这次咱们从根源聊:16招搞定高并发架构设计

本文所说的高并发架构设计是指设计一套比较合适的架构来应对请求、并发量很大的系统,使系统的稳定性、响应时间符合预期并且能在极端的情况下自动调整为相对合理的服务水平。
一般而言我们很难用通用的架构设计的手段来解决所有问题,在处理高并发架构的时候也需要根据系统的业务形态有针对性设计架构方案。
本文只是列出了大概可以想到的一些点,在设计各种方案的时候无非是拿着这些点组合考虑和应用。
有很多高并发架构相关的文章都是在介绍具体的技术点,本文尝试从根源来总结一些基本的方法,然后再引申出具体的实现方式或例子。
下面是本文会介绍的16个方面的大纲:
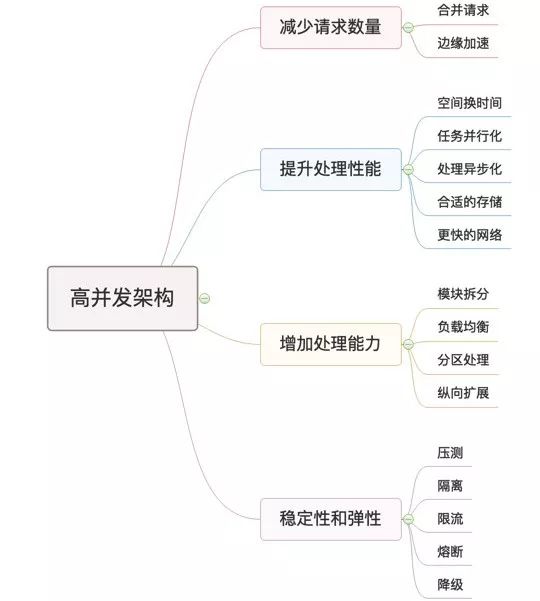
一、减少请求数量
既然请求量大,那么第一个方面可以考虑是否可以让请求量不那么大,或者说至少进入我们业务系统的量不这么大。
除了下面提到的两点,我们还可以从业务的角度考虑一下:
如果这是一个限时活动,那么我们的活动受众群体是否需要是所有用户,如果不是的话是否就可以通过减少受众减少并发;
如果需要群发推送让用户来参与非秒杀类活动是否要考虑错时安批推送,避免因为推送引起的人为大并发等等,在技术手段接入之前先看看运营和产品手段能否减少不必要的大流量。
每一个独立的网络请求都是开销,我们可以通过合并动态静态的请求来减少请求数量。现在的Web前端应用基本都会在构件打包阶段对脚本、CSS进行压缩合并等预处理。
对于后端动态请求而言,我们更需要在设计阶段考虑接口的粒度,并且区分对待实时处理和批处理的架构,数据批处理的工作不太适合通过循环调用远程接口的方式实现。
CDN就是边缘加速的一个例子,一般而言我们使用CDN不仅仅为了让用户访问数据更快,而且通过在边缘节点做一定的缓存策略可以让节点帮我们挡住很大部分的流量(特别是静态资源,除了回源的请求都可以由CDN挡掉)。
更进一步说,一些CDN可以做一些定制化的处理,允许业务方提供一些简单的脚本在节点做边缘计算,比如在秒杀场景下根据一定的策略直接在CDN节点进行计算,放行0.1%的用户流量进入我们的后端系统。
二、提升处理性能
第二个方面优化的方向是提高单个请求的处理性能,也就是减少请求的处理时间,优化请求处理调度和占用的资源。
这里列出的几个点都是我觉得应该去重点看重点突破的点,你可能会说我们不是应该去优化下程序内部的算法和数据结构吗?
