CVPR2018|DiracNets:无需跳层连接,训练更深神经网络,结构参数化与Dirac参数化的ResNet
来源:http://nooverfit.com/wp/
近年来深度网络结构的创新层出不穷:残差网络,Inception 系列, Unet,等等。微软的残差网络ResNet就是经典的跳层连接(skip-connection):
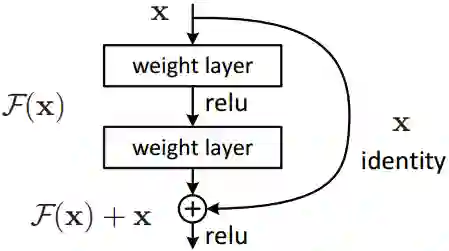
上一层的特征图x直接与卷积后的F(x)对齐加和,变为F(x)+x (特征图数量不够可用0特征补齐,特征图大小不一可用带步长卷积做下采样)。这样在每层特征图中添加上一层的特征信息,可使网络更深,加快反馈与收敛。
但是ResNet也有明显的缺陷:我们无法证明把每一层特征图硬连接到下一层都是有用的;另外实验证明把ResNet变“深”,不如把ResNet变“宽”, 即,到了一定深度,加深网络已经无法使ResNet准确度提升了(还不如把网络层像Inception那样变宽)。
于是,DiracNets试图去掉固定的跳层连接,试图用参数化的方法代替跳层连接:
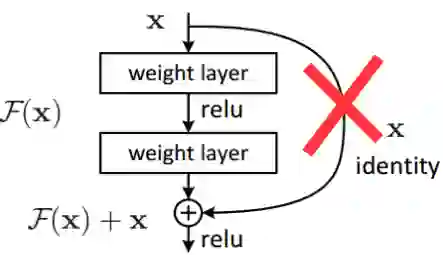
那么问题来了,我们怎么参数化这个被删除的跳层连接?使得新增的参数像卷积核窗口参数一样是可训练的?
有一点是确定的,我们知道F(x)+x 的对齐求和操作是线性的,卷积操作F也是线性的,所以,理论上F(x)+x可以合并成一个卷积操作(或者一个线性变换):
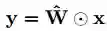
其中x即输入特征图,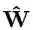

最后,让我们再把上式的参数拆分开来:
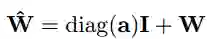
其中W即代表ResNet中的卷积操作的参数,I 即代表ResNet中的跳层操作的参数 。
有没有觉得 I 和单位矩阵很像? 你猜对了 ! I 就是由卷积窗口导出的单位参数矩阵,也叫Dirac delta变换,任何输入x经过这个I矩阵 的变换,其输出还是x本身。而diag (a) 也是一个可训练的向量参数,用来控制需要跳层连接的程度(需要单位矩阵的程度)。
现在我们看看这种参数化的ResNet是不是更灵活了?
如果diag(a)向量都是趋近于0的,那么I 单位矩阵就基本起不到作用, 那么跳层连接就被削弱了。这时原始的卷积操作W就认为占主导作用。
如果diag(a)向量都是趋近于1的,并且W参数都非常小,那么卷积操作就被削弱了,输出和输入的特征图x很相似。
通过训练diag(a),我们可以控制ResNet中的跳层操作和卷积操作两者的权重。而不是像传统ResNet,不得不硬连接加上一个跳层连接(无论有用或没用)。
代码实现上,PyTorch提供了许多灵活的方法,torch.nn.functional接口允许你人工指定各个参数矩阵:
import torch.nn.functional as F def dirac_conv2d(input, W, alpha, beta) return F.conv2d(input, alpha * dirac(W) + beta * normalize(W))
上面代码把参数矩阵对于之前说的拆分成两部分:
alpha * dirac(W) + beta * normalize(W)
幸运的是pytorch提供现成的计算dirac单位矩阵的函数(http://pytorch.org/docs/0.1.12/nn.html#torch.nn.init.dirac)
torch.nn.init.dirac(tensor)
如需深入研究,别错过源代码:
https://github.com/szagoruyko/diracnets
最后我们看看实验结果.
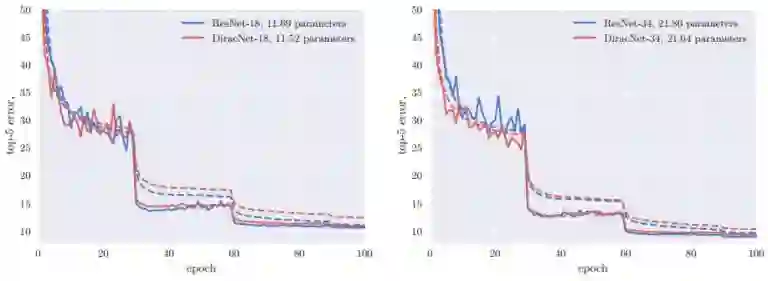
在同等深度的情况下,DiracNets普遍需要更多的参数才能达到和ResNet相当的准确率:
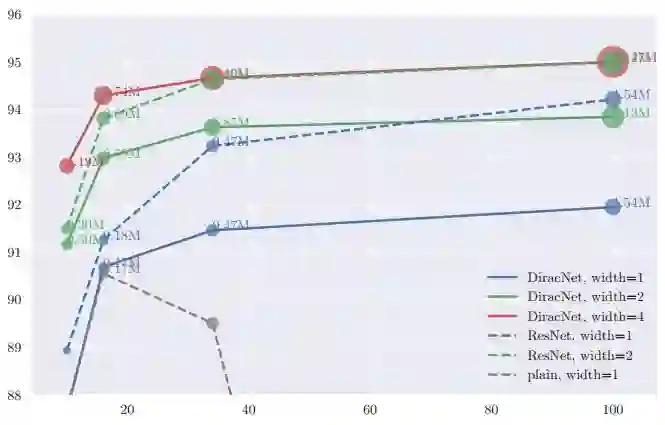
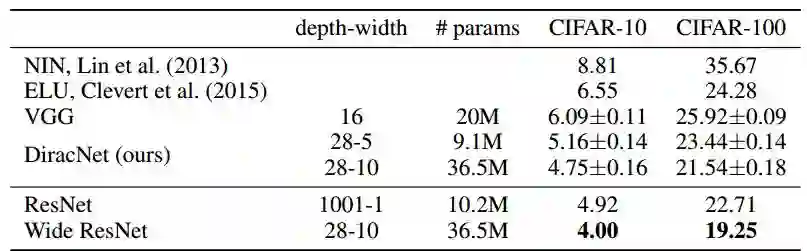
而如果不考虑参数数量,DiracNets需要较少的深度,就能达到ResNet需要很深的深度才能达到的准确率:
参考文献
https://arxiv.org/abs/1706.00388
https://github.com/szagoruyko/diracnets
https://arxiv.org/abs/1512.03385
https://zh.wikipedia.org/wiki/%E7%8B%84%E6%8B%89%E5%85%8B%CE%B4%E5%87%BD%E6%95%B0
http://pytorch.org/docs/0.1.12/_modules/torch/nn/functional.html
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
PS.极市平台正寻求与开发者视觉算法的合作,欢迎联系小助手(微信:Extreme-Vision)沟通合作~ 2018一起旺起来



