MIT媒体实验室:基于情绪分析构建影片情感弧线,预测观众反响
MIT媒体实验室的Eric Chu和Deb Roy在ICCV 2017研讨会上发表了《Audio-visual Sentiment Analysis for Learning Emotional Arcs in Movies》,对影片的视频和音频进行微观层面的情绪分析,基于这些微观层面的情绪分析,构建宏观层面的情感弧线,并对情感弧线进行聚类,以此预测观众的参与度。
数据集
为这个问题选用数据集,很自然就会想到电影。事实上,研究人员确实选用了Films Corpora(电影语料库),该数据集包含509部好莱坞电影。
除了好莱坞电影之外,研究人员还选用了Shorts Corpora(短片语料库),该数据集包含取自Vimeo的“Short of the Week”(每周最佳短片)频道的1326部短片。这些短片由电影制作人和作家选出,每部的时长在30秒到30分钟之间,中位值为8分25秒。
研究人员引入Vimeo短片是想探寻电影和新媒体之间可能存在的叙事差异。另外,Vimeo短片也为建模社交网络上流行的短视频提供了途径,而Vimeo短片的评论数也能作为衡量用户参与度的指标。
以上是宏观层面所用的数据集,微观层面,需要对视频和音频进行情绪分析。因此还需要寻找情绪分析的视频和音频数据集,以便训练模型。
由于大部分的情绪分析方面的研究都是基于文本的,而音视频方面的数据集不是很多。因此其实没有多少选择的余地。
