KDD 2019 | 腾讯广告算法团队关于库存预估的一作论文被 KDD 2019 录用

导语:腾讯广告算法团队关于库存预估的论文《 Large-scale User Visits Understanding and Forecasting with Deep Spatial-Temporal Tensor Factorization Framework》被CCF A类学术会议KDD2019录用。论文提出了一种适用于大规模广告库存预估的深度学习算法,对交叉特征以及时间特征进行建模,从而对广告库存进行精确的预估。
介绍
腾讯广告算法团队关于库存预估的论文《 Large-scale User Visits Understanding and Forecasting with Deep Spatial-Temporal Tensor Factorization Framework》被CCF A类学术会议KDD2019录用。论文提出了一种适用于大规模广告库存预估的深度学习算法,对交叉特征以及时间特征进行建模,从而对广告库存进行精确的预估。
1.背景
目前互联网服务中心最主要的商业模式仍然是广告业务,服务方需要提前预知用户的访问量来保证广告的销售,这就需要理解和预测广告库存量。目前使用广泛的预测模型可以大致分为两类:1)利用传统的时间预测模型(ARIMA,GARCH,TBATS等),这些模型在处理大规模的时间序列模型上就显得十分的低效;2)基于深度学习的预测模型(ST-RESNET, TRMF等),已经可以很好的处高维时间序列预测任务,但是这些模型大多只关注时间特征,而忽略的属性组合特征等。为了更好的进行广告库存的时间预测,我们需要解决如下问题:
属性组合数目巨大,并且可能随时改变。我们通常用几个特征组合来描述用户的访问,比如地域、平台、年龄、性别等。随着特征的增多,这些特征组合数目的增长是指数级别的,所以我们需要一个高效易扩展的模型。
属性组合之间的关联性,不同的属性组合我们不能等同的对待。比如年龄和平台具有强相关性,但是年龄和内容的相关性就比较弱。
广告库存同时具有长周期特征和短周期特征,长周期比如每年的春节、暑假等,短周期则多为周级别的特征,算法需要同时兼顾两者的特征。

图1:问题概览
2.模型简介
为了解决上述问题,我们提出来一个DEEP SPATIAL-TEMPORAL FACTORIZATION FRAMEWORK,同时对时间特征和属性组合特征进行建模,并且能够充分利用长周期数据。基本的设计思路来源于张量分解,从图1中可以看出,我们数据可以表示为一个张量(Year,Attribute,Time), 我们需要预估的即图中标记为红色的部分。大致框架如下图表示:

图2:3rd-order张量分解
其中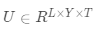
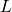
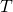
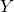
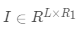
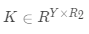
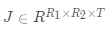
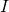
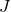
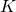
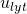
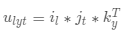
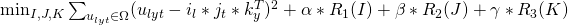
其中Ω表示所有已知元素的集合,和已知的基于矩阵分解方法(比如TRMF)相比,我们加入了年这一维度,考虑了历史同期的规律对于当前预估的影响,这不仅使得模型框架更加通用,并且可以很好的结合历史长周期的数据进行预测。

图3:Deep spatial-temporal tensor factorization forecastingframework
我们将以上张量分解模作为我们的主体框架,我们将我们的模型设计如图3所示,其中包含三个主要部分:
-
Spatial Model: 该部分用以提取属性组合特征。对于输入的属性组合,我们首先利用Attention Embedding提取相同类别属性中不同值之间的相互关系,该机制的存在可以使得我们更加关注关键的输入部分。当获得所有属性的编码之后,我们将其拼接作为DeepCross网络的输入,用以提取不同类别属性之间的关联关系。对于DeepCross网络,通常初始化输入记作
,第 g 层则可以递归的表示为
,其中
是神经网络的参数。
-
Temporal Feature Modeling:受启发于CLDNN,我们将CNN,RNN进行结合用以提取历史数据的时序特征。首先利用CNN进行浅层特征的提取,然后将该特征作为RNN的输入,获得时序特征。其中
表示所有已知年份的M天的历史数据,该部分用以提取时序特征和周期特征,
该部分表示历史同期数据,用以提取长周期特征。
-
Multi-task: 如图3所示,我们有两个任务:1)利用自编码器重构历史数据;2)利用张量分解预估未来的广告库存。我们通过如下公式最小化两者的损失函数:
, 其用来权衡两个任务的权重。通常来说,我们设置η < 0.5,因为我们的主要任务是用来做预测。Multi-task的设计有如下优点:1)最小化信息损失(自编码器);2)共享CNN、RNN等网络层,减少模型复杂度;3)提高预估准确率。
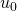
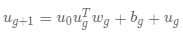
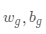
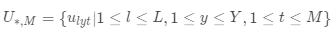
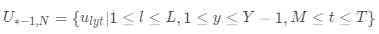
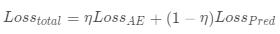
3.实验结果
3.1 参数和时间
传统的时间序列模型比如TBATS或者ARIMA需要对每一个时间序列进行单独的模型预测,所以需要极大的时间,我们在这里不做对比。由于multi-task共享参数的设计导致参数数目的降低,具体数据如下图所示:

表1:参数数目以及训练时间
3.2 实验结果
我们在两个真实的数据集上做了验证实验(腾讯视频前贴片以及PEMS-SF),评价标准我们选择Normalized deviation(ND)和normalized root mean square error (NRMSE),定义如下:

实验结果如下图所示:

图4:28-days 平均ND以及28-days 平均NRMSE
可以看出,ST-TF模型在ND和NRMSE上均获得了最好的表现,分别为0.179和1.093。在腾讯视频前贴片上,ST-TF相对于CNN获得了8.7%的提升,相对于TRMF获得了5.8%的提升。而在PEMS-SF上我们同样获得了最好的表现,相对于CNN和TRMF分别提升9.8%和7.6%。这些提升主要来源于更好的属性组合特征提取的设计以及multi-task等。
4.总结
腾讯广告算法团队的论文《Large-scale User Visits Understanding and Forecasting with Deep Spatial-Temporal Tensor Factorization Framework》引入了张量分解结合深度学习的设计,取得了较好的预估结果。在未来的工作中,我们会不断增强对业务的理解,探索更加准确有效的模型,支撑业务的发展。感谢腾讯品牌广告算法团队和中科大计算机学院下一代移动计算与数据创新实验室的建议和贡献。
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,加入 KDD 顶会交流小组与同行切磋、交流



