目标检测:NMS-Free时代
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达、
作者:半日闲心 | 已授权转载(源:知乎)
https://zhuanlan.zhihu.com/p/453773468
过去,无需nms的目标检测,很美很纯粹,但几乎没人想过应用到业务上。然而经过近些年的发展,性能甚至超过了nms-base。站在2021年的尾巴,回顾nms-free的发展,期待2022有更好的发展。
本文脉络
什么是nms,为什么需要nms
什么是nms-free,有啥好处?
nms-free的发展历程
nms-free的现状与未来
什么是nms,为什么需要nms
nms是柠檬树的简称,懂得都懂,不懂请退出吧。nms原理请自行搜索。为啥需要柠檬树呢?
因为CNN做预测的时候,往往会对同一个目标产生多个proposal,因此需要nms过滤掉多余的预测框。
产生duplicate bbox的原因有CNN自身结构的原因,有时候feature map上很难决定相邻的两个特征点谁表示目标谁表示背景。尤其在一些目标边缘比较模糊的时候,如下图。另一方面,既然会产生duplicate bbox,还不如拥抱duplicate,通过规则让一个目标匹配多个proposal来增加正样本数量,使训练的前景与背景更加均衡,最后理直气壮用nms过滤就好了。Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR2019

图片来源:Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR2019[1]
此处统一术语。模型输出的框是候选框(proposal)。proposal会预测一个目标称为instance。人工标注的框为GT。训练阶段,如何让具体哪个proposal与哪个GT匹配的策略称为label assign,上面提到一个GT只跟一个proposal匹配称为one-to-one(o2o),一个GT匹配多个proposal的方法称为many-to-one(m2o)。
so,要想实现nms-free,label assign必须是one-to-one的。
什么是nms-free,有啥好处?
nms-free就是不需要nms的目标检测,甚至可以认为没有后处理的目标检测。优势1.整体框架简洁,更少超参数。2.目标之间重叠严重的话就无法用了。
但目前的主流依然存在nms,足以说明nms的优势大于劣势。很多场景的目标检测,目标是稀疏的,此时many-to-one + nms组合简直不要太爽。
出现重叠怎么办?忽略就行,出现概率很低啦。教育甲方不能这样玩。甲方要退钱了?RotateAnchor[2]改一波。
Nice。甲方说不可描述场景依然漏检,还发来了图片[色迷迷]。

此时,nms党不慌不忙的掏出了《Detection in Crowded Scenes: One Proposal, Multiple Predictions》[3]。每个proposal预测K个instance,意思是该proposal预测的地方可能有K个instance高度重叠。上图K>=2即可。
是不是有点类似anchor-base一个特征点有k个anchor,但anchor形状差异很大,人工匹配规则也无法解决高度重叠场景。一个proposal预测k个instance可看作对anchor做了修改。匹配的规则也做了修改:
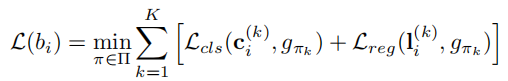