由于没有合适的用于情绪分析的视频数据集,因此研究人员转而使用了图像数据集(机器学习视频的一个常用变通方法就是将视频转化为一帧帧图像)Sentibank。Sentibank包括差不多50万图像,每一个图像使用一个形容词和名词对加以标签,例如“迷人的房屋”,“丑陋的鱼”,总共有1533个形容词和名词对。这种形容词和名词对被称为情感二元概念(emotional biconcept)。SentiWordnet辞典将每个二元概念映射为情绪分析值。
用于情绪分析的音频数据集有Million Song和Last.FM等。不过这些数据集不是很符合研究人员的需求(比如Last.FM数据集比较小),所以研究人员最终基于Spotify API构建了数据集。
方法
音频情绪分析
研究人员基于时长为20秒的音频剪辑建立模型,因为一般20秒已足以表达情绪。
研究人员用96位的梅尔声谱图表示音频样本,网络架构基于Choi等2016年发表的论文《Automatic tagging using deep convolutional neural networks》(基于深度卷积神经网络的自动标签),其中使用了配备ELU和批量归一化的5个卷积层,之后是一个全连接层。
研究人员选择数据集之中效价(valence,衡量情绪的强度)高于0.75或低于0.25的样本,符合这一标准的总共有大约20万样本。数据集依照0.8、0.1、0.1的比例分为训练集、验证集、测试集。
模型在测试集上的表现如下表所示。

视频情绪分析
如前所述,视频情绪分析问题被转化为视频帧(图像)分析问题。研究人员以每秒一帧的频率进行取样,通过缩放、中央裁切将视频帧转化为256x256的图像。然后将图像交给模型进行情绪分析。
