无模型强化学习研究综述 (中文版)

强化学习(ReinforcementLearning,RL)作为机器学习领域中与监督学习、无监督学习并列的第三种学习范式,通过与 环境进行交互来学习,最终将累积收益最大化.常用的强化学习算法分为模型化强化学习(ModelGbasedReinforcementLearG ning)和无模型强化学习(ModelGfreeReinforcementLearning).模型化强化学习需要根据真实环境的状态转移数据来预定义 环境动态模型,随后在通过环境动态模型进行策略学习的过程中无须再与环境进行交互.在无模型强化学习中,智能体通过与 环境进行实时交互来学习最优策略,该方法在实际任务中具有更好的通用性,因此应用范围更广.文中对无模型强化学习的最 新研究进展与发展动态进行了综述.首先介绍了强化学习、模型化强化学习和无模型强化学习的基础理论;然后基于价值函数 和策略函数归纳总结了无模型强化学习的经典算法及各自的优缺点;最后概述了无模型强化学习在游戏 AI、化学材料设计、自 然语言处理和机器人控制领域的最新研究现状,并对无模型强化学习的未来发展趋势进行了展望.
http://www.jsjkx.com/CN/article/openArticlePDF.jsp?id=19779
强化学习又称增强学习,在学术界对 RL与统计学、优化 理论和其他数学学科的互动研究有了突破后,RL 逐渐成为 了各 领 域 的 研 究 热 点[1]. 随 着 深 度 学 习 (DeepLearning, DL)[2]的兴 起,融 合 深 度 神 经 网 络 和 RL 的 深 度 强 化 学 习 (DeepReinforcementLearning,DRL)[3]技术的研究和应用日 益增多. RL是一种不同于监督学习的学习方式.监督学习通过 外部提供的标注数据集进行学习,每一个样本都是训练中的 “监督者”[4].而 RL中并不存在这样的“监督者”,因此 RL提 出了奖励信号这个概念.它与监督学习中的监督信号不同, 为了考虑智能体(agent)整体的累积收益,它是 被 延 迟 反 馈 的.同时,监督学习的训练数据之间一般是独立的,而 RL处 理的是序贯决策问题,每一步在顺序上都具有依赖关系. RL也是一种不同于无监督学习的学习方式.无监督学 习的主要目标是寻找未标注数据集中隐含的结构关系,而 RL 的目标是最大化累积收益.同时,无监督学习没有 RL 的奖 励信号,其数据之间一般也是独立的. 在实际应用中,根据agent是否通过与环境交互获得的 数据来预定义环境动态模型,将 RL 分为模型化强化学习和 无模型强化学习[5],具体如图1所示.
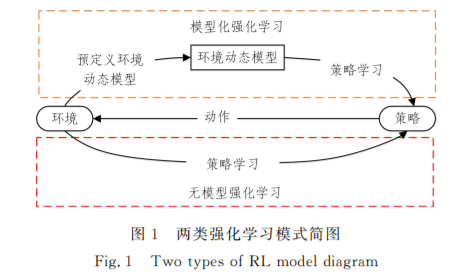
模型化强化学习指先在与环境交互的数据中创建环境动 态模型,然后基于该模型学习最优策略.它一般包含状态转 移预测和奖励预测两个独立模型.如果两个模型可以准确描 述真正的环境动态模型,那么当输入一个状态和动作时就不 需要与环境进行实时交互,可以直接基于模型预测得到新的 状态和动作奖励,从而极大地提高数据的利用率.但当面对 的问题具有复杂的状态动作空间时,准确估计环境动态模型 存在巨大挑战.尤其是在交互前期得到的数据较少时,环境 动态模型极易存在模型误差,利用不准确的环境动态模型进 行学习,极易导致双重近似误差[6].针对模型的准确性,有很 多改进算法被提出.例如,学习控制的概率推理方法(ProbaG bilisticInferenceforLearningControl,PILCO)[7],其将 环 境 动态模型建模为高斯过程(GaussianProcess,GP),但这种高 斯假设以 及 需 呈 特 定 指 数 形 式 的 奖 励 函 数 极 大 地 限 制 了PILCO 算法在复杂问题中的应用.之后,研究人员又提出了 基于最小二乘条件密度估计的模型化策略搜索方法(Model based PolicyGradients with Parameter based Exploration by Least squares Conditional Density Estimation)[5],但其仅在采样预算有限时具有良好效果,难以处 理高维度问题.面对各领域复杂的应用场景,模型化强化学 习若存在模型误差,其性能将远低于无模型强化学习[8].
无模型强化学习指agent与环境进行实时交互和探索, 并直接对得到的经验数据进行学习,最终实现累积收益最大 化或达到特定目标[4].无模型强化学习不需要拟合环境动态 模型,经过与环境的实时交互可以保证agent渐近收敛得到 最优解.然而,无模型强化学习通常需要大量的训练样本和 训练时间,因此如何提高数据利用率和学习效率是无模型强 化学习的研究重点.
本文将围绕无模型强化学习展开综述,首先介绍 RL 的 基础知识,然后归纳总结无模型强化学习的经典算法及相关 工作,最后概述无模型强化学习的研究进展,并对未来发展趋 势进行展望.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MFRL” 就可以获取《无模型强化学习研究综述》专知下载链接






