谷歌称之为“下一代 AI 框架”, Pathways 真有那么强吗?

文 | Severus
大家好,我是 Severus,一个在某厂做语言理解的老程序员。
今年清明节,Google 搞了一点小动作,在 arxiv 上放出了自己的新工作,PaLM[1] (PaLM: Scaling Language Modeling with Pathways)。这是自去年,Jeff Dean 谈论下一代 AI,提出 Pathways[2] 架构之后,其第一次秀出了自己的成绩。既然秀肌肉的一件工作,我们不必怀疑,其在各大不同的基准任务上,能展现出什么样的非凡能力。论文发出之后,各家大V迅速跟进,各种解读铺天盖地,关于它是什么样子的,它的实现细节,它展现了什么样的效果,已不必赘述。今天,我想要谈一谈,Pathways 及其背后的思想,可能会开启什么新的纪元?为什么 Jeff Dean 认为它是下一代的 AI 架构?
缘起:Swtich Transformer
事情还是要回到去年1月份。彼时以 GPT-3 为首,预训练语言模型界刮起了大模型之风。当然,这股风浪到现在也没有过去,千亿级别的大模型,仍然是你方唱罢我登场。而在那个时候,Google 一篇 Switch Transformers[3] 引起了我的注意。说来惭愧,当时我注意到这篇工作,还是因为某公众号提出了“万亿”这一关键词。而彼时由于大模型的风刮了太久,对这种工作我充满了不屑,且 Google 是出了名的“大力出奇迹”,我也仅仅是将其当成了卷出新高度的工作,打开看了一眼。
我承认,我被打脸了,Switch Transformers 想要秀出来的,不只是 Google 的厨力有多强,更在于,他们翻出了一个古老而优美的架构——Geoffrey Hinton 于1991年提出的,混合专家模型[4](Mixture Of Experts,下称 MoE)。

MoE,与我们通常所理解的 DNN模型的很大区别是,其内部不是由一个统一的模型组成,而是由若干个小模型组成,一次计算会使用哪些小模型,由一个稀疏门控系统决定[5]。当时我注意到的是,把大模型变成若干个小模型,技术上的意义则是,计算量会降低,运算效率会变快,自然,模型的总参数量也就可以变得更大。
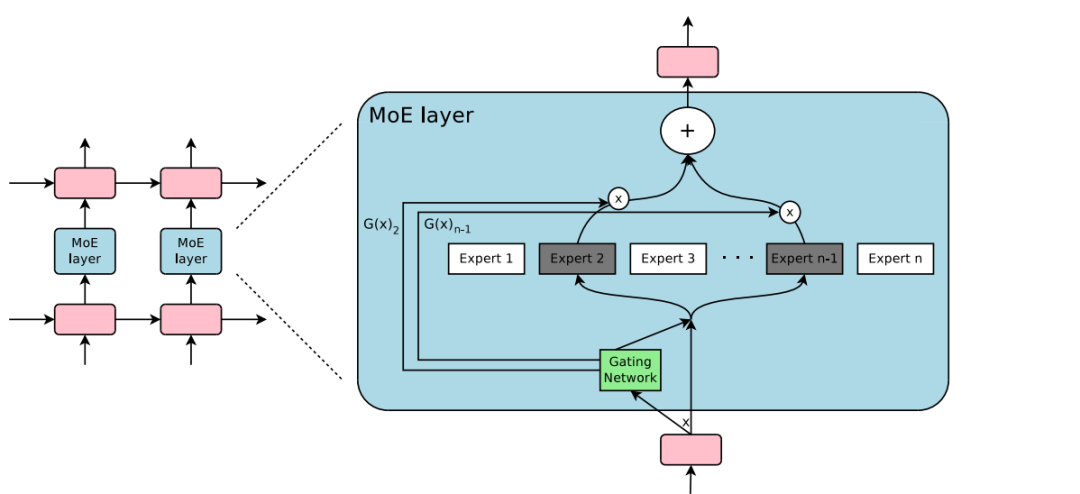
需要说明的是,在这个时候,我对 MoE 前景的理解是极其浅薄的,那个时候的我根本没有看到,其后面的巨大价值。
而到了去年10月底,也就是 Pathways 发布临近,马后炮地说,我在和同事畅想未来的时候,也提出了类似的设想,并将之放在了我11月的技术分享中,作为“未来篇”的结尾。现在想来,这是一个美好的巧合,从当前 AI 技术的发展步调来看,却也是一个历史的必然。
以我老 CS 人的嗅觉,我发现,MoE 的潜在价值在于其工程思想,这一架构,给多任务,乃至多模态提供了一个新的、且我认为更加靠谱的方向。
无限统合
首先,既然 MoE 的各个专家由稀疏门控制,则专家之间相互可看作是独立的。那么我们就可以做一个非常朴素的猜测,不同的任务,可以由门控系统分配给不同的专家来处理,这样任务之间就不会有太大的影响。这一点个人认为是比较重要的,因为不同的任务,大概率会有相互之间冲突的地方,虽然大模型可以依靠大规模参数所带来的记忆能力,缓解这一问题。
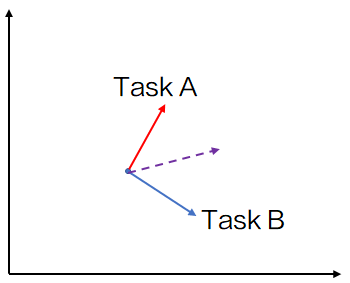
通常多任务学习的前提假设是,多个任务之间,是可以互相增益的,其潜在逻辑在于,多个任务所应用到的知识,存在共通的地方。实际上,预训练模型或预训练特征(word2vec等),就是找到一种看上去所有任务都会用到的自监督特征,使用大量的语料训练出来,保证覆盖,使之在迁移学习上成立。
而独立,则可以真正地让一个系统处理多个任务。
而如我上面所提,那不是就意味着,多个任务之间共通的那部分特征也就独立,造成不必要的冗余了呢?实际上,哪怕只有一个任务输入到 MoE 系统中,也不可能只激活一个专家,单个任务,也有可能同时激活多个专家, 那么,我们是否可以认为,激活的这多个专家,实际上已经把这个任务给拆解开了呢?理想状况下,被激活的各个专家各司其职,分别抽取一部分特征,再通过某种方式结合起来,决定了模型的输出。
那么,多任务场景之下,理想状况下,就可以认为,任务之间共通的知识,由相同的专家学到,而任务之间差异的知识,则由不同的专家捕捉,二者有机结合,形成了一个统合的多任务系统。
说到这,我们就可以把脑洞开的更大一些了,多任务可以解决,多模态能否解决呢?
我认为,Pathways 所代表的思想,是一种更加有力的多模态解决方案。
多模态与 Pathways
当前多模态最大的困境是什么呢?实际上是数据空间无法对齐。以文本与图片为例,请小伙伴们同我思考,当我说出“一匹马”的时候,你的脑海中会想象出多少张图片?
而当我让你描述这样一张图片的时候,你的脑海中又能蹦出多少种描述方式?

我想这两个问题的答案,都是无限,对吧?这也就意味着,通用意义上,或当任务空间足够大的时候,图片和文本数据,是不可能对齐的。数据无法对齐,训练过程中,多模的知识自然也会趋向过拟合式的绑定,这也就意味着,单个 dense 网络结构的多模态模型,仅仅可以处理足够窄场景的多模任务,如某音的短视频搜索。
而到了 MoE 中,如我前面所说,不需要做数据对齐,同时也没有直接去硬性组合最终的输出,而是在中间层的抽象特征上,做了映射和组合。这样一种结构,不敢说通用,至少处理更大场景、更多元的多模任务时,看上去更加合理一些。
那么我们可以大胆设想,预训练-微调可以是这个样子的:训练一个包罗万象的大模型,由这个大模型,则可以导出各种处理专用任务的小模型,这可能才是有钱有算力的机构的使命所在。由于大模型是保罗万象的,内部是由多个独立专家组成的,我们不必再担心 fine-tuning 会破坏模型原本学到的知识,预训练阶段学到的知识也能够得到更好的利用。
最后一部分,我想要从另一个角度,谈一下为什么我相信 Pathways。
从认知科学的角度
人工智能研究的目标之一,是真正做出一个强智能,而由于目前,我们能够参考的唯一一个真正的强智能,只有我们自己,所以接下来,我将以我对人脑粗浅的认识为类比,继续聊一聊 Pathways。
我们继续以多模态为例。首先,人处理信息的时候,一定是多模态的,这个已经是一个常识了。所以多模态也一定是 AI 的趋势。但是,单个 dense 模型的多模态研究,前文已提到,需要的是数据的对齐,而用认知的话来讲,则是用一个感知系统去处理多种感知信号(需要说明的是,这里所说的感知系统与器官不是等同概念)。
是的,人是多模的,但是,人不是这么处理感知信号的,对于不同形式的感知信号,人是有不同的感知系统对应处理的,而同时又有认知系统进一步处理感知信号,形成我们对世界的认知。
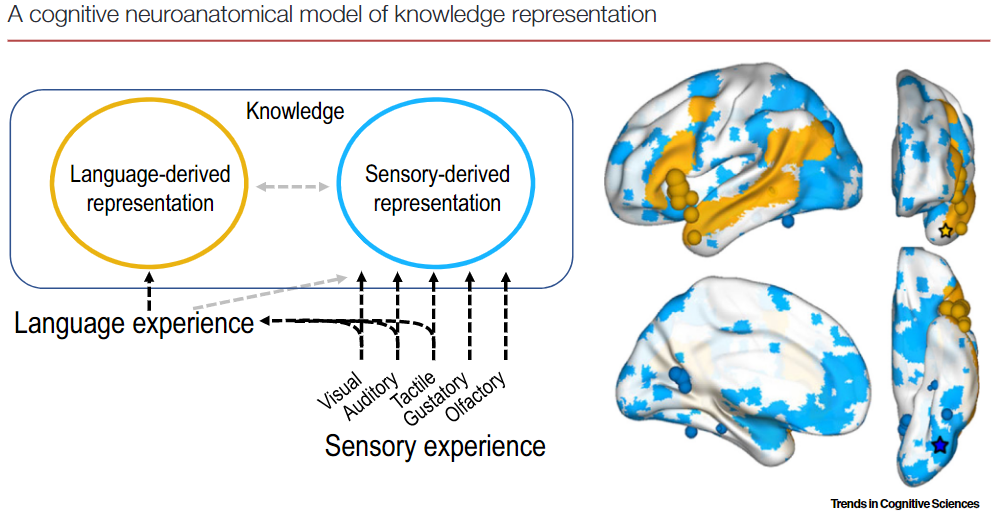