对图像进行情绪分析的模型就是普通的基于AlexNet架构的深度卷积神经网络。虽然一些更先进的架构可能可以提高精确度,但因为这些分类的结果是用来构建高层的情感弧线的,因此这一相对简单的模型已经足够了。不过,研究人员倒是使用了一些最近的研究成果提出的部件,包括PReLU激活单元、批量归一化、ADAM。
研究人员将模型的学习率设定为0.01,batch大小设定为128,批量归一化衰减设定为0.9。和音频的情况类似,数据集依照0.8、0.1、0.1的比例分为训练集、验证集、测试集。
模型在测试集上的表现如下表所示。

情感弧线构建
基于视频(图像)的情绪分析,可以构建视频情感弧线。下图左为原始的情感弧线。研究人员通过汉宁窗(Hann window)平滑曲线,汉宁窗的大小是0.1 * n,其中n为视频的长度。
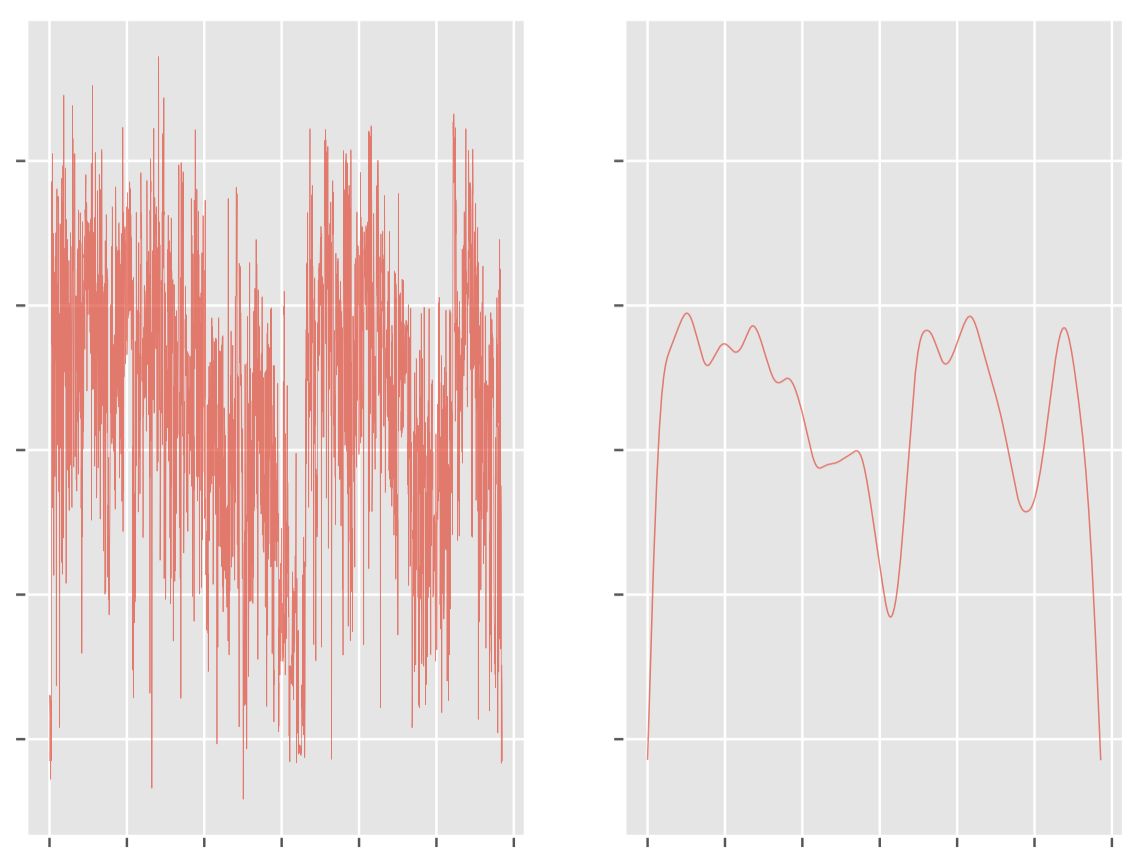
同理可以构建音频情感弧线。由于音频情绪分析的模型基于20秒的音频剪辑训练,因此音频情感弧线也使用一个20秒的滑动时窗(sliding window)。
音频情感弧线的构建还有一点需要注意的。如前所述,音频情绪分析的模型是通过基于Spotify API的数据集训练的。然而,基于Spotify API取得的音乐和电影中的配乐实际上不一定完全一致。因为电影中配乐响起的时候,很可能同时存在背景噪音或人物交谈的语音。或者,为了效果,配乐可能突然中断,形成静默的场景。因此,基于Spotify的音乐训练的模型,应用于电影配乐,多少有些问题。