ACL2019新论文,痛批“不计算力追逐丁点提升”的研究方法

“这绝对不是好的趋势,我们应该用更有创意,而不是纯粹‘加算力’的方式去做研究。”

“有些人做神经网络训练,完全不计代价,太不负责任了!”
小张是一名硅谷大公司的深度学习研究员,安坐在开着冷气的房间里写代码、调参、训练再训练。
经过数月不懈的努力,新模型终于完成了,得到了一个3%提升的 state-of-the-art 结果。不仅公司的产品将因为这一进步获得巨大的性能提升,数以百万的用户因为这一改进而受益,小张的新论文也有着落了。
数据制表填好,小张把论文发给了正等着写博客宣告这一好消息的市场部同事,满意地关掉了虚拟机,开着特斯拉回家了,感觉今天又为人类做了一件微不足道的好事。
小张不知道的是,数百吨二氧化碳就这样散布到了大气当中。
根据一份提交到自然语言处理顶会 ACL 2019 的论文,三位来自马萨诸塞大学安姆斯特分校的研究者分析了一些主流 NLP 模型训练的碳排放水平。
他们发现,像 Transformer、GPT-2 等时下最火的深度神经网络技术,为 NLP 带来的长足的进展,同时却产生了大量的温室气体排放。
论文的第一作者,马萨诸塞大学安姆斯特分校博士生艾玛·斯特贝尔 (Emma Strubell) 接受了硅星人的中文独家采访。
谈到为什么要做这项研究,斯特贝尔透露,由于学术圈论文通常发布在学术会议上,这篇论文灵感,就是来自于同僚关于坐飞机参加学术会议对环境影响的讨论。
“既然都扯到坐飞机跑会了,为什么不先来探讨一下深度学习训练本身对环境的影响?”斯特贝尔告诉硅星人。
而这次研究的结果让她自己都吓了一跳:其实,深度学习训练的碳排放远超跨国飞行。

论文作者与同事合照 Image Credit: UMass IESL
论文作者首先确定了 NLP 模型训练能耗的量化方式。
然后,他们通过硬件厂商提供的工具 (Nvidia-smi、Intel RAPL 等) 提取 CPU、内存和 GPU 的能耗数值,计算训练的耗电总和,再乘以美国环保署提供的二氧化碳排放量均值(每度电0.954磅,约合433克),就得到了主流 NLP 模型训练的计算成本和环境影响数据:
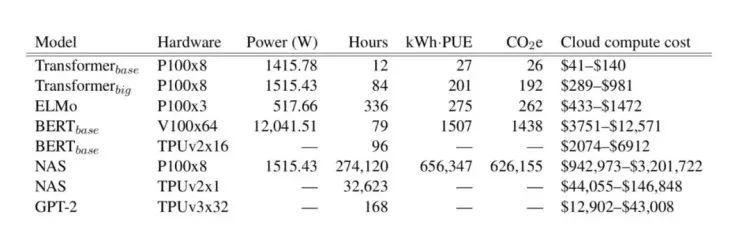
表格显示了 NLP 领域内最顶尖模型的训练用时、能耗效率和碳排放。一个最直观的结果就是:某些新的模型/训练方式取得了最优结果,但是进展微小,副作用却是不成比例的计算量/碳排放增加。
比如 Google AI 今年发布的一篇新论文 The Evolved Transformer 提出的神经网络架构搜索技术,用于英语→德语翻译的 BLEU 分数提高了 0.1,却花费了3.2万 TPU 小时,云计算费高达15万美元。
如果把 TPU 换成八块 P100 GPU,用同样的方式训练同一个 Transformer 达到同样的成绩,将会产生惊人的62.6万磅(约合284公吨)二氧化碳。
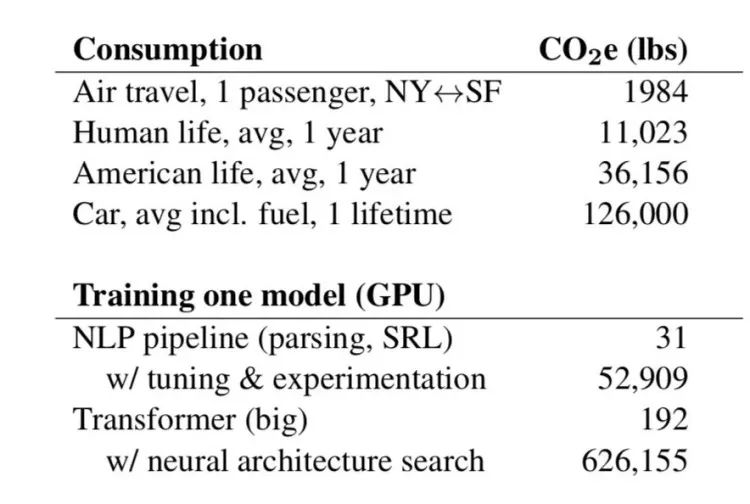
相比较来看,一辆美国的中型汽车,或者中国的 B 级车,从生产到报废的整个寿命周期(12万英里)二氧化碳排放才只有12.6万磅(约合57吨);一个人一生的二氧化碳排放大约是1.1万磅(约合5吨);往返纽约旧金山的民航飞机碳排放均摊到人头约为1984磅(约为900千克),平均每班次200人。
也就是说,用神经网络架构搜索训练一个两亿参数量的 Transformer,碳排放相当于生产五辆汽车再开十年,或者17个人活了一辈子,或者一架波音757从旧金山飞到纽约再返程一半航程的水平。
“讲真,神经网络架构搜索就是我们想要写这篇论文的诱因之一。用如此庞大的计算量,输出结果的改善却如此的微小,基本上算是不负责任了,”斯特贝尔玩笑地表示,
“事实上,我们都看到了 NLP 圈里的确有这样的趋势,不计任何计算量的代价也要追逐哪怕一丁点的准确率提升。这绝对不是一个好的趋势,我觉得我们应该做得更好,用更有创意,而不是纯粹‘加算力’的方式去做研究。”
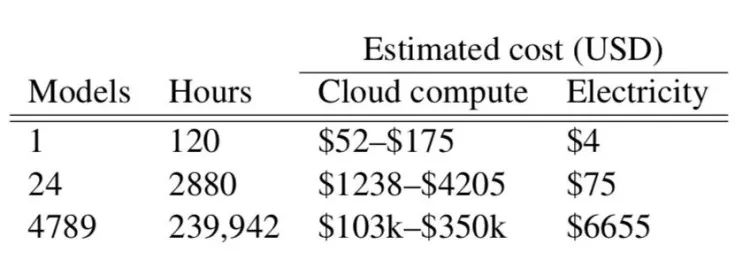
别提 Transformer/神经网络架构搜索,就连训练一个普通模型达到可以发论文的水平,中间的调参、迭代也会消耗大量算力。而考虑到这些模型的研究者通常财力有限,更多使用现成或按需的 GPU,省电减排只能是天方夜谭。
斯特贝尔用她去年推出的一个多任务 NLP 模型 LISA 举例。训练达到最终结果花费了大约6个月的时间,模型迭代将近4800次,使用了60枚 GPU,折合24万 GPU 小时,折合的碳排放达到5.3万磅(约合24吨)
“一次性训练一个模型并不昂贵,然而一旦开始针对新数据集调参,成本立刻水涨船高。”论文写道。