b_i是第i个proposal,L_cls和L_reg分别是label交叉熵和bbox回归的loss。L(b_i)可以看作是EMDLoss(推土机距离),距离最小就是匹配方案。
由于一个proposal包含了多个instance,所以nms也做了相应的修改,称为set-nms,出自同一个proposal的k个instance必然非同一目标,iou再高也不能干掉。

等等,nms-base好像没啥毛病了,增加后处理算啥毛病。标题起错了,”who care nms-free”。
有一说一,nms使检测算法不够直观、简单,更像tradeoff的行为[挽尊]。nms-free简单的结构,降低了det学习的门槛。
nms-free的发展历程
此处挑比较有意思的论文介绍。如有遗漏或指正,欢迎留言。
《End-to-end people detection in crowded scenes》CVPR2016[4]
在Faster-rcnn、YOLOv1问世的2015年,这篇LSTM跨界搞目标检测的论文显得有些默默无闻。
该论文的主要思路是CNN作为enconder,LSTM作为decoder,把目标检测看成序列一个instance一个instance输出,每个instance包含置信度和bbox,当输出的置信度<0.5,则看作停止符停止往下预测。
那如何训练?label assign如何做?由于LSTM decoder的机制,instance按顺序输出,而GT无顺序。作者尝试了让GT按照从左到右等不同规则排序,并与排序的instance做匹配。
最后作者使用更好的策略,把instances与GTs匹配看成二分图匹配问题,并通过匈牙利算法确定最佳的匹配。具体算法自行搜索。简单的解析是:instance与GT做one-to-one匹配并求instance与GT的IoU,统计IoU之和。不同的匹配方案,IoU之和不同。通过匈牙利算法找到IoU之和最大的匹配方案,也就是本论文的最终方案。此算法后来几乎成了nms-free做label assign的标准解法。
《Relation Networks for Object Detection》CVPR2018[5]
作者借鉴了隔壁NLP的《attention is all your need》的思想,在backbone里面融合self-attention,思路是每个proposal通过attention了解图片中存在什么proposal,从而知道自身处于什么场景,提升准确率。例如一个屏幕,在沙发旁边是电视,在键盘旁边是显示器。如今没人会怀疑self-attention在cv的作用。
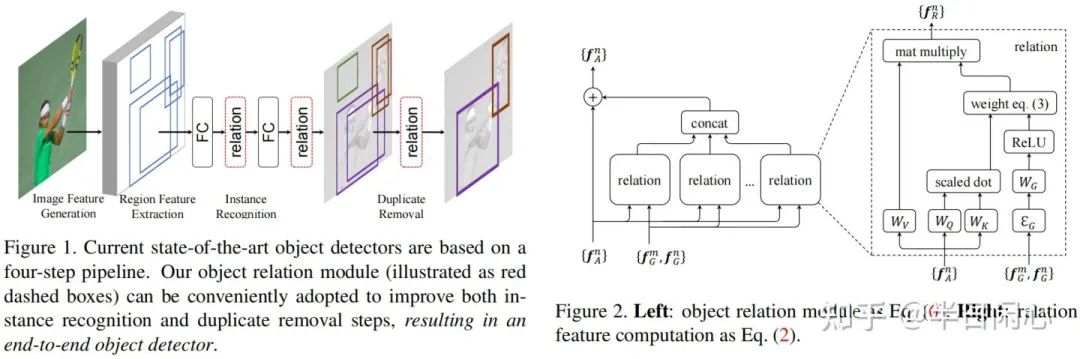
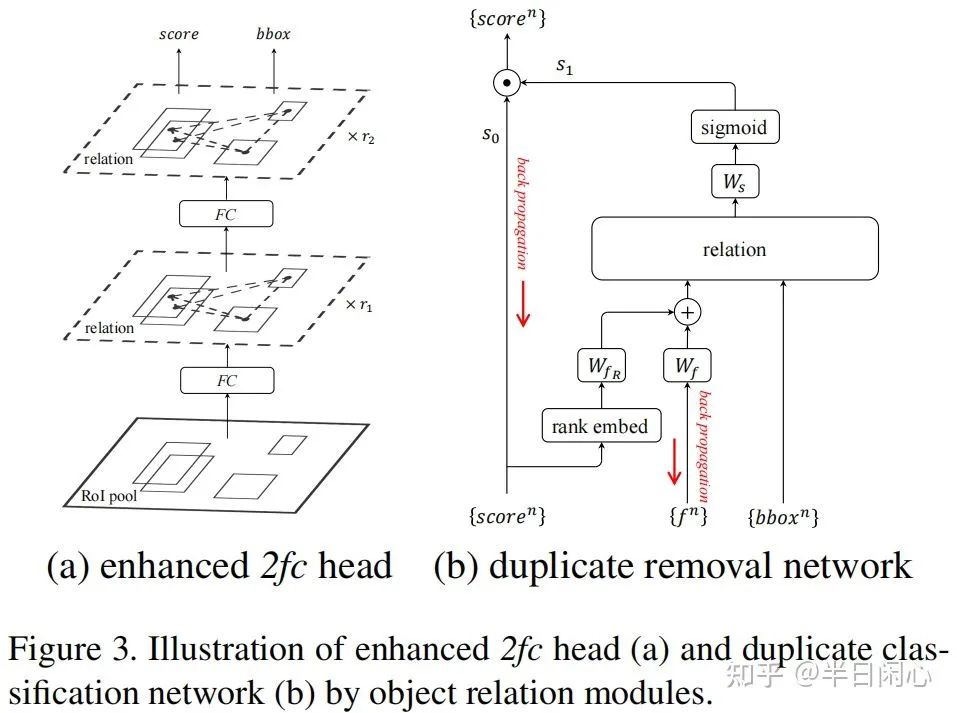
另外,论文提出了Duplicate removal network(DRN)代替nms,实现端到端训练。参考下图,DRN的思路是匹配到同一个GT的proposal,只取iou最大的,其他都是duplicate。DRN模块里面有个attention,让匹配到同一个GT的proposal只有iou最大的那个s1是1,其余是0。score是前景置信度,0-1之间,这里做了rank embed,根据score的大小降序排序,赋值范围是[1,N]。
《End-to-End Object Detection with Transformers》ECCV2020[6]