因此,研究人员基于Gal等于2016年发表的论文《Dropout as a bayesian approximation: Representing model uncertainty in deep learning》(作为贝叶斯近似的dropout:在深度学习中表示模型不确定性)中提出的方法,定义了预测的可信度。
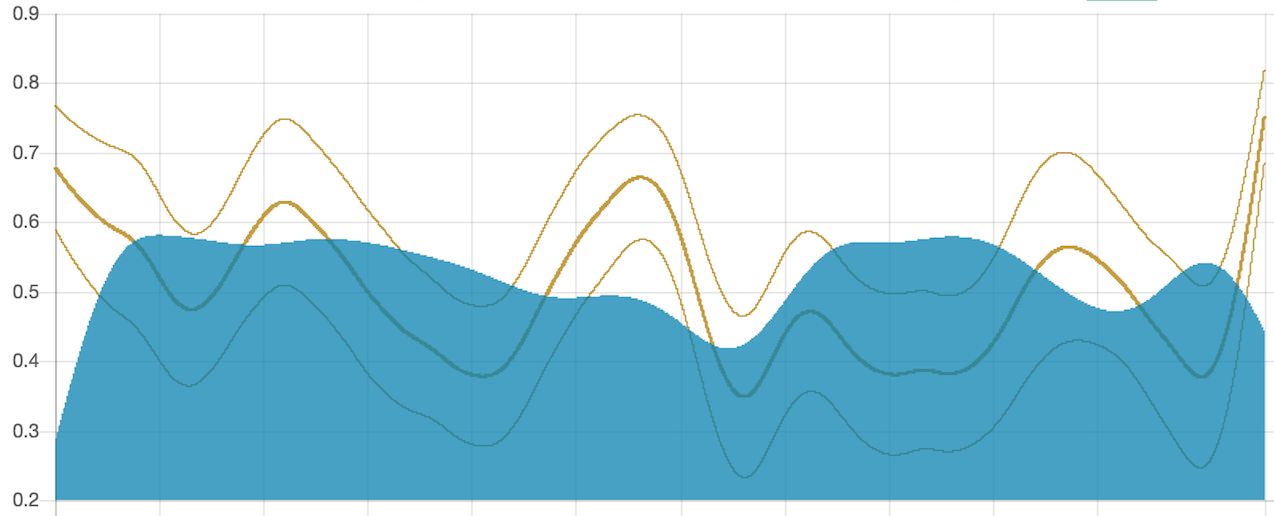
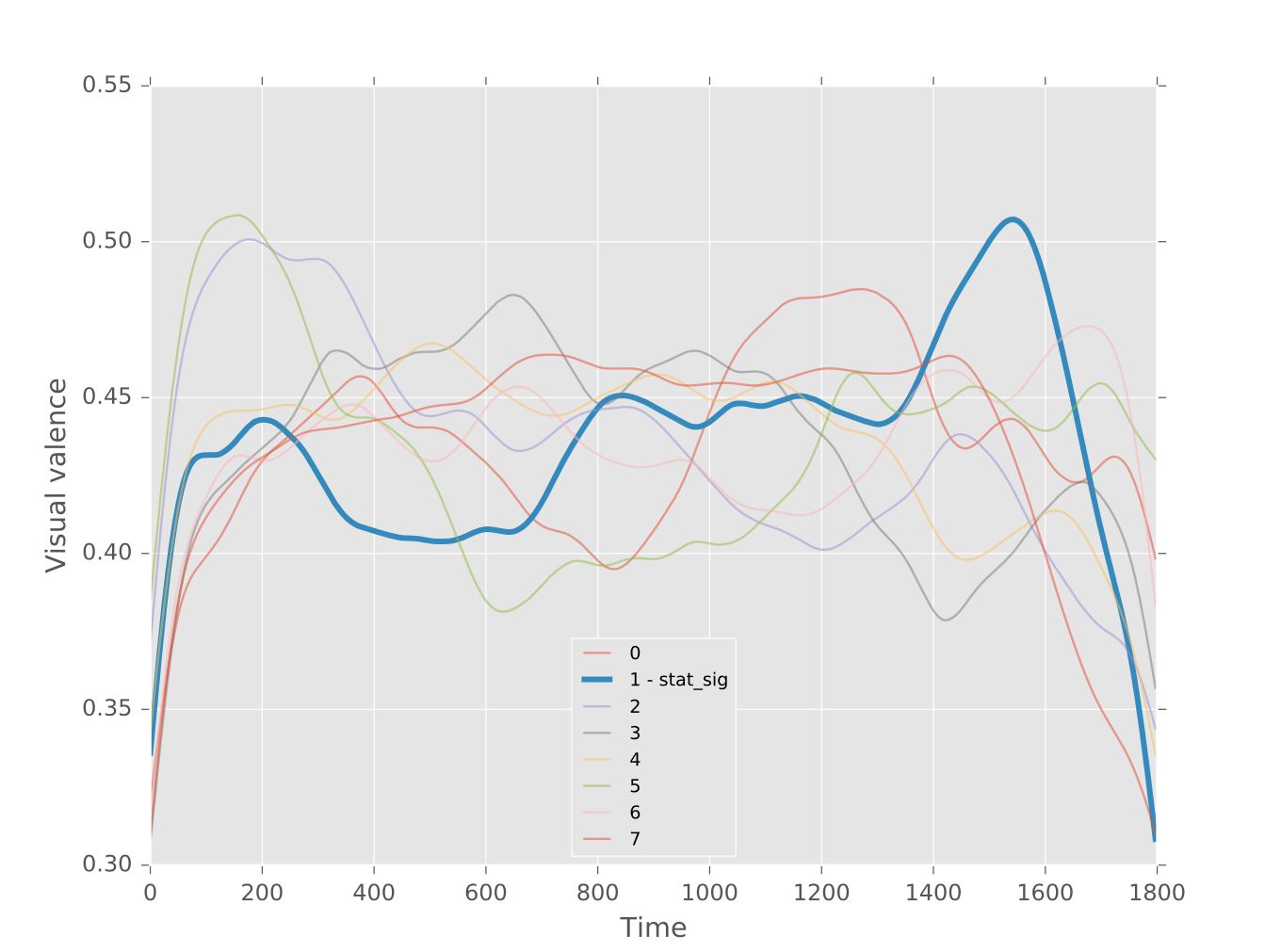
下图为电影《Her》的情感弧线,图中的几条黄线代表可信度不同的音频弧线,蓝色代表视频弧线。
情感弧线聚类
聚类问题,最容易想到的是使用K值方法,基于情感弧线的欧式距离。然而,这一方法存在两个问题:
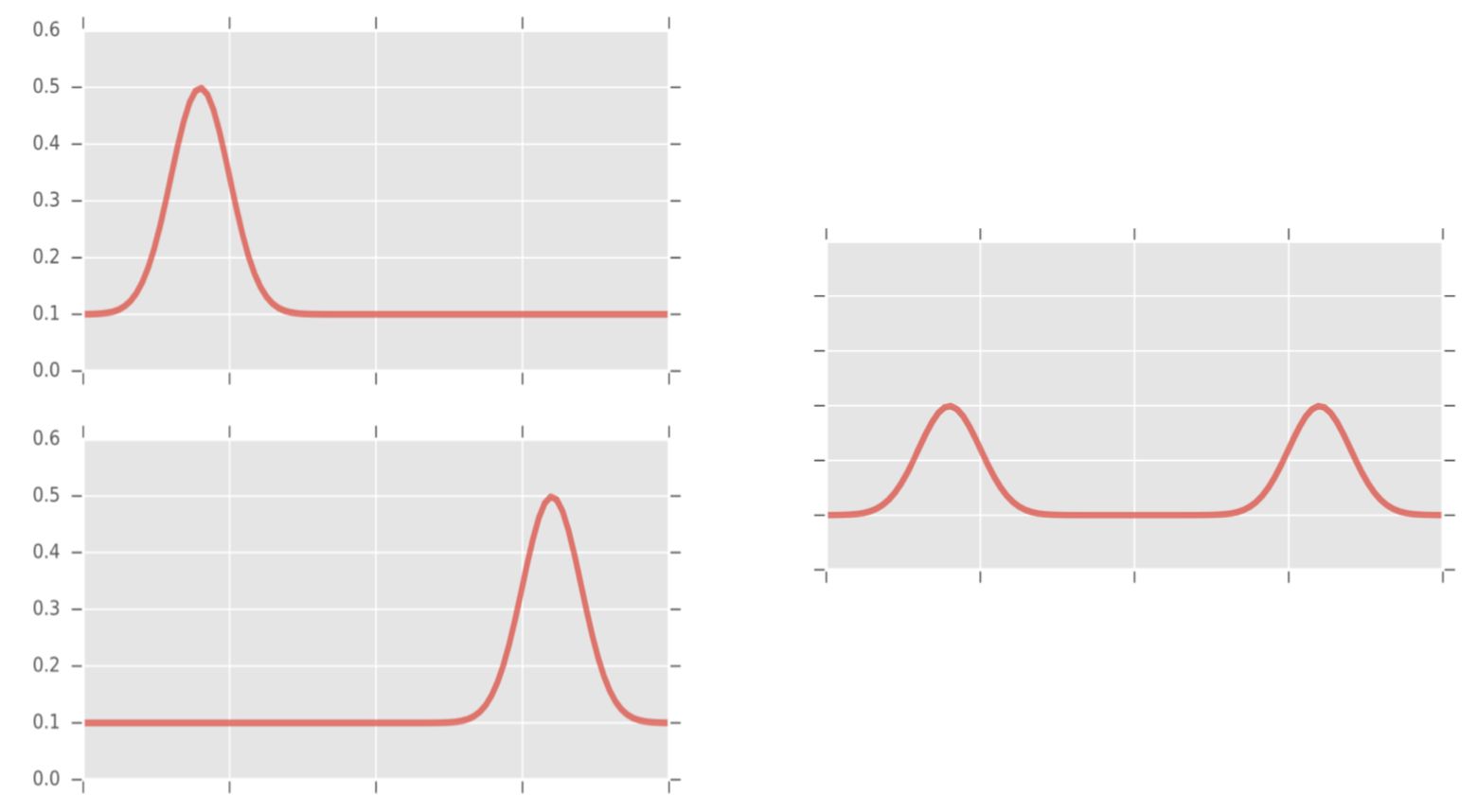
弧线的均值可能并不利于寻找能精确地表示聚类形态的几何中心。例如,下图左侧的两条弧线的均值弧线会有两个高峰,而不是一个。
两条弧线间的欧氏距离并不一定反映形态间的相似性。还是下图左侧的两条弧线,这两条弧线在形态上具有某种相似性(一个高峰),但是它们的欧式距离可能会很大。
当我们厘清基于欧式距离的K均值方法的缺陷的时候,我们离合适的聚类方法就很近了。
既然均值不好用,那我们就用中位值。研究人员使用的正是基于中位值的k-medoids方法。
上图左侧两条弧线很相似,都有一个类似的高峰,只不过高峰出现的时间很不一样,因此欧式距离没法表达两者之间的这种相似性。那么,我们把这两条弧线弯曲一下,将高峰对齐,不就可以了吗?
