详解立体匹配系列经典SGM: (3) 代价聚合
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
作者李迎松授权发布,武汉大学 摄影测量与遥感专业 博士
https://ethanli.blog.csdn.net/article/details/105065660
详解立体匹配系列经典SGM: (1) 框架与类设计 详解立体匹配系列经典SGM: (2) 代价计算
代码已同步于Github开源项目: https://github.com/ethan-li-coding/SemiGlobalMatching
上一篇博客代价计算中,我们介绍了初始代价计算的代码,并做了实验来验证初始代价的计算结果,效果是显而易见的糟糕,但是这个结果有它独特的意义,一方面它告诉大家只算初始代价值很难得到好的视差结果,提醒大家聚合对SGM匹配来说是非常重要的;另一方面,初始代价为聚合代价提供一个初值,如果初值错的离谱(离谱的意思是几乎所有像素都无法算出正确视差,图中可以隐约看到有很多像素还是能算出大概正确的视差的,能担任合格的初值),也会让聚合结果大打折扣。
让我们再次近距离感受下它!

好了,闲话不多说,我们来揭开神秘的代价聚合步骤的面纱!
视差主序
看过前篇的同学们肯定已经接触了视差主序的概念,我再次重申一遍是因为它很重要,关系到我如何存取代价数组的值。
我们谈到主序,大家会想起二维数组中数据的存储方式,如果是行主序,则数据优先在行内按顺序紧密排列,即第0行第0列和第0行第1列是相邻的元素;如果是列主序,则数据优先在列内按顺序紧密排列,即第0行第0列和第1行第0列是相邻的元素。主序类型,决定了通过行列号计算元素在数组中相对首地址的位置偏移量的方式,也决定了数组采用哪种遍历顺序会更高效(缓存原理)。
代价数组有三个维度:行、列、视差,视差主序的意思是同一个像素点各视差下的代价值紧密排列,即代价数组元素的排列顺序为:
(0,0)像素的所有视差对应的代价值;
(0,1)像素的所有视差对应的代价值;
…
…
(0,w-1)像素的所有视差对应的代价值;
(1,0)像素的所有视差对应的代价值;
(1,1)像素的所有视差对应的代价值;
…
…
第(h-1,w-1)个像素的所有视差对应的代价值;
这样排列的好处是:单个像素的代价值都挨在一起,聚合时可以达到很高的存取效率。这对于大尺寸影像来说可带来明显的效率优势,对于像CUDA这类存储效率至关重要的平台来说就有明显优势。
视差主序下,
(i,j,d)
cost[i * width * disp_range + j*disp_range + d]
大家思考下为何是这样获取,理解下视差主序的含义。
介绍完主序方式,就可以开始摄入正餐了!
左右路径聚合
其实所有路径的聚合可以放到一个循环体中实现,但是为了更清晰,我们把为每一条路径的聚合都单独实现,最后把所有路径的聚合值相加,就得到最终多路径的聚合值。这样还可以方便的选择任意路径的组合,来测试实验效果。
我另外开辟了8个聚合代价数组
// ↘ ↓ ↙ 5 3 7
// → ← 1 2
// ↗ ↑ ↖ 8 4 6
/** \brief 聚合匹配代价-方向1 */
uint8* cost_aggr_1_;
/** \brief 聚合匹配代价-方向2 */
uint8* cost_aggr_2_;
/** \brief 聚合匹配代价-方向3 */
uint8* cost_aggr_3_;
/** \brief 聚合匹配代价-方向4 */
uint8* cost_aggr_4_;
/** \brief 聚合匹配代价-方向5 */
uint8* cost_aggr_5_;
/** \brief 聚合匹配代价-方向6 */
uint8* cost_aggr_6_;
/** \brief 聚合匹配代价-方向7 */
uint8* cost_aggr_7_;
/** \brief 聚合匹配代价-方向8 */
uint8* cost_aggr_8_;
而左右路径,就是在同一行内从左到右执行聚合,上面的1-2方向,如图:
我们再来看代价聚合公式:
像素p沿着某条路径r的路径代价计算公式
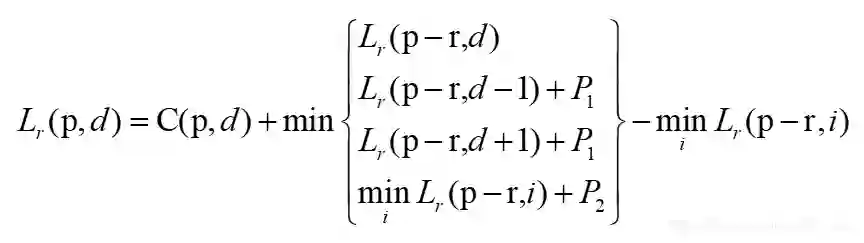
公式中代表像素,代表路径,左右路径的情形下, p−r就是 p左侧(从左到右聚合)或者右侧(从右到左聚合)的相邻像素,他们行号相等,列号相差1。 L是聚合代价值, C是初始代价值。
我们分析下这个公式,一个像素的聚合代价值 L等于它的初始代价值 C加上四个运算值的最小值再减去另一个最小值(这个最小值也在前面四个运算值内,不用重复计算)。而这四个运算值的含义是什么呢?直接告诉你们:
L(p−r,d)表示路径内上一个像素视差为d时的聚合代价值
L(p−r,d−1)表示路径内上一个像素视差为d-1时的聚合代价值
L(p−r,d+1)表示路径内上一个像素视差为d+1时的聚合代价值
min(L(p−r,i))表示路径内上一个像素所有代价值的最小值
P1为惩罚项 P1,输入参数
P2为惩罚项 P2,计算方式是 P2init/(Ip−Ip−r), I表示灰度, P2init为 P2的最大值,输入参数
这几个值都是可以直接计算出来的,可以看到聚合时就是简单的加减,基本没什么复杂的运算。
首先我们做一个初始化,就是让第一个像素的聚合代价值等于它的初始代价值(没办法啊,它路径上没有上一个像素,牺牲自己成全大家吧),这样我们从路径上第二个像素开始聚合。
其次,我们开辟一个临时的数组来存放路径上上个像素的聚合代价值,这样的好处是我们在聚合当前像素时,在局部小内存块里读取上一个像素的代价值速度更快(全局的空间辣么大,找位置都要逛半天当然慢了)。
最后,我们定义一个临时的最小代价值,来记录路径上上一个像素的聚合代价值,因为在计算当前像素的所有聚合代价时,就可以顺便把最小值给算了,保存下来给下个像素用。
最后最后,我们遍历路径上所有像素,按照公式来加减完事。
最后最后最后,说明一下,我把左右路径的两个方向都放到一个函数里,通过参数is_forward来控制是从左到右聚合还是从右到左聚合,因为两者移动方向是正好相对,起始位置是同一行的两端,简单来说就是1个是列号 + 1,一个是列号 - 1。
代码如下:
void sgm_util::CostAggregateLeftRight(const uint8* img_data, const sint32& width, const sint32& height, const sint32& min_disparity, const sint32& max_disparity,
const sint32& p1, const sint32& p2_init, const uint8* cost_init, uint8* cost_aggr, bool is_forward)
{
assert(width > 0 && height > 0 && max_disparity > min_disparity);
// 视差范围
const sint32 disp_range = max_disparity - min_disparity;
// P1,P2
const auto& P1 = p1;
const auto& P2_Init = p2_init;
// 正向(左->右) :is_forward = true ; direction = 1
// 反向(右->左) :is_forward = false; direction = -1;
const sint32 direction = is_forward ? 1 : -1;
// 聚合
for (sint32 i = 0u; i < height; i++) {
// 路径头为每一行的首(尾,dir=-1)列像素
auto cost_init_row = (is_forward) ? (cost_init + i * width * disp_range) : (cost_init + i * width * disp_range + (width - 1) * disp_range);
auto cost_aggr_row = (is_forward) ? (cost_aggr + i * width * disp_range) : (cost_aggr + i * width * disp_range + (width - 1) * disp_range);
auto img_row = (is_forward) ? (img_data + i * width) : (img_data + i * width + width - 1);
// 路径上当前灰度值和上一个灰度值
uint8 gray = *img_row;
uint8 gray_last = *img_row;
// 路径上上个像素的代价数组,多两个元素是为了避免边界溢出(首尾各多一个)
std::vector<uint8> cost_last_path(disp_range + 2, UINT8_MAX);
// 初始化:第一个像素的聚合代价值等于初始代价值
memcpy(cost_aggr_row, cost_init_row, disp_range * sizeof(uint8));
memcpy(&cost_last_path[1], cost_aggr_row, disp_range * sizeof(uint8));
cost_init_row += direction * disp_range;
cost_aggr_row += direction * disp_range;
img_row += direction;
// 路径上上个像素的最小代价值
uint8 mincost_last_path = UINT8_MAX;
for (auto cost : cost_last_path) {
mincost_last_path = std::min(mincost_last_path, cost);
}
// 自方向上第2个像素开始按顺序聚合
for (sint32 j = 0; j < width - 1; j++) {
gray = *img_row;
uint8 min_cost = UINT8_MAX;
for (sint32 d = 0; d < disp_range; d++){
// Lr(p,d) = C(p,d) + min( Lr(p-r,d), Lr(p-r,d-1) + P1, Lr(p-r,d+1) + P1, min(Lr(p-r))+P2 ) - min(Lr(p-r))
const uint8 cost = cost_init_row[d];
const uint16 l1 = cost_last_path[d + 1];
const uint16 l2 = cost_last_path[d] + P1;
const uint16 l3 = cost_last_path[d + 2] + P1;
const uint16 l4 = mincost_last_path + std::max(P1, P2_Init / (abs(gray - gray_last) + 1));
const uint8 cost_s = cost + static_cast<uint8>(std::min(std::min(l1, l2), std::min(l3, l4)) - mincost_last_path);
cost_aggr_row[d] = cost_s;
min_cost = std::min(min_cost, cost_s);
