学界 | Jeff Dean新提出机器学习索引替代B-Trees:可提速3倍
选自arXiv
机器之心编译
参与:黄小天、刘晓坤
Jeff Dean 的最新论文中把索引视为模型,探索了深度学习模型学习的索引优于传统索引结构的条件。初步结果表明,借助神经网络学习索引可以超过缓存优化的 B-Trees 高达 70%的速度,同时为若干个真实数据集节省一个数量级的内存。作者认为这个方法将彻底革新传统的数据库系统的开发方式。
无论什么时候,高效的数据访问方式都是必需的,所以索引的结构就成为了关键。此外,目前存在多种索引的选择来解决各种访问模式的需求。例如 B-Trees 是范围请求最好的选择(例如在特定时间线上索引所有的数据记录),哈希表(Hash-Maps)在性能上很难打败基于键值的搜索方法,而布隆过滤器 (Bloom Filter) 通常用于检测是否存在某条记录。由于索引对于数据库系统和其它一些应用的重要性,过去几十年来,它们已经广泛地发展为更高的内存、缓存和 CPU 效率 [28, 48, 22, 11] 的方法。
在这篇论文中,作者探索了包括神经网络的学习模型(learned model)在多大程度上可以取代传统的索引结构(包括从 B-Trees 到布隆过滤器)。这可能看起来有点反直觉,因为机器学习无法为作者提供传统意义上使用索引的语义保证(semantic guarantee),并且最强大的机器学习模型——神经网络通常被认为其评估过程非常耗能。然而,作者认为这些问题都不是问题。相反,作者认为使用学习模型的建议拥有很大的潜在价值,特别是对于下一代的硬件。
从语义保证方面来说,索引已经在很大程度上类似于学习模型,从而能很直接地被其它类型的模型所取代(例如神经网络)。例如,一个 B-Tree 可以被看成一个模型,把键作为输入,并预测数据记录的位置。一个布隆过滤器可以看成一个二值分类器,预测一个键是否存在于一个集合中。
从性能方面来说,作者观察到所有的 CPU 都已经拥有了强大的单指令多数据(SIMD)功能,并且可以推测很多移动设备都将很快拥有 GPU 或 TPU。同样,由于通过神经网络(而不是通用指令集)能很容易地扩展并行数学运算的受限集,推测 CPU-SIMD/GPU/TPU 将迅速变得很强大也是合理的。从而执行一个神经网络的高耗能在未来将是可忽略的。例如,英伟达和谷歌的 TPU 都已经可以在单次循环中运行成千上万次神经网络运算 [3]。此外,据说 GPU 到 2025 年时将达到 1000 倍的性能提升,尽管 CPU 的摩尔定律已经基本失效 [5]。通过使用神经网络取代分支复杂的索引架构,这些硬件进化趋势可以为数据库带来很高的效益。
需要注意的是,作者并没有说要用学习到的索引结构完全取代传统的索引结构。更准确地说,他们概述了一种建立索引的新方法,可以作为当前工作的补充,并将开辟一个新的研究方向。虽然只聚焦于只读分析型负载,但他们还概述了如何将这个想法扩展以加速写入繁重的负载的索引建立。此外还简要地概述了同样的理论如何用于取代数据库系统的其它组件和操作,包括分类和合并。如果成功了,将彻底革新传统的数据库系统的开发方式。
本论文的其余部分概述如下:下一节中作者使用 B-Trees 作为实例介绍了学习索引的整体想法。第 4 节中,作者将这一想法扩展到哈希索引,在第 5 节扩展到布隆过滤器。所有章节包含一个单独的评估,并列举开放的挑战。最后章节 6 中讨论了相关工作,章节 7 给出结论。
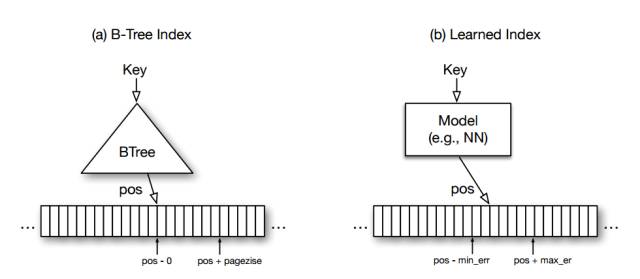
图 1:为什么 B-Trees 是模型