没错,研究人员使用的正是动态时间弯曲(dynamic time warping,DTW)。上图左侧的两条弧线之间的欧式距离很大,而DTW距离却是0。
不过,DTW也不是毫无问题。上图左侧的两条弧线之间的DTW距离是0,也就是说,模型认为这两条情感弧线是等价的。但实际上,这两条情感弧线还是有一些差别的。上方的情感弧线可能意味着情绪的高峰出现在情感时刻的开始,而下方的情感弧线可能意味着情绪的高峰出现在情感时刻的结束,这两者的意义很可能是不一样的。
所以,我们需要给弯曲加上一点限制,如果两条情感弧线的峰谷出现的时间点差异很大,那我们就不弯曲了。换句话说,我们需要将弯曲的范围限制在一定时间段内。
因此,研究人员使用了LB Keogh限定了弯曲的范围。弧线A和B的LBKeogh距离由下式给出:
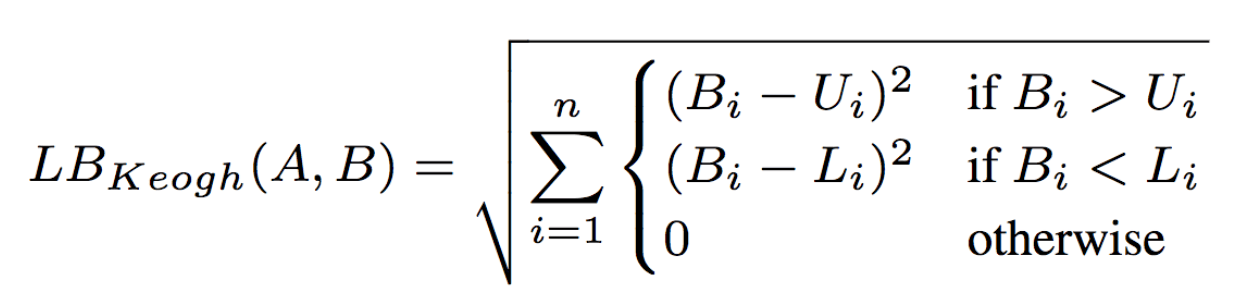
其中,Ui和Li分别为封装原时间序列的上界和下界,定义分别为Ui = max(Ai-r : Ai+r),Li = min(Ai-r : Ai+r)。
实际上,使用LB-Keogh限定了弯曲的范围之后,还提高了DTW的性能,可谓是一举两得了。
K值的选定,研究人员选择了常用的肘方法(elbow method)。肘方法的基本思想是根据聚类的凝聚程度选择合适的K值。在理性情况下,图像上会有一个清楚的奇拐点,也就是“肘”,在该处,增加聚类的数目将减少聚类的凝聚度。肘的存在暗示聚类是合理的,肘即为合理的K值。
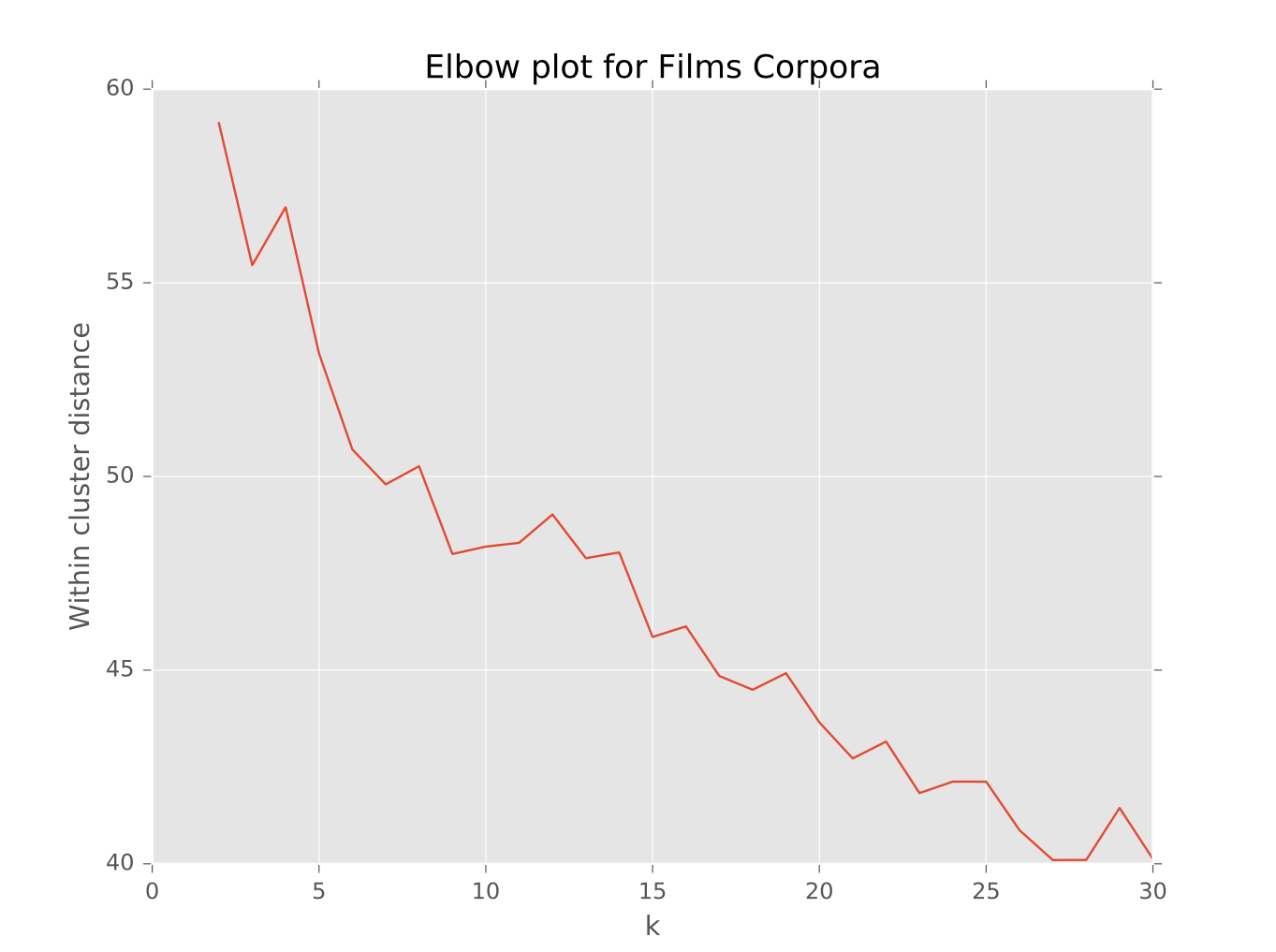

研究人员还试验了肘方法在K均值上的效果,找不到清晰的肘。这坚定了研究人员选择k-medoids方法和DTW信心。
参数细节
首先,研究人员剔除了过长的视频(超过10000秒的电影和1800秒的短片)。
其次,研究人员Z归一化了情感弧线,以更好地展现弧线的总体形态。
最后,研究人员选定r = 0.025 * n作为LB-Keogh的窗口大小。这一参数的选定基于{0.01, 0.015, 0.02, 0.025, 0.03, 0.035, 0.04} * n的超参数搜索。不过,实际上,这些参数的效果差别都不大。
评估
研究人员分别从微观和宏观两个层次评估了模型的表现。
微观
从微观上说,研究人员想知道模型提取的那些情感的峰谷准确率有多高。