}
// 重置上个像素的最小代价值和代价数组
mincost_last_path = min_cost;
memcpy(&cost_last_path[1], cost_aggr_row, disp_range * sizeof(uint8));
// 下一个像素
cost_init_row += direction * disp_range;
cost_aggr_row += direction * disp_range;
img_row += direction;
// 像素值重新赋值
gray_last = gray;
}
}
}
上下路径聚合
左右路径描述的太累,上下可以偷个懒 ,左右是在同一行,上下就是同一列,左右是列号+/-1,上下就是行号+/-1。
代码如下:
void sgm_util::CostAggregateUpDown(const uint8* img_data, const sint32& width, const sint32& height,
const sint32& min_disparity, const sint32& max_disparity, const sint32& p1, const sint32& p2_init,
const uint8* cost_init, uint8* cost_aggr, bool is_forward)
{
assert(width > 0 && height > 0 && max_disparity > min_disparity);
// 视差范围
const sint32 disp_range = max_disparity - min_disparity;
// P1,P2
const auto& P1 = p1;
const auto& P2_Init = p2_init;
// 正向(上->下) :is_forward = true ; direction = 1
// 反向(下->上) :is_forward = false; direction = -1;
const sint32 direction = is_forward ? 1 : -1;
// 聚合
for (sint32 j = 0; j < width; j++) {
// 路径头为每一列的首(尾,dir=-1)行像素
auto cost_init_col = (is_forward) ? (cost_init + j * disp_range) : (cost_init + (height - 1) * width * disp_range + j * disp_range);
auto cost_aggr_col = (is_forward) ? (cost_aggr + j * disp_range) : (cost_aggr + (height - 1) * width * disp_range + j * disp_range);
auto img_col = (is_forward) ? (img_data + j) : (img_data + (height - 1) * width + j);
// 路径上当前灰度值和上一个灰度值
uint8 gray = *img_col;
uint8 gray_last = *img_col;
// 路径上上个像素的代价数组,多两个元素是为了避免边界溢出(首尾各多一个)
std::vector<uint8> cost_last_path(disp_range + 2, UINT8_MAX);
// 初始化:第一个像素的聚合代价值等于初始代价值
memcpy(cost_aggr_col, cost_init_col, disp_range * sizeof(uint8));
memcpy(&cost_last_path[1], cost_aggr_col, disp_range * sizeof(uint8));
cost_init_col += direction * width * disp_range;
cost_aggr_col += direction * width * disp_range;
img_col += direction * width;
// 路径上上个像素的最小代价值
uint8 mincost_last_path = UINT8_MAX;
for (auto cost : cost_last_path) {
mincost_last_path = std::min(mincost_last_path, cost);
}
// 自方向上第2个像素开始按顺序聚合
for (sint32 i = 0; i < height - 1; i ++) {
gray = *img_col;
uint8 min_cost = UINT8_MAX;
for (sint32 d = 0; d < disp_range; d++) {
// Lr(p,d) = C(p,d) + min( Lr(p-r,d), Lr(p-r,d-1) + P1, Lr(p-r,d+1) + P1, min(Lr(p-r))+P2 ) - min(Lr(p-r))
const uint8 cost = cost_init_col[d];
const uint16 l1 = cost_last_path[d + 1];
const uint16 l2 = cost_last_path[d] + P1;
const uint16 l3 = cost_last_path[d + 2] + P1;
const uint16 l4 = mincost_last_path + std::max(P1, P2_Init / (abs(gray - gray_last) + 1));
