基于机器学习系统的决策,特别是当这种决策可能影响到人类的生命时,是机器学习界最感兴趣的一个话题。因此,有必要为这些系统配备一种估计其发出的预测的不确定性的方法,以帮助从业者做出更明智的决策。在本工作中,我们介绍了不确定性估计的主题,并分析了这种估计在应用于分类系统时的特殊性。我们分析了不同的方法,这些方法被设计用来为基于深度学习的分类系统提供测量其预测的不确定性的机制。我们将审视如何使用不同的方法对这种不确定性进行建模和测量,以及对不确定性的不同应用的实际考虑。此外,我们还回顾了一些在开发此类度量标准时应注意的属性。总而言之,本调查旨在为分类系统中不确定性的估计提供一个务实的概述,这对学术研究和深度学习从业者都非常有用。
1 引言
机器学习(ML)目前存在于各种应用和领域。目标识别、自动字幕和机器翻译只是机器学习,特别是深度学习(DL)为竞争性业务服务的多个领域中的一部分。在某些应用领域,如自动驾驶或自动病人诊断支持系统,所需的性能水平非常高。预测的失败会导致严重的经济损失,甚至是人命的损失。因此,需要有管理自动决策所带来的风险的方法,特别是对这些类型的应用。
在应用深度学习系统(机器学习的一个子领域)时,管理这种风险尤其重要。深度学习是基于使用丰富的人工神经网络(ANN)的架构。它与传统机器学习系统的主要区别之一是假设这些ANN可以捕捉到输入数据的有意义的特征,并使其适应学习任务。通过委托这些模型中的特征工程,DL使得分类系统的设计更加简单。
然而,这种将特征工程委托给模型的做法,以及许多现代DL架构中存在的大量模型参数,使得这些系统难以解释。如果我们在获得的预测中加入一个不确定性的度量,使我们能够管理决策中使用的风险,那么这种缺乏可解释性的问题就可以得到解决。然而,不确定性的概念不是单一的,甚至没有一个公认的定义,因为它存在于机器学习过程的每个阶段。不确定性的来源可以在数据采集和预处理、模型设计、选择阶段、甚至是训练过程中找到。这就产生了许多不同的不确定性定义,取决于研究人员和从业者关注的具体方面。
根据机器学习文献,Gal[28],理解不确定性的一种常见方式是依靠其来源。在这种情况下,我们可以考虑alleatoric不确定性--它与数据中固有的不确定性有关--和epistemic不确定性--它与模型的信心有关。[88]中提出的另一种方法是将其分为四种类型:随机性--与随机变量有关的一种客观不确定性;模糊性--由于没有严格或精确的概念界限而产生的一种认知不确定性;粗糙性--代表知识的准确程度;以及非特定性或模糊性--从两个或多个不明确的对象中选择一个而产生。此外,我们还可以考虑其他不同的类型,取决于不确定性是否可以减少。正如我们将看到的,并不总是能够保持这些鲜明的划分,因为同一个模型在其生命周期内可能遭受不同类型的不确定性。
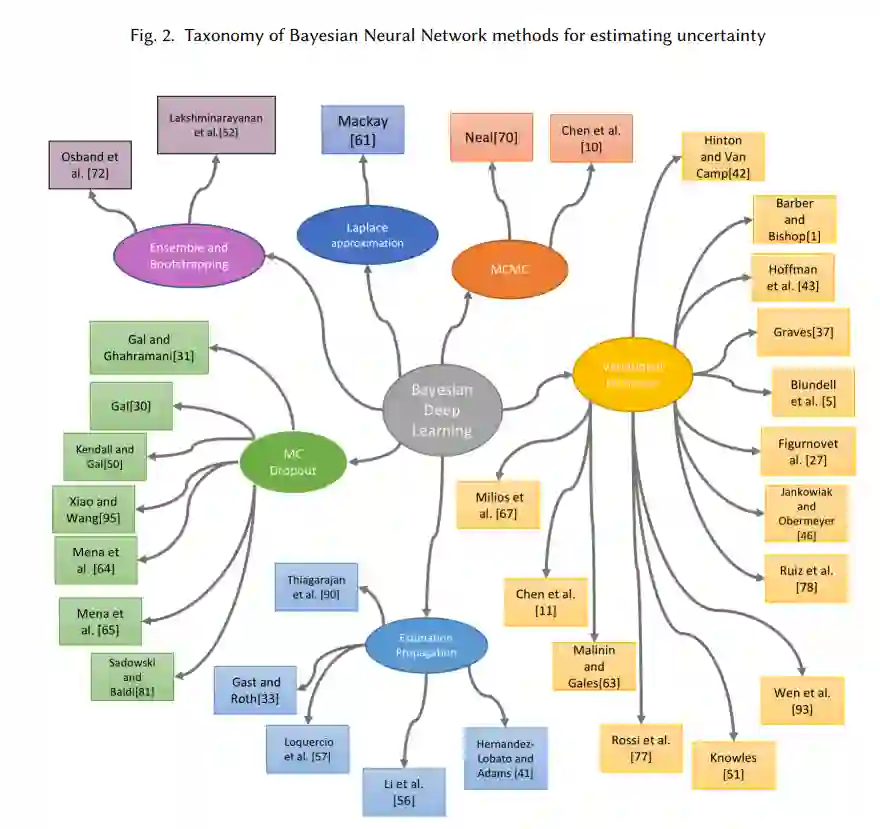