的确应该是,但是对于大部分业务程序来说,性能问题往往不是优化那些细枝末节的东西可以解决的(比如对于Java来说,在编译时编译器,在生成机器码时JVM都会去做一些优化,代码层面的一些优化往往没那么重要,代码层面我们只需要关注可读性),而是需要重点关注下面提到的几个方面。
这里可以举一些空间换时间的策略:
缓存
一般有两种做法:
一种是在程序启动的时候从外部数据源初始化大量的不怎么变的数据到内存中,在内存中形成面向搜索友好的数据结构(比如哈希表),提供快速的数据访问,之后所有的请求都无需请求数据源,采用定时拉取或监听变动消息的方式同步变动。
一种是利用分布式缓存做计算结果的缓存,具有比较短的过期时间,可以挡掉大量重复请求,对于搜索条件组合较多的请求命中率差。当然,缓存除了使用空间换时间之外,一般还会利用存储介质的性能差异来提升性能,所以我们看到通过内存缓存数据比较常见。
缓冲
和缓存相近但又截然不同的概念是缓冲。IO操作一般都会使用缓冲区,在我们实现业务的时候也可以利用这种思想。
对非时间敏感的调用进行适当蓄水,甚至合并,一次性提交到后端服务,比如玩一个抓红包的游戏,用户在屏幕上点点点来抓红包,是否真的有必要每次都向数据库更新红包余额呢?
还是可以在服务端缓冲一下,10次更新一次余额甚至整个游戏只提交一次?
还比如,我们需要对内存中的一些数据做处理,处理的时间会比较久,在处理的时候显然不能持续服务业务了。
为了一致性考虑需要做悲观锁处理,这个时候我们就可以考虑开辟一块所谓的缓冲区,专门用于数据处理,处理好之后把指针指向新的缓冲区,再回收使用老的区域做持续处理,就像JVM中的From和To区域来回倒腾,这也算一种缓冲使用。
面向数据读取优化
比如微博的实现在发微博的时候找出大V下一定数量的活跃的在线粉丝,比如5000个,直接把微博写入他们的关注微博列表中去(推数据过去),这样在那些粉丝刷新自己微博首页的时候就能更快(不用去关联拉数据了)。
又比如许多时候我们会做所谓的固化视图的工作,在写入数据的时候就直接写为我们之后要读取的复杂数据结构(比如数据需要Join N个表才能获得的,在写入的时候就直接组成这样的数据写到数据表)。
或者可以说我们做哈希结构,做B树索引,做倒排索引都是这样的思路,使用一些有利于我们之后读取、查询和搜索的数据结构来加速数据的读取(虽然写入的时候耗时多一点,并且需要占用额外的空间)。
数据预读取
说白了就是预测到将来用户可能会访问的请求,进行预加载或是预处理,然后之后真正请求到来的时候这个访问就会特别快。
我们知道高并发的请求如果来源是用户的点击,那么这个量不太可控,而且不均衡。
对于来自用户的请求,如果是读取请求往往没太多好办法去异步处理,毕竟你需要同步返回用户信息,对于操作类的写入请求可以尽量异步化处理,仅仅把最关键的环节作为同步处理,那么直面用户的同步请求的执行时间就会大大减少。
这里可以举一些异步处理的例子:
使用线程池来进行异步处理一些非关键的任务
这个和之前说的任务并行化有点区别,这里说的使用线程池进行异步处理是指Fire-and-forget类型的处理,不需要等待处理完成的结果并且返回给前端。
使用MQ进行异步处理
比如下单的主流程就是落地和发MQ通知其它模块,落地后后续出库、物流的流转全部是其它模块在收到MQ消息后异步处理的。
极端一点的例子
对于很多广告系统需要进行计费处理,对于一些增长用户行为数据分析平台需要接收客户端上传的各种事件进行分析,如何可以抗住100万TPS的并发进行处理?最简单的方式就是直接搞10台Nginx负载均衡,Nginx只是记录AccessLog返回200(单机抗住10万TPS一点不是问题),后续由定时任务拉取AccessLog进行数据分析。
指的是让任务中的子任务并行执行,这样会比一个一个串行执行子任务来的快。
比如可以把多个子任务提交到线程池执行,然后等待所有任务都完成后进行结果汇总,这样总的耗费时间就是最慢的那个子任务的执行时间。
可以使用Java8的CompletableFuture进行任务编排处理。
这种使用任务并行化来提升处理性能的方式我个人不太常用,如果任务执行时间不是那么长的话,我还是宁愿串性执行,比较容易少出错,毕竟这些任务都是有状态的需要等待结果的,这和之前说的异步不是一回事。
这里是指选用合适的存储系统,在以前的文章中我详细介绍过发挥多种存储系统优势,采用同步落地Sharding的关系型数据库,异步落地其它NoSQL的架构。
这种架构的存储方式能够很好应对非常巨大的并发量,原因在于:
每一种数据库系统,特别是NOSQL都有自己的特性,我们可以充分利用这些特性来打造适合业务,适合高并发读写比的服务。
我们可以结合之前异步化的思想把最重要的关系型数据库的落库走同步处理,其它走异步处理,这样既可以利用多种数据库的特性又可以让数据写入不影响主流程。
当然,选用了合适的存储还不够,每一种存储系统也都需要精心去调优参数以及使用最佳实践去访问和使用存储(比如关系型数据库索引如何建立,如何优化查询)。
对于大部分业务服务来说无非是IO操作慢,大部分是网络IO慢,网络IO无非是外部存储服务或外部服务,所以这里提到的存储的优化是非常重要的一环。
还有一半就是外部服务的优化,但是外部服务的优化往往需要靠其它团队,不完全是自己能掌控的。
这里提到更快的网络意思是纯网络层面的链路,我们是否理清楚了到底是怎么走的,比如:
调用其它团队内部服务域名公网解析还是内网解析?访问链路走的是公网还是内网?
