谷歌、Facebook已成数据寡头,去中心化数据交换打破垄断

只有少数几家公司能够获得大数据、人工智能和机器学习的能力,可以将其转化为产品。这造成了数据拥有者和数据贫乏者之间不平等的鸿沟,以及大数据行业的寡头垄断。打破寡头垄断的最佳方式就是“用开放数据的海洋淹没数据竖井”。
只有少数几家公司能够获得大数据、人工智能和机器学习的能力,可以将其转化为产品。这造成了数据拥有者和数据贫乏者之间不平等的鸿沟,以及大数据行业的寡头垄断。打破寡头垄断的最佳方式就是“用开放数据的海洋淹没数据竖井”。
数据是现代商业的燃料,每个公司都需要很多数据,但很少有人能负担得起。

只有少数几家公司能够获得大数据、人工智能和机器学习的能力,可以将其转化为产品。这造成了数据拥有者和数据贫乏者之间不平等的鸿沟,以及大数据行业的寡头垄断(包括被称为FANG的Facebook、Amazon、Netflix和Google)。扎克伯格、盖茨、贝索斯等人已经成为数据大亨,无异于石油大亨洛克菲勒。
两个数据大亨的故事
虽然AI是贪婪的数据消费者,是依赖于大量的数据发展起来的,但大多数公司要么拥有大量潜在的数据却没有能使用这些数据的AI,要么有AI算法却没有足够的数据。
这是为什么呢?主要是因为寻找拥有AI知识的人才的竞争十分激烈,成本也很昂贵,更别说AI专家。大型科技公司正以高昂的初始工资从大学直接招聘AI毕业生。成本有多高呢?举个例子,前谷歌自动驾驶部门工程师Anthony Levandowski在离开谷歌的前一年,拿到了1.2亿美元的工资和奖金。
另一方面,很多拥有AI知识的毕业生正在创办自己的科技公司,但却无法获得开发产品所需的大量数据。
FANG公司已经成为数据的OPEC(石油输出国组织)了吗?
在互联网时代的初期,webgraph(一种网页相互连接的图)是开放的,拉里·佩奇和谢尔盖·布林得以学习和创新,创建了谷歌公司。但从那时起,webgraph的重要性就逐渐减弱,取而代之的是社交图(social graph)。
从60年代开始,social graph曾是一个人具有的人际网络和人际关系的网络效应的写照。
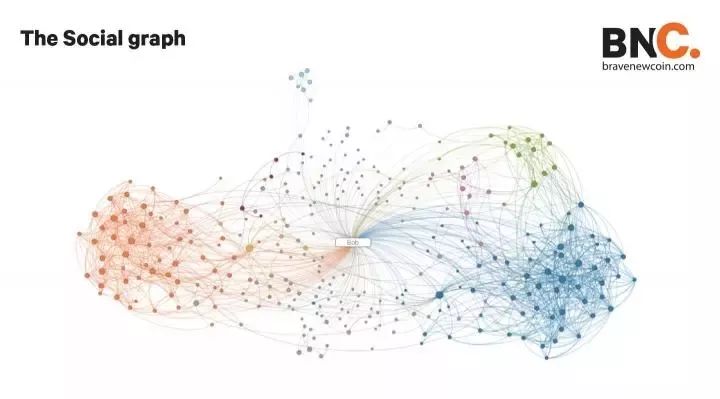
然而,Facebook拥有超过20亿用户,它重新定义了 social graph,成为了最具包容性的一个 social graph,并创建了一个指数级的将个人以及他们的朋友与企业、服务、社交活动、喜恶等等联系在一起的网络。而在数据经济中,这是企业所追求的。
尽管仍然很重要,但webgraph的主要价值来源是计算网站的PageRank;拥有用户在线偏好和倾向的详细数据就是数字广告商的圣杯。
Facebook的social graph可以说已经成为网络上最赚钱的生态系统,并且与其他数据寡头(谷歌、亚马逊、Netflix、微软)一样,它具有数据网络效应,这种效应发生在机器学习驱动的产品随着用户数据的增加而变得更智能时。这就在商业环境,尤其是数字广告领域创造出一个赢家,使得其他人越来越难以参与竞争。
2015年,Google和Facebook在全球数字广告支出中的比例达到40%。2016年第三季度,Google和Facebook占了美国数字广告收入增长的99%——这是有史以来的最高的比例。2017年,它们占了美国数字广告支出总额的63%以上。虽然Amazon和Snapchat的进入使得它们的增长速度放慢,但要打破这种数字双寡头垄断局面将是非常困难的。
石油输出国组织(OPEC)是一个由14个石油生产国组成的政府间组织,它们占全球石油产量的44%,占全球探明室友储量的73%。这使得OPEC能对全球原油价格产生重要影响。
虽然没有证据表明数据寡头之间存在这种“卡特尔主义”,但Facebook和Google两家公司占有如此大的市场份额和无限量的数据供应,它们将如何影响全球数字广告的价格呢?
数据的护城河,湖泊和海洋
“护城河”(moat)是从巴菲特的投资理论中借用的一个术语,描述了公司周围的经济防御层——无论是知识产权(IP),品牌还是员工——护城河让公司能在同行业中优于竞争对手。 “数据护城河”(data moats)已成为互相竞争的科技公司之间保护知识产权的一种形式。
数据湖泊(Data lakes)是组织内部所有部门输入的原始数据池。这与组织内部门间相隔离的数据是不同的,这些数据不会跨部门共享。因此,一个组织可能拥有大量有关个人客户的数据(他们的社交习惯、购买习惯、沟通习惯等),但这些数据是分散的,难以编制成完整的个人档案。
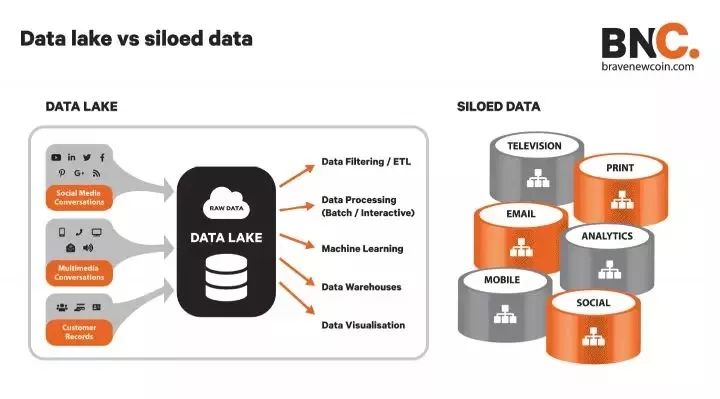
数据湖泊以本地格式保存大量的原始数据。与将数据存储在文件或文件夹中的分层数据库不同,数据湖使用平面架构来存储数据。因此,它在很大程度上是非结构化的,是非关系型的(NoSQL)数据,直到出现一个特定的问题需要使用数据查询,才将其细化为相关的模式。
数据是一门大生意;大数据更是一笔巨大的业务。但是一个行星大小的数据库怎么样?对于广告商和AI开发人员来说,这会成为圣杯吗?
迈向数据海洋
海洋协议(Ocean Protocol)是一个去中心化的全球数据交换协议,旨在让企业和个人可以通过本地海洋令牌购买和销售数据,其目的是解锁大数据,并向更多人开放AI开发。该项目背后的理念是,对集中式数据库缺乏信任会阻止竞争者之间共享数据。
Ocean Protocol由BigchainDB的联合创始人Trent McConaghy创立,Ocean是区块链项目生态系统的一部分(见下图),旨在将数据、计算能力和存储去中心化和民主化,以缩小大型科技企业之间的差距。
在2016年,世界上已经产生16ZB(16zettabytes或16,000,000,000,000,000,000,000字节)的数据,但实际上被分析的数据只有1%,而在这1%的数据中,只有少数公司有办法优化数据。