要评估模型的准确率,最直接的做法应该是与人类标注作比较。然而,标注整部电影的成本太高了,更别说标注多部电影了。因此研究人员采用了一个变通的做法,根据情感弧线的峰谷,从视频中提取相应的剪辑,并让人类标注这些剪辑。
具体而言,研究人员从168部电影中各自提取了1至7则剪辑,总共得到对应于音频峰谷和视频峰谷的剪辑220、253、230、259则。研究人员让CrowdFlower平台上的人观看剪辑,然后回答关于剪辑的情感内容的问题。每则剪辑分别由3个人标注。标注者将基于视频的积极程度和消极程度评分(1分为最消极、7分为最积极)。研究人员将超过4分的评分认定为积极,将均分超过4分的剪辑认定为积极,消极评分的认定同理。
基于以上标注,研究人员定义准确率为:
(|峰 & 积极 | + |谷 & 消极|) / 剪辑数
换句话说,一个精确地提取的剪辑:
是一个提取自弧线的高峰的剪辑,并且被标注为积极;
或者是一个提取自弧线的低谷的剪辑,并且被标注为消极。
最终的准确率结果如下表所示:
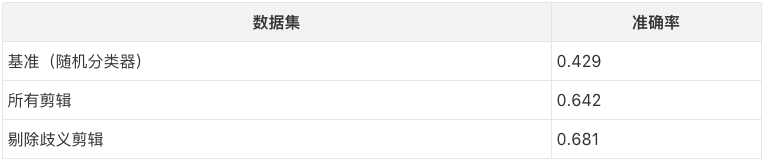
音频弧线的准确率如下表所示(已剔除歧义剪辑,下同):
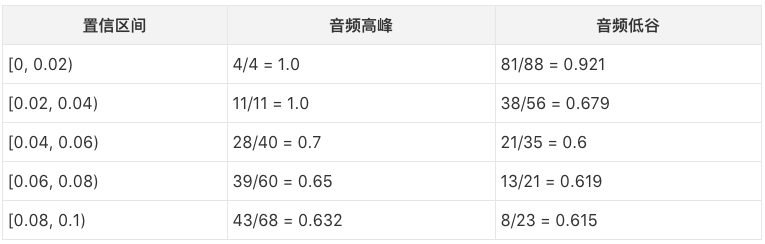
从上表我们可以看到,较低的可信度对应较高的准确率。
研究人员还分别统计了音、视频,峰、谷,及两者的组合所对应的准确率:
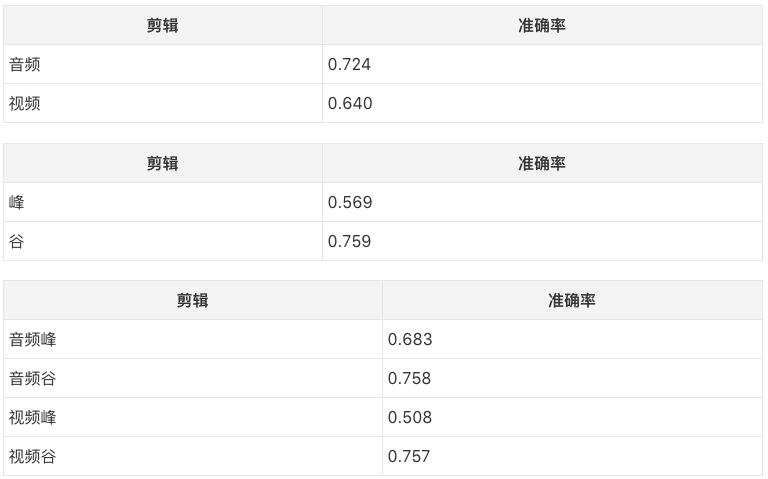
从上表可以看出,视频峰的准确率特别低。为了查探准确率特别低的原因,研究人员使用Bamman等人于2014年在《Learning latent personas of film characters》中提出的方法给影片标注了类型。然后统计了不同类型的准确率:
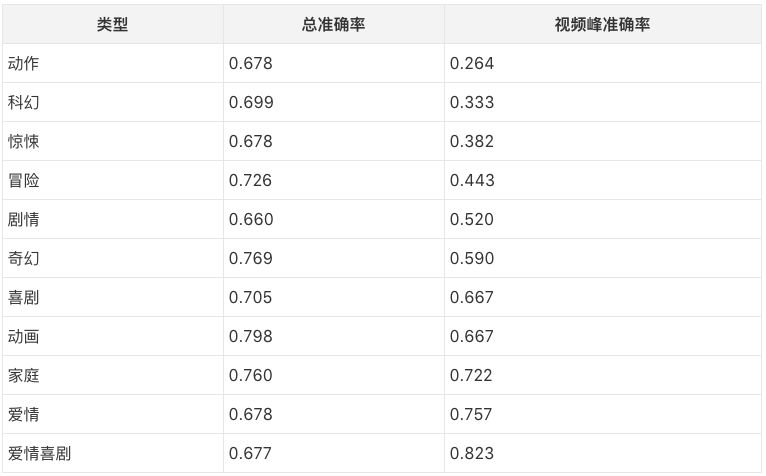
上表按照视频弧线的情感高峰的准确率排列。原来视频峰的准确率特别低的原因是某些类型的视频峰的准确率太低,拉低了总的视频峰准确率。
研究人员手工分析了动作片、科幻片和惊悚片(准确率最低的三个类型)中预测错误的视频峰剪辑,发现其中包含很多血浆、死亡的场景,这些场景基本上不可能在训练模型进行情绪分析的Sentibank数据集中出现(Sentibank数据集中的图片取自Flickr的公开图片)。
为了进一步提高预测的准确率,研究人员构建了组合音频、视频信息的模型。
研究人员基于以下特征构建了一个线性回归模型:
视频效价
(视频效价) - (电影的视频效价均值)
(电影的视频效价的最大值) - (视频效价)
(视频效价) - (电影的视频效价的最小值)
视频效价的尖峰度
音频效价
(音频效价) - (电影的音频效价均值)
(电影的音频效价的最大值) - (音频效价)
(音频效价) - (电影的音频效价的最小值)
音频效价的尖峰度
音频置信区间
电影时长
电影嵌入
上面的大多数特征都很自然,总的思路是基于整部电影来衡量效价(基于最大值、最小值、均值和尖峰度)。其中,尖峰度(peakiness)的定义如下:给定弧线a(音频或视频)上的一点i,函数p(a, i, r)逼近i附近的斜率和均值,r为ai附近的时窗大小。函数p返回4个值:
ai-1 - ai-r (与i左侧的斜率成比例)
ai+r - ai+1
mean(ai-r:i-1) (i左侧的均值)
mean(ai+1:i+r)
因此,尖峰度覆盖了峰、谷和奇拐点。上一节中提到,研究人员选择了r = 0.025 * n作为LB-Keogh的窗口大小。因此这里也使用了同样的窗口大小。
另外 ,前文提到不同的电影类型对预测准确度(特别是视频峰的预测准确度)有所影响。为了体现这一影响,研究人员使用电影嵌入(movie embedding)来大致地总结电影的情感内容。研究人员用上一节提到的二元概念分类器的倒数第二个激活表示每一帧,接着基于10%电影块对这些激活取平均值,得到10 x 2048矩阵。然后,研究人员构建了一个2048维向量,附加上10 x 1的特征向量,以便将电影嵌入转化为特征。对这些电影嵌入进行聚类后,爱情、冒险、奇幻、动画类型清晰可见。
研究人员评估了以上的音视频组合模型,达到了0.894的精确率。为了进一步验证模型的有效性,研究人员进行了一些消融测试,包括去除某些特征(尖峰度、电影嵌入),以及仅使用音频或视频特征。消融测试表明,尖峰度和电影嵌入对提高模型的预测准确度很有帮助。
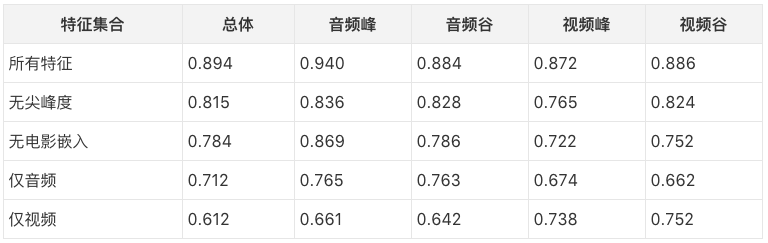
宏观
很遗憾,宏观层面的评估仅仅基于视频弧线。理论上说,综合音视频信息构成的弧线应该能有更好的表现,就像微观层面结合了音频和视频的模型取得了更好的表现一样。然而,研究人员试验了基于混合模型构建的弧线,这些弧线的聚类无法得出有意义的分类。研究人员认为导致这一现象有两个原因:
覆盖电影整个音视频空间的标准答案(ground truth)数据的稀疏性
数据集的尺寸过小
研究人员构建了一个回归模型预测Vimeo短片收到的评论数目,该模型使用短片的视频情感弧线聚类和视频的元信息作为输入。
研究人员总共创建了9个模型,[2, 10]区间内的每个整数分别为9个模型的K值。所有的模型都使用相同的元信息特征。研究人员基于整个数据集检查了每个模型的各个特征是否是评论数的统计学上显著的预测因子。当一个特征的p值小于0.05时,该特征被认为是统计学上显著的。
下表为k=8时的结果。
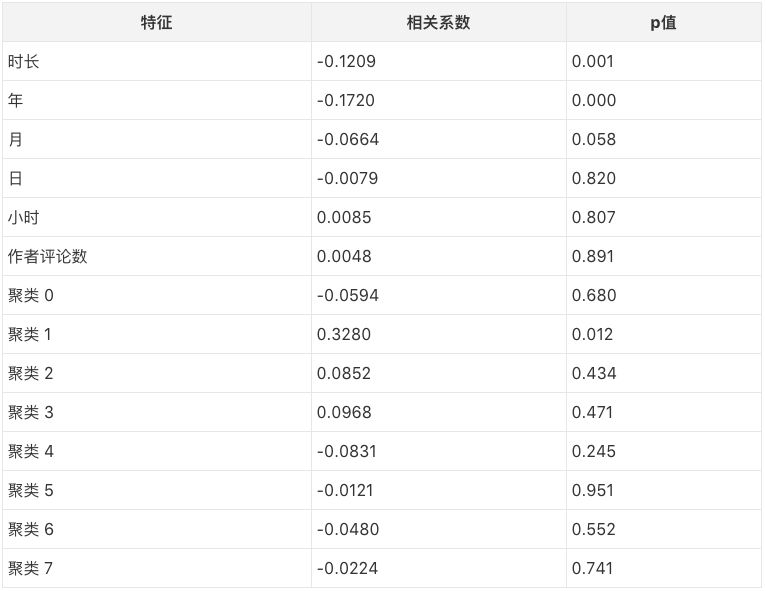
从上表中我们可以看出,时长和年是统计显著的预测因子。这并不出人意料,长视频更可能收到较少的评论(很多人没耐心看完),而较早上传的视频更可能收到较多的评论(评论需要时间积累)。
上表中,聚类1同样是统计显著的预测因子,并且事实上是相关系数最大的预测因子。这一聚类表示的是伊卡洛斯情感弧线——先扬后抑,以陡峭的下降收尾。这一类情感弧线很可能刻画了令人悲伤的影片,因此很多人在观看后会评论以排解负面情绪。
数据集
研究人员构建的数据集可以通过以下地址下载:
Spotify音频特征包含60万首音乐的音频特征,其中附带了30秒音乐样本的链接,可以通过Spotify API获取这些音乐样本。
Spotify的MSD匹配包含上一个数据集中的音乐与MSD(Million Song数据集)的匹配结果,以便利用MSD中更多的音频特征。
视频剪辑标注包含约1000则30秒视频剪辑的情感标签,这些剪辑取自约175部电影。其中附带了视频剪辑的下载链接。每个剪辑由3个众包人员标注,标注内容见后文。
聚合视频剪辑标注为以上数据集的聚合版本。
视频剪辑标注的众包人员被要求回答以下4个和剪辑的情感内容有关的问题:
视频剪辑有多积极/消极?(1分为最消极,7分为最积极)
你对上一个问题的回答有多自信?(1分为最不自信,10分为最自信)
这一视频剪辑包含或传达了哪一种或哪几种情感?(选择所有适合的或者“以上都不是”)选项:愤怒、期待、恶心、恐惧、喜悦、悲伤、惊讶、信任,以上都不是
下面哪一个或那几个因素让你做出上一题的决定?(选择所有适合的)选项:音频、对话、视觉(动作、场景、设定)
以上数据集储存在AWS S3上,如访问AWS S3网速较慢(或无法访问),可关注论智(jqr_AI)微信公众号,留言“情感弧线”(不含引号)获取国内网盘下载地址。