据英国《独立报》2016年援引专家报道,数据中心耗电占全球3%,且耗电量正在以每四年翻一番的速度增长;同时,数据中心的温室气体排放占到全球的2%,碳足迹已经追上民航业。与此同时,基于机器学习的人工智能将成为全球数据中心业务增长的最大驱动力。
了解这些情况后,采访自然进入到了下一个问题:既然模型训练会产生如此不成比例的碳排放,那么 NLP,以及其它深度学习方向的研究,总共为全球温室气体排放贡献了多大比例呢?
(硅星人承认,这个问题的灵感来自于此前《战斗天使阿丽塔》特效渲染导致惠灵顿气温上升的新闻。如果一部电影都能带来如此明显的影响,席卷全球的全球深度学习浪潮难道不会更可怕吗?)
斯特贝尔也表示自己对这个问题的答案很期待,然而现状是:很多人做论文时多少都记录了(或者有能力记录)训练的总用电情况,也能算出能耗效率——出于主观隐瞒,或者能耗数据对于研究本身没有意义等原因,大部分人发论文时都不会把这些数据包含进去,“如果这一现状不改变,我们就不可能准确预测深度学习对全球变暖的影响。”
她希望能通过这篇论文提醒其他 NLP 学者和业界人士,在提高模型表现的同时,也应该对环境影响有主动的、足够的关注。
从信息完整的角度来看,这篇论文的一个很大遗憾就是对基于 TPU 的模型训练能耗和碳排放的数据缺失。斯特贝尔解释这是因为 Google 从未对外公布过 TPU 能耗效率方面的资料,加之这篇论文本身的目的并非力求绝对精准的结果,而是提供一个较为精确的合理预估。
(不过总体来讲,TPU 仍是目前深度学习领域碳排放最小的计算硬件,而且 Google 的数据中心用电56%来自可再生能源,显著高于 AWS 和 Azure。)
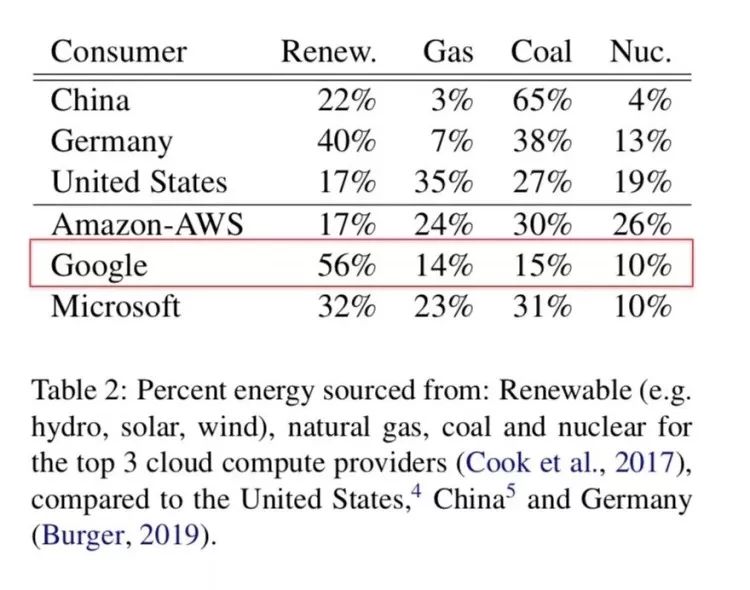
斯特贝尔告诉硅星人,类似的资料不公开情况是她们研究过程中遇到的最大挑战,“我们也希望提供一个更精准的结果,如果 TPU 的能耗信息对外公开就更好了。”
转载声明:本文授权转载自「硅星人」,搜索「guixingren123」即可关注。作者:光谱





