition[2] 中,我们调查使用递归神经网络体系结构(特别是 LSTM,论文 End-to-end Text-dependent Speaker Verification[5])的课程学习的方法,来总结包含文本相关和文本无关信息的可变长度音频序列的语音信息。我们的研究结果表明,通过使用完整的“Hey Siri”进行语音识别,可以实现显著的性能提升。
参考文献
[1] Apple Siri 团队:Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant.Apple Machine Learning Journal, vol. 1, issue 6, October 2017. URL: https://machinelearning.apple.com/2017/10/01/hey-siri.html
[2] E. Marchi、S. Shum、K. Hwang, S. Kajarekar、S. Sigtia、H. Richards、R. Haynes、Y. Kim、J. Bridle 著: Generalised Discriminative Transform via Curriculum Learning for Speaker Recognition. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2018.
[3] N. Dehak、P. Kenny、R. Dehak、P. Dumouchel、P. Ouellet 著: Front-end Factor Analysis for Speaker Verification. IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788-798, May 2011.
[4] G. Bhattacharya、J. Alam、P. Kenny、V. Gupta 著: Modelling Speaker and Channel Variability Using Deep Neural Networks for Robust Speaker Verification. Proceedings of the IEEE Workshop on Spoken Language Technology (SLT), December 2016.
[5] G. Heigold、I. Moreno、S. Bengio、N. Shazeer 著: End-to-end Text-dependent Speaker Verification.Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2016.
原文链接:https://machinelearning.apple.com/2018/04/16/personalized-hey-siri.html#2


好看的文章千篇一律,有趣的灵魂万里挑一。读者朋友记得给我留言和点赞哦!