鼎鼎大名的DETR,借鉴了隔壁NLP的transformer,跟上文提到的《End-to-end people detection in crowded scenes》基于一样的方式,基本就是把LSTM部分改成了transformer。由于transformer同时输出结果的特性,作者默认DETR固定输出100个预测结果,如果没有那么多目标,则多出来的预测结果为空。同样通过匈牙利算法做label assignment。
后面基于transformer的XXDert/SwinXX不一一介绍了。coco的最高记录不断被刷新,可见transformer之强悍。
《Pix2seq: A Language Modeling Framework for Object Detection》[7]
此处不得不提pix2seq,已经不是借鉴隔壁NLP了,是把det套在NLP上。把GT的类别,坐标都看作词汇,一个一个输出。把bbox的位置离散化成“词汇表”,例如x方向的位置,离散成600个词汇,每个词汇表示图片中x方向的特定位置。Loss函数统一只用交叉熵。
表现虽然一般,但更加表明了序列模型的通用性,不同属性构造成序列进行预测。
上面几篇论文都是从NLP借鉴过来,LSTM - attention - transformer。他们都有一个特点,backbone能捕获全局特征,one-to-one做label assign没有任何违和感。而CNN这边many-to-one的label assign做了这么多年,看到transformer搞det效果不错,结构还优雅。也做了类似的尝试。
《End-to-End Object Detection with Fully Convolutional Network》CVPR2021[8]
从标题就看出对DETR的致敬,简称DeFCN。many2one的匹配策略是无法摆脱nms的关键,只有采用one2one的匹配策略才能摆脱nms。
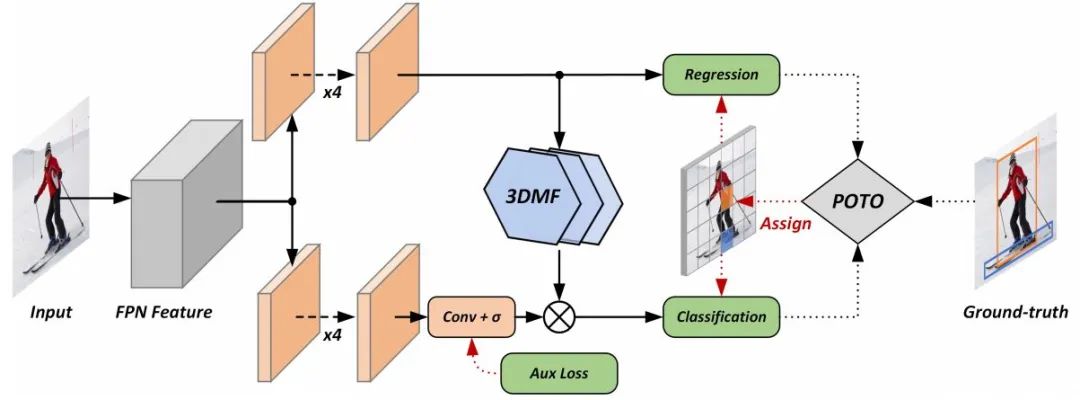
POTO(Prediction-aware One-To-One)的label assign与DETR设计几乎一样。
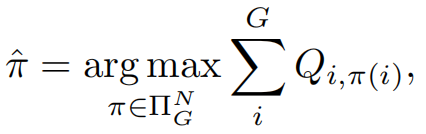
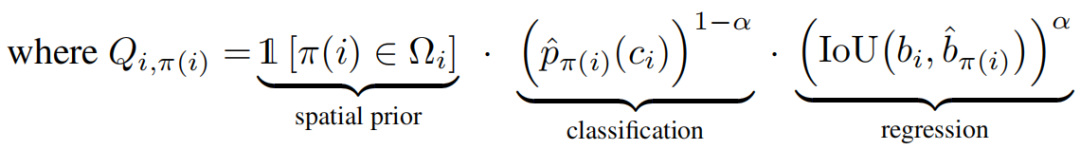
Π是所有预测instance与GT的one2one匹配方案的集合,Π_hat是这个集合里面是Q之和最大的方案。Spatial prior是GT外接框所对应的feature map区域=1,其他区域=0,人为的限定了匹配的proposal必须在GT框内找。classification是预测类别的交叉熵,regression是定位的iou值。α是超参数。通过匈牙利算法找到最佳的Π_h。
然而融合spatial prior、classification、regression做label assignment并不是本论文的首次提出,AutoAssign就曾融合多种信息做many2one的label assign,效果让人十分惊艳。
作者意识到卷积网络结构天然更适合many2one,因为one2one的匹配让feature map变得sharp,激活的feature与其四周有明显的变化,不然容易出现duplicated predictions,显然attention结构更加擅长。针对CNN不够sharp,作者提出了3D Max Filtering(3DMF),通过max pooling抑制周围Q得分也很高的proposal。
另外one2one带来更少的正样本使更难收敛,作者增加了一个one-to-many auxiliary loss(Aux Loss)。
类似基于FCN的nms-free的工作还有OneNet[9],PSS[10]这里不展开介绍了。