这些项目的最终目标之一是让人们重新控制和掌握数据,而不是试图让数据大亨放弃数据。
民主化未来的数据经济
去中心化数据交换可以有哪些帮助?
医疗保健是可获取外部数据的一个领域,并且将产生深远的影响。例如,如果在大型数据集上进行测试,医疗药物试验对特定人群或性别的效力的偏差可能远远低于单一医院或实验室所能获得的结果。
一项利用AI来获得结论或为某种疾病研发有效产品的医疗项目需要1万名患者的数据,才能获得较低的错误率,这对于单一医院来说几乎是不可能的。去中心化的数据市场的作用就在这里。
在测试任何软件或算法时,保持低错误率是一个目标,而最简单和最便宜的方法并不是要改进或编写更复杂的算法,而是要在旧算法上运行大量数据,或者如Trent McConaghy所描述的那样:“ 用CSV文件替换Phds——这在2000年代使得错误率大大减少,有更多AI得以部署。“
自动驾驶汽车是另一个出错率必须接近0的领域,因为我们要有足够的信任才能把生命真正地交给计算机。据估计,需要5000亿到1万亿英里的行驶距离,才能使AI模型足够精确,能够用于自动驾驶汽车的生产部署。
另外,Avdex是一种去中心化的航空数据交换。
“像Google和Facebook这样的公司意识到,如果它们将这些数据存储起来,就会产生数据网络效应,”McConaghy说。 “它们有更多的数据,这意味着更好的模型,这意味着更高的点击率,带来更多的钱。它们自称AI公司,但其实是数据公司——是数据竖井。一旦拥有了数据竖井,企业就可以将用户从他们自己的数据中分离出来,从而将他们从数字生活中隔离开来。AI催生了这些数据竖井。”
今天,在互联网时代,大型科技公司的权力集中度无人能及;相比之下,微软在90年代凭借IE浏览器达到统治地位而引发的反垄断担忧就相形见绌了。
虽然我们并不处于洛克菲勒的垄断时代,但数据市场的集中度介于洛克菲勒垄断和OPEC模式之间。 正如McConaghy所说,打破寡头垄断的最佳方式就是“用开放数据的海洋淹没数据竖井”。

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com