我们是如何调用其它服务的?详见《朱晔的互联网架构实践心得S2E4:小议微服务的各种玩法》
经过多少防火墙、反向代理?
走HTTPS还是HTTP?
如果是走公网走的是机房什么出口?
是长连接还是短链接(特别是HTTP请求)?
归根到底就是我们最好能了解这些外部服务在网络层面花费的情况是否达到预期,比如一个外部服务调用我们看到耗时1秒的时间,拼命追着下游去优化服务,但是下游说为服务端执行时间只有30ms呀?
结果一查发现整个调用跨了4个机房走了2次公网2次专线,然后还经过了4个网关转发,这些东西耗时970ms,这就很尴尬了。
我觉得一个能接受的情况是内网调用网络损耗在5ms以内,公网调用在50ms以内(跨国除外)。
对于大并发的系统来说任何一个环节增加很少的延时可能都会导致最前端超时或队列溢出。
之前也遇到过两个服务之间的调用因为专线维护从专线切到走公网+VPN的形式代码层面毫无变动,只是网络链路的改动因为大家都没有重视,链路切换后的白天在并发上去之后全线崩溃的问题。
当然,对于现在的微服务架构来说需要有很好的分布式追踪基础服务我们才好理清服务调用和调用的损耗。
三、增加处理能力
优化处理性能往往没有这么快,即使能优化往往也无法实现几十倍几百倍的性能提高,对于高并发程序来说我们肯定需要有一定的处理资源来应对,最悲惨的事情莫过于有一堆服务器但是用不起来,最理想的架构是每一个组件都可以横向扩展,并且随着服务器资源的增多能相应提升总体处理能力,下面我们来看看增加处理能力的一些方法。
拆分是最好的手段,对于业务应用可以这么来拆:
直接拆成子站,除了一些公共服务(比如用户、商户),其它全部独立
横向,按模块拆分成微服务独立部署
纵向(或者说分层,更多是物理分层),按功能拆分成专门处理数据的服务、专门落地的服务、专门汇总数据的服务等等
对于数据库来说也是一样:
拆分数据库,拆分数据库到不同的实例(服务器)
纵向,拆分成几个1:1的小表
横向,把同一个表的数据拆分到不同的数据库
当业务可以拆分的时候其实应对大并发没这么难,最困难的是拆无可拆,就是大并发针对的是同一个表同一行的数据的情况,而且读写的量都很大,而且要求强一致性的情况。
对于这种情况底层数据源很可能只能用关系型数据库甚至自己特殊实现的数据结构实现,无法进行拆分,请参阅下面的纵向扩展,哈哈。
对于无状态的服务来说,我们可以通过负载均衡来实现服务的负载分发,需要关注的是几个点:
负载均衡的策略
Backend健康检测
服务失效后从负载均衡摘除,恢复后的上线
发布系统和负载均衡的联动
负载均衡特别是7层覆盖,对于请求头做的改动会是怎样的
对于超大规模的集群,比如有上万台服务需要负载,那么可能需要10组Nginx来做负载均衡。
这10组Nginx本身也需要进行负载均衡,那么可以在最上层使用硬件F5或Haproxy在4层再做一层负载,也就是类似主备Haproxy->Nginx集群->tomcat集群类似的架构。
有一点不能不提,有的时候整个系统虽然已经是一个大集群但是由于不合理的全局分布式锁还是串行在处理任务,这个时候横向扩展不能解决问题。
又叫做Sharding、Partition,指的是把数据、任务进行分区,分发到不同的节点同时处理,提高并行度。
这点和拆分有一些相近,但是更多指的是想同的数据和任务需要批量循环处理的时候去做下分区,然后并行执行,应用这个思想的几个例子:
数据表的分表分库,然后由类似Proxy的中间件进行数据路由和汇总处理
比如Java 8 parallelStream的思想把数据分成多份在不同的线程同时处理
比如ConcurrentHashMap锁分段的思想,把全局的锁改为分段锁减少冲突
分区不但能提高并行度使用更多的资源来处理数据而且还可以减少冲突,但是分区处理后最终还是需要Reduce的,这个过程的处理方式以及处理的损耗需要进行考虑。
而且每一个分区的处理速度不一定均衡,所以不能完全假设分成N份系统的执行速度就提高了N倍。
纵向扩展说白了就是升级单台服务器的配置或使用更强力的小型机来替换普通服务器。
有的时候纵向扩展也是无奈之举,就像之前所说的对于一个很小的单表,虽然只有寥寥几个字段已无法再瘦身,但是读写量超大,强一致,或许也只能使用更强大硬件通过强大的IIOPS撑起这样的数据库。
我们之前提到的增加处理能力往往是指使用更多的服务器来支撑,更多的服务器意味着通讯需要跨网络,网络有损耗也有不稳定因素存在,分布式服务的状态需要同步,而且服务器越多就越可能出现失效的服务(假设1万台服务器,每天出问题的服务器在千分之一那就是10台了)。
分布式,横向扩展说白了是有很大代价的,在当今硬件没有这么昂贵的情况下往往也不失为一种方案:
为缓存服务器提供更大的内存
为随机IO要求高的Mysql、ES等服务器提供SSD磁盘
为不易做拆分的核心负载均衡处理器提供高配服务器
为极端高并发的数据库使用小型机
四、稳定性和弹性
对于高并发程序来说就像是一个紧绷的橡皮筋,或者一个充满气的气球,任何系统内部外部风吹草动造成的小性能问题都可能造成整个系统崩溃。
在稳定性和弹性方面同样需要做很多工作,否则依赖系统的抖动可能一下子把自己搞死。
个人认为关键链路上做的任何变更,包括代码修改,网络变更,按道理都需要在准生产或灰度进行压测后才能正式上线。之前也遇到过几次这样的案例:
因为系统多执行了一条SQL导致方法执行时间多了10ms,导致MQ消费速度变慢形成队列堆积,队列越积越多,最后MQ扛不住崩溃了
因为内部网关开启了验签增加了几毫秒的处理时间,所有服务的调用都经过网关,累计的调用时间累计增加了几百毫秒导致业务系统的处理线程一下子多起来然后OOM了
在非生产压测往往结果和生产差异很大,在生产压测需要考虑对业务的影响以及测试数据的清理。
而且压测需要考虑依赖服务是否可以参与一起压测,要真正在生产实现全链路压测的落地需要整个公司技术资源的协同,还是非常考验管理执行力,这往往不是技术问题。
隔离说的是在设计的时候需要考虑不同业务、不同SLA的服务在共享同一套资源的时候是不是会因为产生性能问题导致相互影响,如果会影响,并且我们不能接受这样的影响的话就需要考虑各种层次的隔离,比如:
直接在服务器级别隔离,比如我们需要考虑为VIP建设单独的服务器集群,甚至是IDC网络接入
在服务级别隔离,为重要的业务线单独分配并且路由到单独的虚拟机或POD,为大文件上传的服务进行服务拆分部署到具有更高IO和网络带宽的服务器上
在进程内部进行资源隔离,比如在使用Java 8 ParallelStream的时候考虑采用单独的线程池来处理任务,比如在使用Netty处理较慢的业务操作的时候配置单独的业务线程池进行处理,和IO处理的线程池进行隔离
在做压力测试的时候我们会发现,随着压力的上升系统的吞吐慢慢变大而且这个时候响应时间可以基本保持可控(1秒内),当压力突破一个边界后,响应时间一下子会不可控,随之系统的吞吐就会下降,最后会彻底崩溃。
任何系统对于压力的负荷是有边界的,超过这个边界之后系统的SLA肯定无法满足标准,导致大家都无法好好用这个服务。
因为系统的扩展往往不是秒级可以做到的,所以这个时候最快的手段就是限流,只有限流了才能保护现在的系统不至于突破这个边界彻底崩溃。
对于业务量超大的系统搞活动,对关键服务甚至入口层面做限流是必然的,别无它法,淘宝双11凌晨0点那一刻也能看到一定比例的下单被限流了。
常见的限流算法有这么几种:
计数器算法。最简单的算法,资源使用加一,释放减一,达到一定的计数拒绝服务。
