SIGIR2020 | 基于GCN的鲁棒推荐系统研究

近年来,推荐系统已成为所有电子商务平台中必不可少的组件。然而,推荐系统的评分数据通常来自开放平台,而开放平台可能会存在一群恶意用户故意插入虚假反馈,以使推荐系统倾向于他们的偏爱(Shilling Attack)。我们通常假设用户的评分数据始终是可用的,并且这些数据确实可以反映用户的兴趣和偏好。然而此类攻击的存在违反了常规建模的假设。因此,构建一个健壮的推荐系统,即使在出现此类攻击的情况下也能够生成稳定的推荐结果,具有重大的实际意义。
所以,今天给大家推荐的论文是一篇来自于SIGIR2020的关于利用图卷积网络(GCN)提高推荐系统鲁棒性的文章。该文的整体结构框架可见下图。
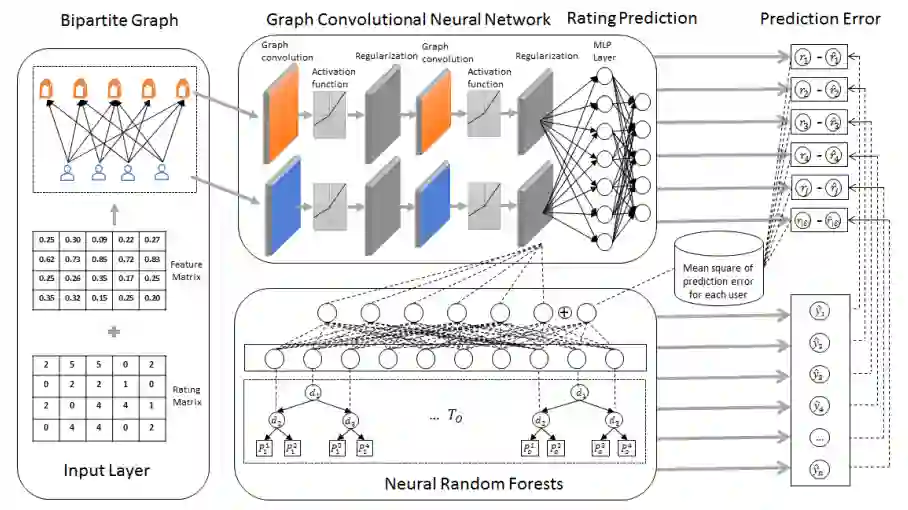
该文提出了一种端到端的统一的学习框架来执行鲁棒的推荐(Robust Recommendation)和欺诈检测(Fraudster Detection)两种任务。在其端到端学习的过程中,基于GCN搭建的推荐组件输出的预测误差可以作为欺诈者检测组件中的重要特征;同时,在欺诈者检测组件中将用户识别为欺诈者的概率可以自动确定该用户的评分数据在推荐组件中的贡献;因此,这两个组件可以相互增强。通过进行广泛的实验,结果表明了该算法在两项任务中的优势-鲁棒的的评分预测和欺诈者检测。
该文的亮点在于将推荐任务和欺诈检测任务互补的结合在一个整体的框架中,推荐组件中的预测误差作为了欺诈检测组件中的特征,欺诈检测组件中的预测结果作为了推荐组件中的特征。同时,该文作者结合异常检测的背景手工进行了特征构造,然后用于GCN的输入,可见要想卷的好,输入特征是关键。最后,该任务的数据集也是关键点,需要区分出一些真实用户和欺诈用户,虽然文章中提到了利用给定的算法来进行区分,但区分算法的好坏直接影响了后续任务的性能。
推荐组件
更具体的,对于基于GCN的推荐组件来看,其损失函数为平方损失。与一般的损失函数不同的是增加了欺诈检测组件中真实用户的概率
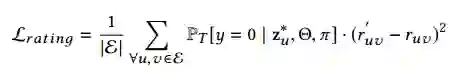
其中值得注意的是,对于图卷积网络(GCN)中的用户结点的属性信息

对于欺诈检测组件来看,就是普通的二分类任务,只不过在这用的分类模型为神经随机森林(Neural Random Forest ),其损失函数为交叉熵损失。
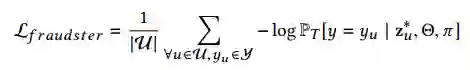
其中值得注意的是,这部分把推荐组件中的预测误差(Prediction Error)作为了该组件的附加特征,具体的公式为:
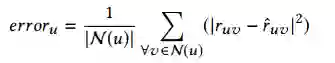
其中,
因此,最终总的损失函数可以表示为两者的总和。
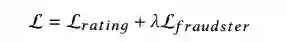
其中,
实验部分略去,大家可阅读原始论文。
论文地址:
dl.acm.org/doi/pdf/10.1145/3397271.3401165
视频讲解:
sigir-schedule.baai.ac.cn/poster/fp0131
欢迎加入推荐系统交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注推荐系统
![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏






