PyTorch 版 EfficientDet 比官方 TF 实现快 25 倍?这个 GitHub 项目数天狂揽千星

来源:机器之心

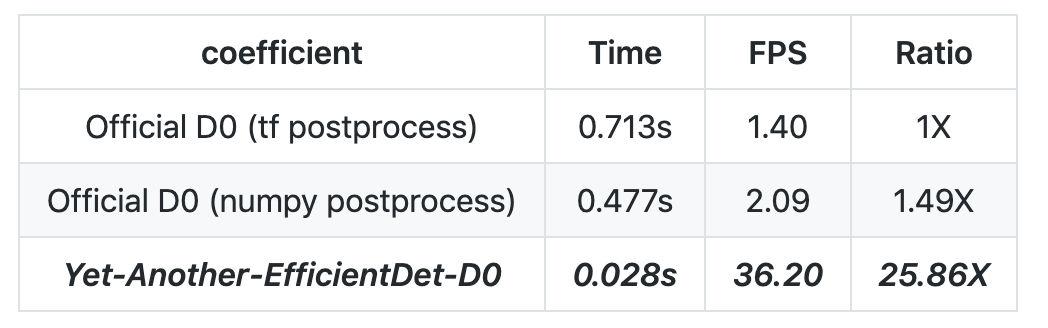

第二个项目的 BN 实现有问题:BatchNorm 是有一个参数,叫做 momentum,用来调整新旧均值的比例,从而调整移动平均值的计算方式的。
Depthwise-Separatable Conv2D 的错误实现。
误解了 maxpool2d 的参数,kernel_size 和 stride。
减少通道的卷积后面,没有进行 BN
backbone feature 抽头抽错了
Conv 和 pooling,没有用到 same padding
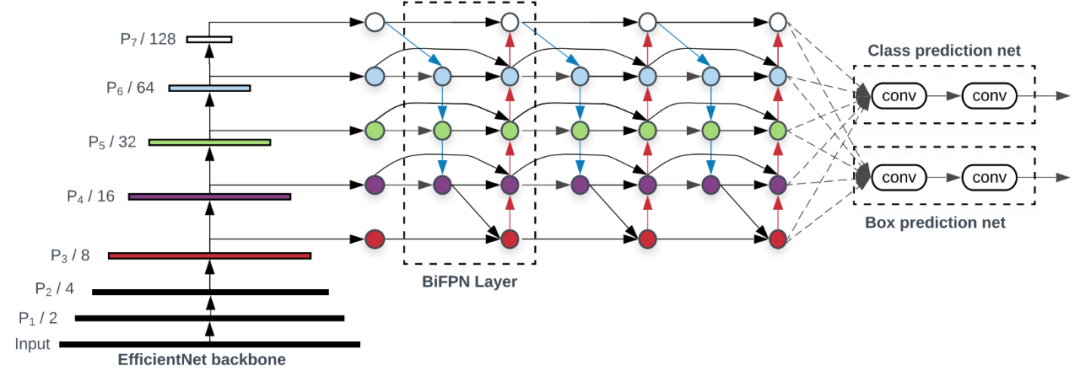
没有能正确的理解 BiFPN 的流程

!git clone https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
import os
os.chdir('Yet-Another-EfficientDet-Pytorch')!pip install pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml
!pip install torch==1.4.0
!pip install torchvision==0.5.0!mkdir weights
os.chdir('weights')
!wget https://github.com/zylo117/Yet-Another-Efficient-Pytorch/releases/download/1.0/efficientdet-d0.pth






# create a yml file {your_project_name}.yml under 'projects'folder
# modify it following 'coco.yml'
# for example
project_name: coco
train_set: train2017
val_set: val2017
num_gpus: 4 # 0 means using cpu, 1-N means using gpus
# mean and std in RGB order, actually this part should remain unchanged as long as your dataset is similar to coco.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
# this is coco anchors, change it if necessary
anchors_scales: '[2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]'
anchors_ratios: '[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]'
# objects from all labels from your dataset with the order from your annotations.
# its index must match your dataset's category_id.
# category_id is one_indexed,
# for example, index of 'car' here is 2, while category_id of is 3
obj_list: ['person', 'bicycle', 'car', ...]# train efficientdet-d0 on coco from scratch
# with batchsize 12
# This takes time and requires change
# of hyperparameters every few hours.
# If you have months to kill, do it.
# It's not like someone going to achieve
# better score than the one in the paper.
# The first few epoches will be rather unstable,
# it's quite normal when you train from scratch.
python train.py -c 0 --batch_size 12# train efficientdet-d1 on a custom dataset
# with batchsize 8 and learning rate 1e-5
python train.py -c 1 --batch_size 8 --lr 1e-5# train efficientdet-d2 on a custom dataset with pretrained weights
# with batchsize 8 and learning rate 1e-5 for 10 epoches
python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10 \
--load_weights /path/to/your/weights/efficientdet-d2.pth
# with a coco-pretrained, you can even freeze the backbone and train heads only
# to speed up training and help convergence.
python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10 \
--load_weights /path/to/your/weights/efficientdet-d2.pth \
--head_only True