令牌桶算法。按照固定速率往桶里加令牌,桶里最多存放n个令牌,填满丢弃。处理的时候需要获取令牌,获取不到则拒绝请求。
漏桶算法。一个固定容量的漏洞,按照一定的速度流出水滴(任务)。可以以任意速度流入水滴(任务),满了则溢出丢弃。
令牌桶算法限制的是平均流入速度,允许一定程度的突发请求,漏桶算法限制的是常量的流出速率用于平滑流入的速度。
实现上,常用的一些开源类库都会有相关的实现,比如google的Guava提供的RateLimiter就是令牌桶算法。之后我们会介绍熔断,熔断针对的是客户端保护,限流针对的是服务端保护。
降级往往不是一个纯技术手段,需要结合业务一起来考虑,比如:
对于送外卖,计算商家和送餐地点距离的时候,最好的方式是使用骑行距离,骑行距离需要调用外部地图API来得到,在外部地图API访问超时的时候需要考虑降级方案,把骑行距离改为根据经纬度算出来的直线距离,虽然不精确,导致配送时间的估算不精确,但是也至少让服务基本可用
对于电商需要做的超大访问量的促销活动页面在动态请求因为过载无法响应的时候,是否可以考虑降级为客户端这边之前写死的一些静态的活动商品列表,虽然这个列表无法反映当前活动实际的(商品售卖)情况,但是至少这个活动页是可看的
之前我们遇到过携程在出现服务宕机的时候直接降级为让用户去访问艺龙,这种属于整站降级,某些业务场景下甚至我们可以尝试在线上业务整站宕机的时候可以降级为人工客服处理部分业务
说白了降级往往是一个兜底方案,需要在做设计的时候结合业务场景考虑哪些环节可能会出问题,出了问题如何降级,是自动降级还是手动降级,降级后需要启用怎么样的应急处理流程等等。
熔断可以说是也是自动降级的一种,是对客户端的保护。
现在微服务的架构,一个客户端可能会依赖几十个其它的服务,有任何一个位于同步调用的外部服务出现超时,即使客户端的ReadTimeOut设置的时间不长也对客户端是很大的压力和负担。
(这么多线程干等着,当然了全异步的服务不需要考虑这个问题,互联网来大部分请求最终还是同步的HTTP,Web层总是需要等待的,很难像游戏服务器做到长连接的全异步处理。)
所以在外部服务遇到问题的时候要自动进行熔断,在外部服务恢复后尝试半恢复,最后完全恢复访问,一般来说有几种熔断策略:
根据请求失败率熔断,比如在一定时间内有一定百分比的请求是失败的,那么就开启熔断
根据响应时间熔断,比如一定时间内的请求平均响应时间超过N秒则开启熔断
一般而言需要在代码里去写熔断后的Callback,由回调函数提供熔断后返回的临时数据或者直接出异常不允许请求继续进行下去。至于选择临时数据还是出异常还是取决于实际的业务,对于某些情况熔断后返回一个不合理的临时数据往往是不可以接受的。
五、 总结
总结一下,对于高并发应用如何去考虑性能优化,说白了就这么几个思路:
要么是尽可能通过让并发别这么大,有的时候真没必要一拥而上造成人为的大并发
要么是尽可能优化代码、存储、网络,越简单,操作需要的CPU、IO、内存、网络资源越少在一定的服务器资源下就越可能应对更多的并发
要么就是通过扩展资源,扩展服务器来提高处理能力
最后一招就是在因为并发过大不稳定的时候系统需要启用一定的应急手段开启自保,别人工系统被流量压垮彻底挂了
作者:朱晔
来源:https://www.cnblogs.com/lovecindywang/p/10846471.html
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn

对架构设计思考不够深入?
想玩转热点技术,同时把握先机?
不妨来DAMS学点独家技能,
找到最适用的进阶法宝~
↓↓扫码可了解更多详情及报名↓↓
2019 DAMS中国数据智能管理峰会-上海站