词汇量不同不相为谋?高频词藏着人类思维基本模式

早在 1935 年,美国语言学家乔治·齐普夫 (George Zipf) 就曾有一项非凡的发现。齐普夫对高频词与低频词之间的关系感到好奇。所以他统计了在日常语言中单词出现的频率,并根据使用频率对单词进行了排序。
这一统计揭示出了明显的规律性。齐普夫发现,一个词的使用频率与其在频率排序中的位置成反比。因此,第二常用的单词的使用频率似乎是最常用词的一半。而排名第三的单词的使用频率约是最常用词的三分之一,以此类推。
在英语中,最常用的单词是 the,占所有单词的 7%,其次是 and,占 3.5%,以此类推。实际上,约有 135 个单词占所有单词出现次数的一半。所以有一些单词经常出现,而大多数词则几乎从不出现。
但这是为什么呢?一种有趣的解释是大脑以一种不同的方式处理高频词,研究齐普夫分布应该会极大加深我们对于这一大脑活动过程的理解。
但有一个问题: 语言学家并不都认同词频的统计分布是认知过程的结果。相反,一些语言学家认为这种分布是由于对低频词的统计误差所产生的,统计误差也有可能产生类似的分布。
当然,这就需要我们对更多语言进行更大规模的研究。这样一项大规模的研究将更具统计学意义,得以厘清这些观点上的分歧。
现在,得益于中国传媒大学的于水源教授及其同事的工作,我们有了这样的一项研究。他们从取自包括印欧语系、乌拉尔语系、阿尔泰语系、高加索语系、汉藏语系、德拉威语系、亚非语系等在内的多个语系的 50 种语言中发现了齐普夫定律。
于水源等人表示,这些语言中的词频有着共同的结构,该结构和统计误差结构并不相同。而且,他们还表示,这个结构表明,大脑处理高频词的方式确实与处理低频词的方式不同,这一概念对于自然语言处理和文本自动生成具有重要影响。
于水源等人的研究方法很简单。他们从两个大型文本集合开始,即英国国家语料库和莱比锡语料库。这些语料库中涵盖了来自 50 种不同语言的样本,每个样本包含有至少 30,000 个句子和多达 4300 万个单词。
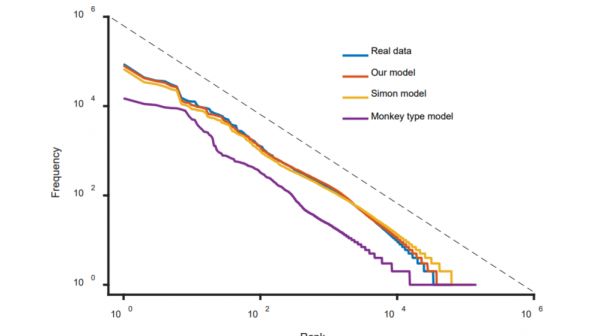
研究人员发现,所有这些语言中的词频都遵循一个修正后的齐普夫定律,修正后的齐普夫定律可分为三段。“统计结果表明,齐普夫定律在 50 种语言中都具有三段结构模式,每个分段都表现出独特的语言属性,”他们说。

这个结构很有趣。于水源等人试图用一些模型来模拟这个结构去创建单词。其中一种模型是猴子打字机模型,在这个模型下,字母随机出现,只要出现空格就算一个单词。
这个过程产生了像齐普夫定律那样的幂律分布。然而,它无法产生于水源等人所发现的三段式结构。而在涉及低频词统计错误的统计结果中,也无法产生这样的结构。
然而,于水源等人通过一种叫做双重加工理论的大脑工作模型复制出了这种结构。这种观点认为大脑在以两种不同的方式运作。
第一种方式是快速直观的思考,几乎不需要任何推理。通常认为我们进化出的这种思维方式允许人类在受到威胁的情况下迅速作出反应。它通常可以为困难的问题提供良好的解决方案,例如模式识别,但它也很容易被非直观的情形所欺骗。
然而,人类能做出比这理性得多的思考。第二种思维方式相对慢些,更慎重也更深思熟虑。这种思维方式使我们能更解决更为复杂的问题,例如数学难题等等。
这种双重加工理论表明,例如 the、and、if 等等高频词是被快速、直观的思考方式处理的,因此使用频率就更高。这些词汇构成了句子的主干。
而像“hyphothesis”、“齐普夫定律”(Zipf’s Law)这样的低频词和短语的使用则需要更多慎重的思考。也因为这样,这些词的使用频率就更低。
实际上,于水源等人在模拟这个双重加工模型时,发现了 50 种不同的语言中的词频分布存在相同的三段式结构。
第一段反映了高频词的分布,最后一段反映了低频词的分布,而中间段则是前后两段的交叠部分。“这些结果表明语言中的齐普夫定律是由类似于双重加工模型这样的控制人类语言行为的认知机制所驱动的,”于水源等人表示。
这是一项有趣的研究。近年来,人类大脑以两种不同的方式处理信息的这一观点有相当大的发展势头,特别是因为诺贝尔奖获奖心理学家丹尼尔·卡尼曼(Daniel Kahneman)的《思考,快与慢》这本书,对这一观点进行了深入的研究。
以下是一个激发快思考与慢思考的经典问题:
“一个球拍和一颗球共花费了 1.1 美元。其中球拍比球贵 1 美元。请问球多少钱?”
答案当然是 5 美分。但是几乎所有人的本能都是先想到 10 美分。这是因为 10 美分给人的感觉差不多是对的,它的数量级正确,而且在问题的框架中存在暗示。而这个答案则是从大脑快速、直观的部分得出的。
但这个答案是错的。我们需要需要大脑更慢、更慎重的部分进行计算才能得出正确的答案。
于水源等人认为在句子生成的过程中, 也有同样的双重加工处理过程。你大脑中快速思考的部分产生出句子的基本结构。而其它词语则需要大脑更缓慢、更慎重的部分生成。
就是这种双重加工引出了三段式的齐普夫定律。
这一研究应该会对研究自然语言处理的计算机科学家带来有趣的影响。这一领域得益于近年来的巨大进步——不仅源于机器学习算法的进步,还源于像谷歌这样的公司收集的大型文本数据库。
但人工生成自然语言仍然十分困难。你只要与 Siri,Cortana,还有谷歌助手聊上一会儿,就会发现他们会话能力还多么有限。
所以, 更好地理解人类如何生成句子必然会很有用。如果齐普夫还在,一定也会为之神往。
-End-





