云知声入选 ACL 2020 的三篇论文,都研究了什么?

编辑 | 丛末



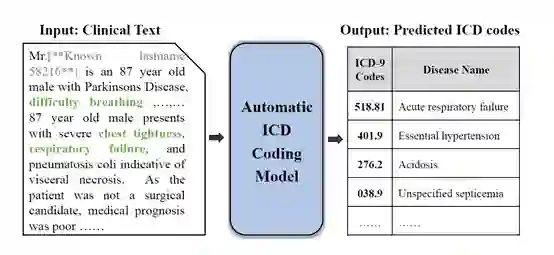

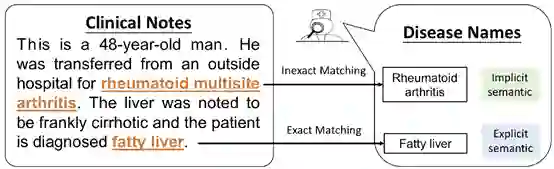

 点击“阅读原文” ,观看直播回放视频
点击“阅读原文” ,观看直播回放视频
登录查看更多
相关内容
Arxiv
3+阅读 · 2019年6月26日
Arxiv
5+阅读 · 2018年7月21日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年6月26日
Arxiv
5+阅读 · 2018年7月21日