登录查看更多
相关内容
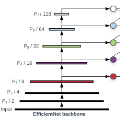
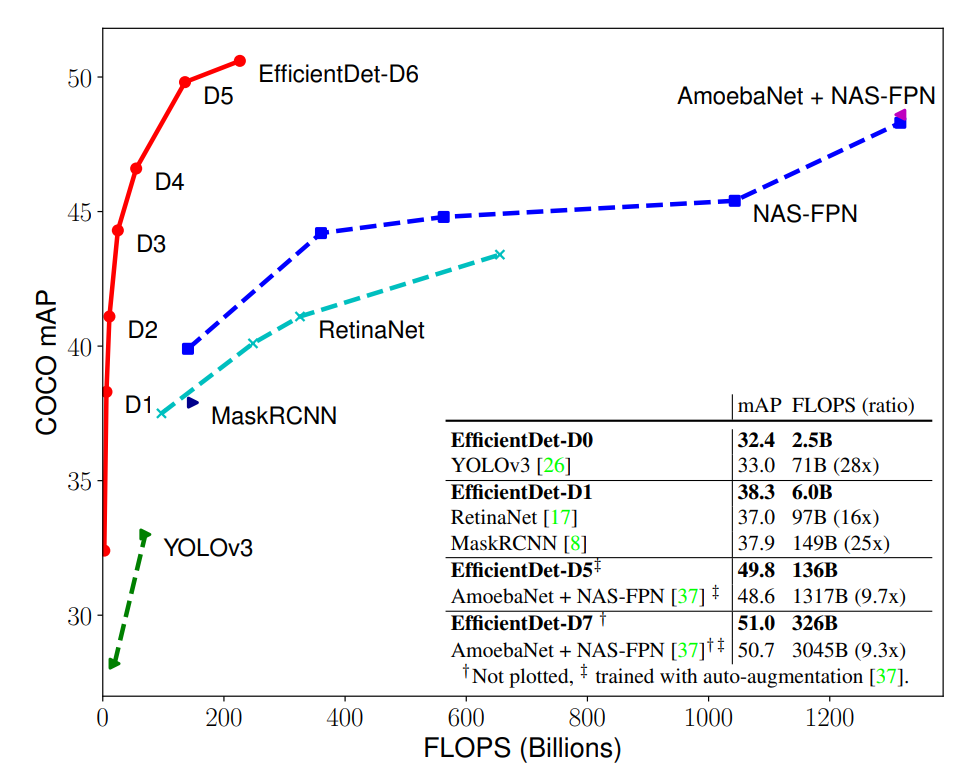
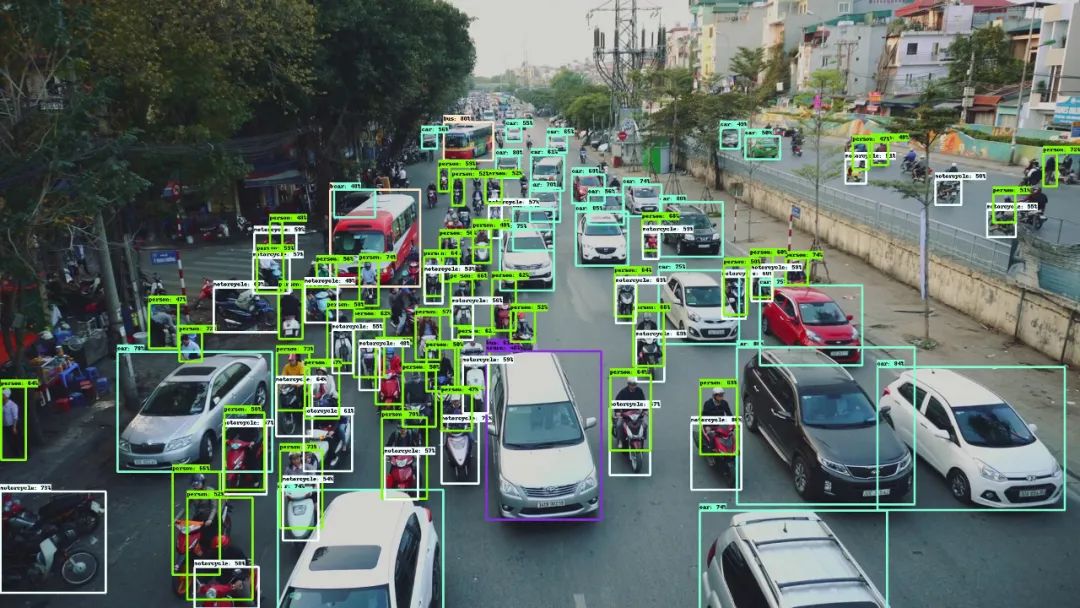
谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet。EfficientDet检测器是单次检测器,非常类似于SSD和RetinaNet。骨干网络是ImageNet预训练的EfficientNet。把BiFPN用作特征网络,该网络从骨干网络获取3-7级{P3,P4,P5,P6,P7}特征,并反复应用自上而下和自下而上的双向特征融合。在广泛的资源限制下,这类模型的效率仍比之前最优模型高出一个数量级。具体来看,结构简洁只使用了 52M 参数、326B FLOPS 的 EfficientDet-D7 在 COCO 数据集上实现了当前最优的 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,而后者的 FLOPS 更是 EfficientDet-D7 的 9.3 倍。
专知会员服务
27+阅读 · 2019年11月24日
Arxiv
6+阅读 · 2018年3月30日




相关VIP内容
专知会员服务
27+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月30日