const uint8 cost_s = cost + static_cast<uint8>(std::min(std::min(l1, l2), std::min(l3, l4)) - mincost_last_path);
cost_aggr_col[d] = cost_s;
min_cost = std::min(min_cost, cost_s);
}
// 重置上个像素的最小代价值和代价数组
mincost_last_path = min_cost;
memcpy(&cost_last_path[1], cost_aggr_col, disp_range * sizeof(uint8));
// 下一个像素
cost_init_col += direction * width * disp_range;
cost_aggr_col += direction * width * disp_range;
img_col += direction * width;
// 像素值重新赋值
gray_last = gray;
}
}
}
总路径聚合
秉着篇幅太长不好的原则,为看客着想,嘿嘿,本篇就只先介绍左右路径和上下路径,也就是4-路径聚合。其实这也是一种常用的方式,因为有的实际应用非常看重效率,而效果则可以有所牺牲,4-路径往往是不错的选择。
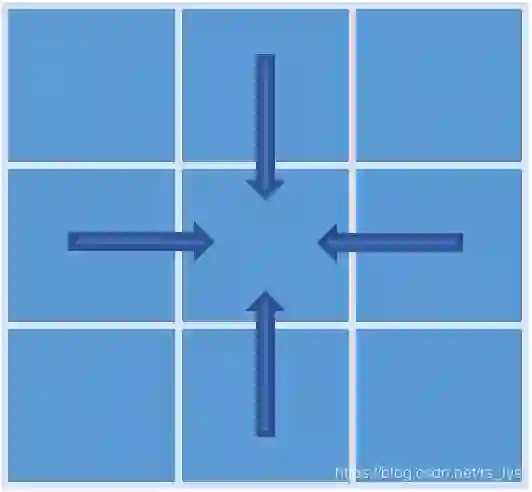
在计算完左右路径和上下路径的聚合代价值后,把这四个加起来,就得到最终的多路径聚合代价值。所以我们的代价聚合方法实现如下:
void SemiGlobalMatching::CostAggregation() const
{
// 路径聚合
// 1、左->右/右->左
// 2、上->下/下->上
// 3、左上->右下/右下->左上
// 4、右上->左上/左下->右上
//
// ↘ ↓ ↙ 5 3 7
// → ← 1 2
// ↗ ↑ ↖ 8 4 6
//
const auto& min_disparity = option_.min_disparity;
const auto& max_disparity = option_.max_disparity;
assert(max_disparity > min_disparity);
const sint32 size = width_ * height_ * (max_disparity - min_disparity);
if(size <= 0) {
return;
}
const auto& P1 = option_.p1;
const auto& P2_Int = option_.p2_init;
// 左右聚合
sgm_util::CostAggregateLeftRight(img_left_, width_, height_, min_disparity, max_disparity, P1, P2_Int, cost_init_, cost_aggr_1_, true);
sgm_util::CostAggregateLeftRight(img_left_, width_, height_, min_disparity, max_disparity, P1, P2_Int, cost_init_, cost_aggr_2_, false);
// 上下聚合
sgm_util::CostAggregateUpDown(img_left_, width_, height_, min_disparity, max_disparity, P1, P2_Int, cost_init_, cost_aggr_3_, true);
sgm_util::CostAggregateUpDown(img_left_, width_, height_, min_disparity, max_disparity, P1, P2_Int, cost_init_, cost_aggr_4_, false);
// 把4/8个方向加起来
for(sint32 i =0;i<size;i++) {
cost_aggr_[i] = cost_aggr_1_[i] + cost_aggr_2_[i] + cost_aggr_3_[i] + cost_aggr_4_[i];
if (option_.num_paths == 8) {
cost_aggr_[i] += cost_aggr_5_[i] + cost_aggr_6_[i] + cost_aggr_7_[i] + cost_aggr_8_[i];
}
}
}
实验
实验是大家喜闻悦见的一节,是骡子是马得拿出来溜溜啊!
不知道大家对我在博客代价聚合的最后一张图有没有印象,是单独只执行一个路径的效果以及执行全路径的效果,在这里我也以这样的方式来实验。
首先贴核线像对:

实验(1):只做从左到右聚合:

实验(2):只做从右到左聚合:

实验(3):只做从上到下聚合:

实验(4):只做从下到上聚合:

实验(5):从左到右+从右到左聚合:

实验(6):从上到下+从下到上聚合:

实验(7):4-路径全聚合:

这样来看实验结果,思路就清晰多了。最后的全路径结果效果还是可以的,除了有些细节处需要优化,一方面可以让4-路径变成8-路径甚至16-路径;另一方面剔除错误匹配也是必须做的。
好了,我们本篇到此为止,容我歇会喝喝茶放松放松手指。下一篇我们继续介绍8-路径,以及常用的视差优化手段,如子像素计算、一致性检查等。最后大家对完整代码感兴趣,请移步Github/GemiGlobalMatching下载全代码,点下右上角的star,有更新会实时通知到你的个人中心!。
敬礼!
从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life