人脑是有多个感知系统的,而感知系统之间,又是相对独立的,不同的感知系统有可能分布在不同的脑区。同时,去年我关注到毕彦超老师关于知识的双重编码理论的工作[6],他们的实验结论表明,先天盲人也是能够通过认知系统,学习到“红色”这一概念的,也就说明了,即使对于颜色的感知系统缺失了,人依旧能够学会颜色概念。同时,通过核磁共振成像,也可以观察到,在提到颜色概念时,先天盲人被激活的脑区,和视觉正常的人被激活的脑区,是不一样的。也就说明,感知系统和认知系统也分布在不同的脑区,且相互独立。
这种结构,保证了很好的容错能力。即,人的某一个感知系统出现问题了,一般不会影响到其他的感知系统(双目失明的人同样可以听到声音,尝到味道);而某一感知系统缺失,也可以不影响人的认知。
那么,我们将这些对应到我上文所讲到,Pathways 的前景上,是不是可以说,相比于单纯的堆砌神经元数量,它和目前认知科学所理解到的,大脑的运行机制,非常像呢?不同的感知系统,对应不同的专家网络,而从感知到认知,则在系统中作为抽象特征组合,也由更高层次的专家网络处理,部分通用的知识,也由认知系统存储了下来;且不同的模态,或不同的特征可以缺省,增强了整体的容错能力。从这个角度来看,的确,下一代的智能可能就应该是这个样子的。
我不敢妄言具象的 Pathways 一定就是未来,从最抽象的意义上讲,它提出了一条可行的路径,或许可以通往智能。
当然,做这个东西的大前提是,有钱……


萌屋作者:Severus
Severus,在某厂工作的老程序员,主要从事自然语言理解方向,资深死宅,日常愤青,对个人觉得难以理解的同行工作都采取直接吐槽的态度。笔名取自哈利波特系列的斯内普教授,觉得自己也像他那么自闭、刻薄、阴阳怪气,也向往他为爱而伟大。
作品推荐
 萌屋作者:Severus
萌屋作者:Severus
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Chowdhery A, Narang S, Devlin J, et al. PaLM: Scaling Language Modeling with Pathways[J]. arXiv preprint arXiv:2204.02311, 2022.
[2] https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/
[3] Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. arXiv preprint arXiv:2101.03961, 2021.
[4] Jacobs R A, Jordan M I, Nowlan S J, et al. Adaptive mixtures of local experts[J]. Neural computation, 1991, 3(1): 79-87.
[5] Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[J]. arXiv preprint arXiv:1701.06538, 2017.
[6] Bi Y. Dual coding of knowledge in the human brain[J]. Trends in Cognitive Sciences, 2021, 25(10): 883-895.
 后台回复关键词【
后台回复关键词【