比朴素贝叶斯更优秀的情感分析方法?答案在这里

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
例如,我们可以为客户识别提及价格的 100 条评论,通过分析这些评论的星级,我们可能会发现 80%的评论是积极的,评论的平均评分为 4.0。但是,这种方法仍有改进的空间:提及价格的积极评价不一定代表对价格满意。例如:
食物很棒,服务绝对优秀。但是这家咖啡店风格的餐厅价格非常高。
这个 5 星的评价显然是对餐厅的价格不太满意。我们需要一个模型来告诉我们句子或子句表达的情绪,以了解是哪些元素影响了评分等级。下面是我们为构建自己的情感挖掘工具而开发并使用的一些技术。

情感分析:了解线上用户表达的情绪
朴素贝叶斯是首选,也是最容易进行文本情感分类的方法。它基于条件概率的贝叶斯公式:
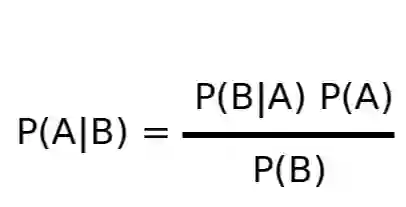
我们用 Bag of Words 来表示一个文本,它是句子中每个单词 w 的一个特征“单词出现 f 次”,f 是句子中 w 出现的频率。假设朴素贝叶斯认为这些特征是独立的,这个公式可以帮助我们推断出句子为正的概率(A)即每个 w 中 w 出现了 f 次(B)。实际上,我们可以根据频率从足够大的数据集中推导出句子为正(A)的概率,每个特征的概率,以及是它们重合(B)的概率。在 10000 个已注释句子的训练集上训练该模型,我们得到一组信息特征,这有助于预测句子是正面还是负面评价。以下是我们获得的 10 个最有代表性的特征:

朴素贝叶斯分类器的信息特征
这种方法最容易实现,它最大的优点在于完全透明。在处理时我们会知道分类器发现了一组包含强烈的正面或强烈负面信息的单词,所以我们可以用这种方法对句子进行分类。
但是,这种方法有几个缺点。
首先,它无法确定中立信息。事实上,词语可以具有正面或负面的意义(“好”,“太棒了”,“可怕”......),但有些词是中性的。通常情况下,正是缺乏这种带有积极或消极意义的词汇或句子结构,才让句子缺失了明确的情感意义。但 Bag of Words 表示不能解决这个问题。
它也无法理解强度和否定意义。例如,“比较好”和“相当好”,第一个比第二个词汇出现在正面语句中的几率更大。我们尝试了一些方法来解决这个问题:添加一个有意义的双字母组列表(这意味着我们将“非常好”作为单个单词读取),或者在双字母组上训练模型而不是在单个单词上训练,但两者对我们的模型都没有太大的改进。大多数情况下模型无法识别否定,因为它不考虑单词顺序。
最重要的是,朴素贝叶斯模型在解决局部情绪分析问题方面表现不佳。在长篇文章中,具有高频率的积极情绪词,如“非常好的”、“美味”等很可能表达了作者积极的情绪。但是,由于我们的目标是确定 local sentiment,我们需要处理短句和子句的工具。(星级评分可以告诉我们作者的整体情绪。)句子中没有足够的词汇,所以我们需要非常精确地理解语义结构。
Bag of Words 表示是一种非常糟糕的方法。例如,“食物本可以更美味”这个句子,模型检测到与正面感觉有关的“美味”这个词,但不明白“本可以”表示一种否定或细微差异。许多短句都是这样的,仅依靠小型句子数据集会把准确率从大约 77%拉低到小于 65%。
为了改善朴素贝叶斯方法并使其适合短句情绪分析,我们添加了一些规则,加入否定、强度标记(“更多”、“极端”、“绝对”、“最”等)、细微差别和其他语义结构,以及经常出现在情绪短语附近并改变其含义的语义结构。例如,在“食物不是很美味”中,我们需要明白“不太好吃”比“不好吃”或“根本不好吃”更积极一点。
我们利用朴素贝叶斯训练的结果建立了一个积极和消极的词汇库。当处理给定的句子时,我们将每个单词打为正分或负分,并通过基于开源库 spaCy 的管道进行语音结构的精确分析来计算总分数,用于词性标注和依赖性分析。结果,我们得到了正、负和中性分数的参数,中性分数被定义为句子中既不是正面也不是负面情绪单词的比例。我们使用深度学习技术从训练集中推导出这些得分与情绪之间的关系。以下是我们针对消极、中性和正面情绪句子获得的图表:
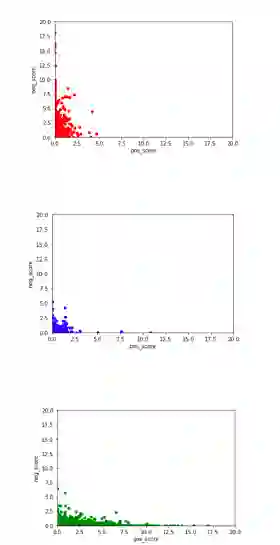
该模型可以帮助我们很好地判断一个表达性句子包含的是正面还是负面情绪(准确度约为 75%),但是很难理解中性或缺乏情感的句子(在我们的测试集中,这类句子识别的准确率只有 20%) 。这种方法比朴素贝叶斯要好得多,但 75% 仍然低于当前最新的正向 / 负向决策技术。
原文链接:
https://medium.com/@samuelpilcer/sentiment-analysis-frequency-based-models-288c0accdd12

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!