深度分析金融知识图谱创业:需从“数据”竞争跨向“技术”竞争
▲点击上方 雷锋网 关注

文 | AI金融评论
来自雷锋网(leiphone-sz)的报道
雷锋网AI金融评论按:什么是知识图谱?简单的说,知识图谱是信息(实体)本身以及信息(实体)之间的关联,是计算机实现智能的基础。知识图谱之于计算机,就好比知识之于人类,而金融行业的特点决定了其对金融知识图谱的刚性需求。此文为整理业内专业人士观点分享。
深度分析金融知识图谱创业:需从“数据”竞争跨向“技术”竞争
人类天生擅长将信息进行分类、关联,但并不擅长记忆、处理海量碎片化的信息,但计算机可以。所以当前越来越多的AI创业公司开始致力于攻克构建知识图谱的底层技术。
不同于拥有大量C端数据的BAT,该领域的创业公司往往从垂直领域的企业级服务切入。目前在国内,金融、法律、医疗、智能客服、安防等行业都已经有了致力于该领域知识图谱构建的AI创业公司,但金融行业由于其行业特点将成为该领域创业最大的蓝海。
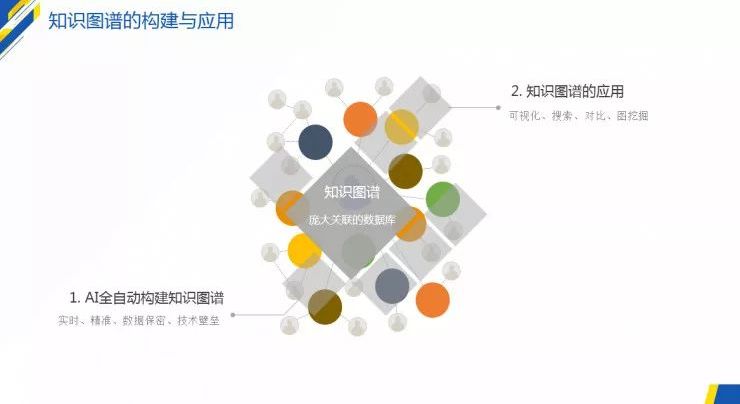
图1:知识图谱的构建与应用
半自动化构建知识图谱的代表 数据供应商面临三大痛点
金融行业的特点决定了其对金融知识图谱的刚性需求。
首先,金融行业拥有海量的包含各行各业的数据信息,而且这些信息又以各种形式(如文字、表格、图形等)存储在大量的文档上,这些都是非标准化、碎片化的信息,需要被整理成标准化的、相关联的金融知识图谱,才便于金融从业者使用。
其次,金融行业的公开文档具有一定的法律效应,故对于数据的精确性、时效性有很高的要求。
目前,整理这些数据的工作主要还是由金融数据供应商来完成的。
而其中的明星级代表就是万得(Wind)。它所采用的是数据爬虫技术,从公开渠道第一时间获得企业工商信息、财务报告等数据,再由大量人工进行整理和分类,以“人力模式”结构化这些信息,再通过万得终端提供给金融从业者使用。万得作为当前最大的金融数据拥有者,通过多年在金融行业中的经营与积累,拥有了丰富的金融知识图谱数据以及大量的金融客户,但其知识图谱的构建却是半自动的过程,仍需要人工操作。
这种模式现在看起来似乎没什么问题,但其中存在三个最大的痛点:
第一,数据供应商不能够“实时、敏捷”地提供金融知识图谱。由于半自动化的知识图谱构建技术,需要人工将金融文档中的信息提取出来,快则数小时,慢则好几天,还容易出错。这就无法满足一些对准确性、及时性、无人工等有高要求的应用场景,比如金融监管、机密文档复核、内部审计等。
第二,数据供应商所拥有的知识图谱仅包含了公开数据,大量机密的、内部的、更为重要的数据不能被外部数据供应商整理成知识图谱。
第三,人工无法整理所有数据。以万得为例,由于受到人工能力限制,其整理的数据仅包含资产负债表、利润表、现金流量表中的主要数据,无法提炼出企业报告中其余上百个表格数据以及隐藏在大量自然文本段落中的信息,而这些信息正是深入分析该企业的业务和财务状况的底层数据。