鉴于上述情况,我们可以说,不确定性是一个复杂的概念,需要被表示、测量和应用。本工作的目标是调查文献中存在的针对分类系统中采用的这三个阶段的不同方法。尽管在深度学习分类模型中估计不确定性所遵循的程序与用于传统分类模型的程序没有根本的不同,但它确实有一些具体的特点。在深度学习中,最广泛使用的损失函数是softmax交叉熵,这在传统模型中从来没有很受欢迎。这个函数在早期层的未标度输出(logits)上运行,意味着理解单元的相对标度是线性的。这样的方法提供了一个直接的概率解释,即以类的分数作为定义不确定度的基础。此外,神经网络固有的灵活性可以用来丰富分类模型,增加一些组件来计算这些不确定性措施。例如,额外的层可以用来应用分层贝叶斯模型进行不确定性估计。关于认识上的不确定性度量,经典的方法是将每个模型参数视为一组定义随机变量的参数估计,而不是一个点估计。在这种情况下,挑战依赖于要估计的参数数量,可能是数以百万计的。
本文的附加价值有三个方面。首先,与Gal[28]不同的是,他专注于回归问题中的不确定性估计,我们处理分类问题,调查了一系列方法,从最早的基于Dropout的方法到更新颖的技术,如在单纯线上建立连续分布模型。其次,我们通过统一的贝叶斯视角来介绍各种方法,以利于理解。最后,我们不仅介绍了估计技术的最新进展,而且还介绍了关于其特性和在实际场景中使用的一些考虑。
文章的以下两节正式介绍了深度学习分类场景,这也是本次调查的重点,同时也回顾了不确定性的定义。
第4节调查了深度学习分类系统中的不确定性是如何表示的。在大多数情况下,这些系统产生的结果是以一组类的概率分布的形式出现的。表示系统预测中的不确定性的最基本方法之一是依靠这些概率来决定是否相信系统的结果。然而,正如文章所示,这些概率可能会导致错误,因为它们可能没有被很好地校准,它们的解释可能不直观,或者更糟糕的是,它们可能被错误地认为是安全的预测。
与其依赖这些点估计,不确定性估计方法可以从分类器输出的后验分布的近似值产生不确定性度量。我们将看到各种工作如何通过使用不同的概率分布和关注其定义的不同术语来提出不同的方法来模拟这种后验分布。
在回顾了估计分类器后验分布的不同方法后,我们在第5节中介绍了测量不确定性的不同方法。如果我们要把不确定性的概念变成一个可操作的值,使风险在分类系统中得到管理,这是一个必要的步骤。在这一节中,我们将看到这些系统在试图提取不确定性的单一度量时是如何带来额外困难的。这是由于分类系统通常会返回多个值,以及每个类别的相应不确定性。因此,有必要建立一种机制,将这些多个输出合并为一个单一的值。正如我们的回顾所显示的,这种额外的复杂性导致了多种总结不确定性的方式,与回归系统的不确定性度量形成对比,后者通常输出一个单一的值。
第6节介绍了一些应用,说明了不确定性在与分类系统相关的不同方面的使用。
最后,第7节对本文进行了总结,并描述了不确定性估计方法面临的一系列挑战。这样做的目的是为读者提供一些标准和良好的实践,帮助从业者在将不确定性纳入分类系统的设计时选择最适合他们问题的方法。