nms-free的现状与未来
nms-free已经不单单只有结构简单,精度也追上来了。det的工程研发变得越来越简单。从结构上,类似模板匹配的CNN,天然不适用于one2one的匹配方法,本文介绍了RelationNet和DeFCN对此问题的两个解决方案。基于Transformer的模型天然没有这样的问题。没有后处理的det未来,也许FCN已经支撑不起来了,也许未来更多是CNN + transformer/MLP/XX的方法,CNN慢慢成为特征提取或者筛选的手段。
考虑工程落地,transformer频繁reshape对一些硬件不太友好。纯CNN的模型结构依然是首选,而纯CNN的det,nms还是很难被取代。
参考论文链接来源readpaper,强推一波,非利益相关。
参考
^Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR2019 https://readpaper.com/paper/2962677013
^Arbitrary-Oriented Scene Text Detection via Rotation Proposals https://readpaper.com/paper/3106228955
^Detection in Crowded Scenes: One Proposal, Multiple Predictions .CVPR2020 https://readpaper.com/paper/3035323039
^End-to-end people detection in crowded scenes. CVPR2016 https://readpaper.com/paper/607748843
^Relation Networks for Object Detection. CVPR2018 https://readpaper.com/paper/2964080601
^End-to-End Object Detection with Transformers. ECCV2020 https://readpaper.com/paper/3096609285
^Pix2seq: A Language Modeling Framework for Object Detection https://readpaper.com/paper/3199245537
^End-to-End Object Detection with Fully Convolutional Network. CVPR2021 https://readpaper.com/paper/3111272232
^What Makes for End-to-End Object Detection?. ICML2021 https://readpaper.com/paper/3179092682
^Object Detection Made Simpler by Eliminating Heuristic NMS https://readpaper.com/paper/3125728987
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-PyTorch交流群成立
扫码添加CVer助手,可申请加入CVer-PyTorch 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如PyTorch+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号