简而言之,以万得为代表的数据供应商还不具备实时、全面地“构建知识图谱”的能力和技术,出售的仍然是数据本身。
所以,面向企业级服务的AI创业公司都致力于能够全自动化的构建金融知识图谱,解决上述三大痛点。但是目前该市场还是处于需求大大高过供给的情况,这或许是由于全自动构建知识图谱的这项底层技术实际上在学术界都是一个难点。
全自动化构建知识图谱的核心技术是NLP与CV的融合
人们在阅读金融文档的时候,对其中的自然段落、图表中的信息在很短的时间内便能理解其中的意思,但对于计算机来说,这中间还有几个转换步骤。
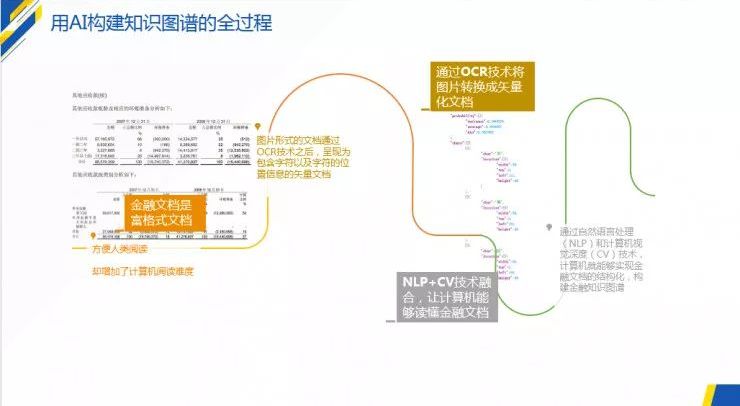
图2:全自动化构建知识图谱的过程
首先,当计算机看到一份金融文档的扫描图片时,看到的仅仅是图片中所有光点所呈现的数字矩阵;然后,通过OCR(Optical Character Recognition,光学字符识别)技术,将庞大的数字矩阵转换成包含字符以及字符的位置信息的矢量文档,比如金融行业最常见的PDF格式的文档就是矢量化的文档。但是,在此阶段,计算机看到的仅仅是一个一个的文字以及该文字的位置,并不能知道哪些字符组成了主语,哪些字符是谓语动词,哪些数字是关键信息,文档的哪些部分是表格。
接下来,需要让计算机将这些零散的单个字符组合成金融知识图谱,这就需要用到富格式文档(Richly Formatted Data)处理技术。在这个阶段,就是计算机将零散的字符提炼成信息的阶段,也是技术上的难点。因为各类披露的金融文档呈现为富格式文本的形式,包含篇章结构、文字段落、数据表格等各类形式,而计算机对于不同形式的文本需要使用不同的处理技术;同时不同渠道获得的金融文档内容还可能出现不一致的地方,这还需要AI模型能够分辨矛盾数据、噪音数据。
所以,想要将这些文档上的字符归纳提炼成为标准化的、相关联的、准确的信息,需要AI领域中的自然语言处理(NLP)技术与计算机视觉深度(CV)的技术的融合。
也就是说,在全自动构成知识图谱的过程中,真正的难点在于计算机如何从含有复杂格式的大量资料中,快速地“理解”、“读懂”人类语言,甚至是对经过复杂演算的数据结果进行“纠错”。攻破这些技术难点的创业公司就将拥有核心的“技术”竞争力,也就是说它们将不再出售数据本身,而是出售“构建数据”这项技术。而各家创业公司的技术硬实力,将会成为其占领该领域的真正壁垒。
全自动构建金融知识图谱将使金融机构提升运营效率、节约合规成本
当全自动构建知识图谱的技术开始真正渗透到金融机构中,金融行业才能真正实现智能化的飞跃,大幅提升行业运营效率。
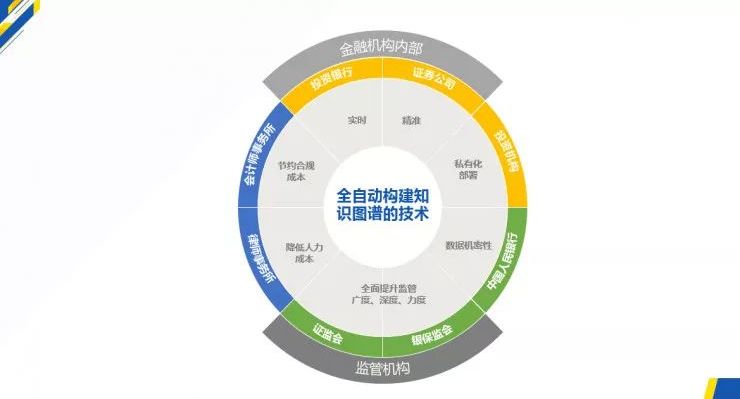
