【军用区块链+复杂系统】《数据信任方法学:基于区块链的复杂系统检测》麻省理工林肯实验室

1. 问题陈述
-
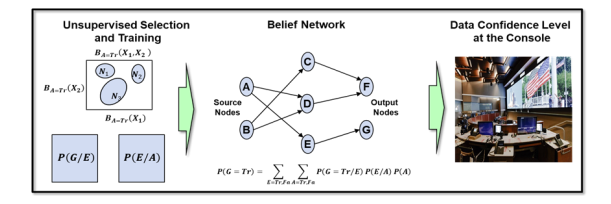
1.决策者和作战背景数据过程提供和利用的信息(即知识)类型(图1)。
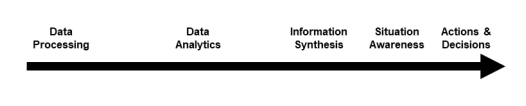
-
2.在业务处理链中验证数据出处、完整性和有效性的好处 -
3.我们的区块链技术框架与分析技术相结合,利用核查和验证能力,可以部署到现有的国防部(DoD)数据处理系统中,而且性能和业务干扰不大。
2. 框架概述
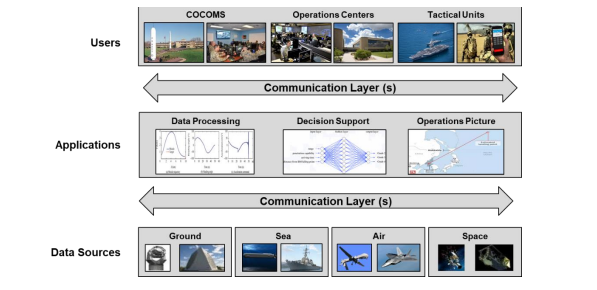
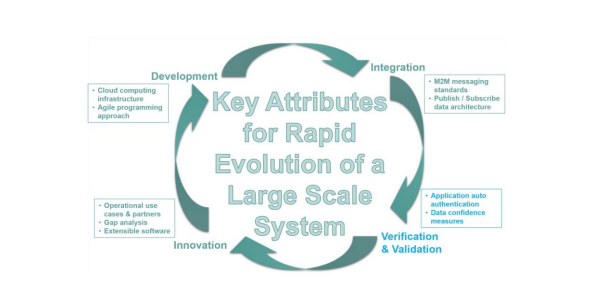

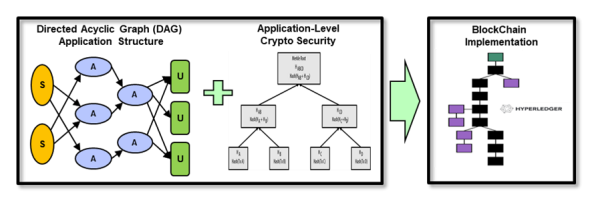
专知便捷查看
便捷下载,请关注专知人工智能公众号
后台回复 “dtm” 就可以获取 【军用区块链+复杂系统】《数据信任方法学:基于区块链的军事复杂系统检测》麻省理工林肯实验室 专知下载链接
欢迎微信扫一扫加专知助手,获取最新AI专业干货知识教程资料和与专家交流咨询!




登录查看更多
相关内容
专知会员服务
71+阅读 · 2022年4月25日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月26日
Arxiv
0+阅读 · 2022年7月26日
相关VIP内容
专知会员服务
71+阅读 · 2022年4月25日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
0+阅读 · 2022年7月26日
Arxiv
0+阅读 · 2022年7月26日