这篇论文只关注两种模型:简单的神经网络(带有 0 到 2 个全连接隐藏层、ReLU 激活函数以及最高 32 个神经元的层宽)和 B-Trees(也称为决策树)。在索引配置给定的情况下,即指定阶段的数量和每个阶段模型的数量作为一个大小(size)的数组,混合索引的端到端训练如算法 1 所示。

从整个数据集(第三行)开始,它首先训练顶部节点模型。基于这一顶部节点模型的预测,然后从下一个阶段(第 9 行和第 10 行)中选取模型,并添加所有属于该模型(第 10 行)的键。最后,在混合索引的情况中,如果绝对最小/最大误差高于预定义阈值(第 11-14 行),则用 B-Tree 替代 NN 模型来优化索引。
注意,作者为最后阶段的每个模型保存了标准误差和最小、最大误差。这样做的好处是可以根据每个键的使用模型单独地限制搜索空间。此外,人们可能想知道如何设置混合端到端训练的不同参数,包括阶段的数量和宽度、神经网络配置(即隐藏层的数量和宽度)和替代 B-Tree 节点的阈值。通常,这些参数可以使用简单的网格搜索进行优化。并且,可以根据最佳实践显著地限制搜索空间。例如,作者发现 128 或 256(B-Tree 的典型页面大小)的阈值运行良好。此外,对于 CPU 我们很少提供多出 1 或 2 个全连接隐藏层和每层 8 到 128 个神经元的神经网络。最终,在模型容量相当低的情况下,可以用较少的数据样本训练较高级别的模型阶段,这大大加快了训练进程。
注意,混合索引允许把学习索引的最差表现限定为 B-Trees 的表现。也就是说,在不可能学习数据分布的情况下,所有模型将自动被 B-Trees 替代,使它成为一个实际上完整的 B-Tree(不同阶段之间有一些额外的开销等等,但性能总体是相似的)。
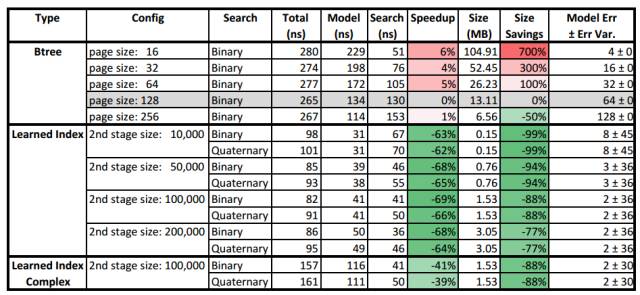
图 4:图数据:学习索引 vs B-Tree
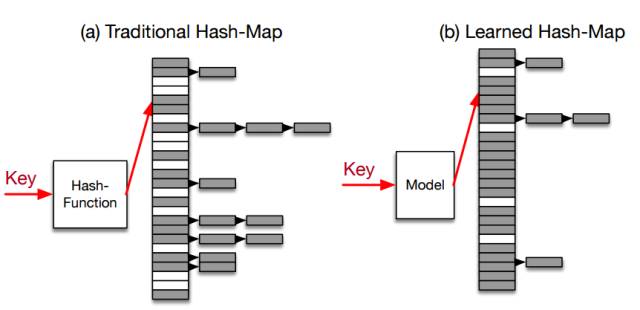
图 9:传统哈希表 vs 学习哈希表
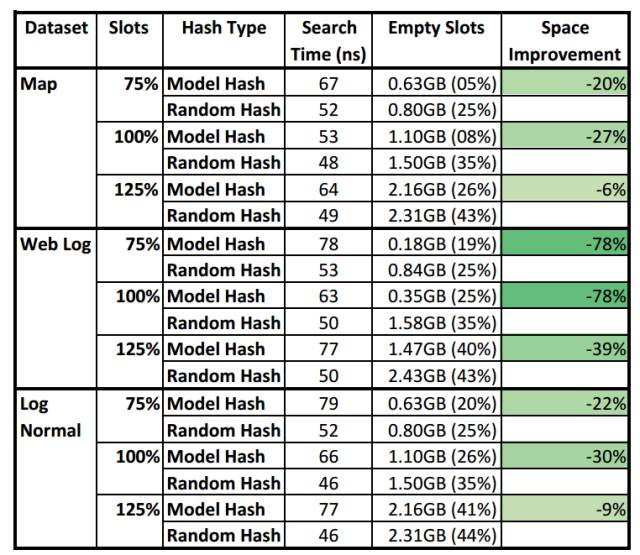
图 10:模型 vs 随机哈希表
论文:The Case for Learned Index Structures

论文链接:https://arxiv.org/abs/1712.01208
摘要:索引即是模型:B-Tree-Index 可被看作一个模型,把键(Key)映射到排序数组中的记录位置;Hash-Index 可被看作一个模型,把键映射到未排序数组中的记录位置;BitMap-Index 也可被看作一个模型,指明数据记录是否存在。在这篇探索性的论文中,我们从这一前提出发,假定所有现存的索引结构皆可由其他模型替代,包括我们称之为「学习索引」(learned indexes)的深度学习模型。本论文的核心思想是一个模型可以学习排序顺序或查找键的结构,并使用这一信号有效地预测记录的位置或存在。我们从理论上分析了学习索引在什么条件下表现优于传统索引结构,并描述了设计学习索引结构的主要挑战。我们的初步结果表明,借助神经网络,我们能够超过缓存优化的 B-Trees 高达 70%的速度,同时为若干个真实数据集节省一个数量级的内存。更重要的是,我们相信通过学习模型取代数据管理系统核心组件的想法对于未来的系统设计有着深远的影响,而且这项工作仅仅展示了所有可能性中的一部分。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