图3:全自动构建知识图谱在金融机构及金融监管场景的应用
一方面,如果全自动构建金融知识图谱的数据的技术私有化部署在公司内部,则内部机密数据的标准化整理、识别、关联、分析将能够被计算机替代。其应用场景可以涵盖从内部繁复的文档整理复核工作到内部合规审核。数据显示,中国证监会仅在2017年就作出行政处罚决定224件,罚没款金额74.79亿元,同比增长74.74%;而因为其他原因出现了细微错误的财务报告也会让企业成为媒体和公众讨伐的对象。如果企业能将合规的审核交给计算机,则企业内部为繁琐文档工作付出的人力成本、为合规处罚付出的经济成本等等,都将被节省下来。
再就是即便对已公开的金融文档,全自动构建知识图谱的技术也将能够使企业大大缩短获得关键信息的时间。如果是运用外部的数据供应商,从企业年报PDF上网公开,到万得(Wind)的财报数据入库,快则需要几个小时,慢则需要数天。但金融行业一直是分秒都很“贵”的地方,如果能通过全自动知识图谱构建技术让财报数据在2分钟之内即可被金融从业者获取及应用,无疑将大大提高金融机构内部的运营效率。
与此同时,外部数据供应商提供的财报数据往往仅包含资产负债表、利润表、现金流量表里的主要数据信息,无法提炼出隐藏在几百页企业报告中深入分析该企业的业务和财务状况的底层数据,但这些信息却可以被计算机自动提取。金融行业从业者将能够获得更加全面、精准的信息。
知识图谱的应用将助力金融监管,监管科技市场前景广阔
另一方面,对金融监管机构而言,基于其特殊性质,对于外部服务商的介入会更加谨慎。而通过私有化部署全自动构建知识图谱技术服务,利用内部闭环程序操作,就可以在尽可能提高数据的保密等级,减少人工直接参与的情况下,及时获得最全面、最精准的标准化大数据。
同时,防范系统性金融风险一直是我国金融监管的重中之重。通过构建跨行业、跨机构的金融知识图谱,获得标准化的、准确无误的、及时透明的以及数量巨大的基础数据或信息,才能让人工智能在海量的数据和信息中主动识别和预测风险,对分散的数据进行综合分析以得出行为模式,这将是帮助监管机构防范系统性金融风险最为有效的金融科技。
随着中国银保监会的正式挂牌,中国金融监管进入“一委一行两会”的格局。统一化监管、整体化监管、穿透化监管将成为未来金融监管的主基调,大量跨行业、跨机构的数据将被打通,构建金融知识图谱的技术将成为市场刚需,成为监管科技的重点应用之一。
目前,全球的监管科技市场正处于一个上升阶段,根据市场调研公司Let's talkpayment预计,到2020年,全球范围内监管科技的市场规模将超过1000亿美元。中国也将在这一领域迎来广阔的市场。
基于此,冲破拥有金融大数据的数据服务商所构建的商业壁垒,在技术层面已经实现,金融知识图谱的市场竞争也正在从“数据”竞争跨向“技术”竞争的新时代,技术本身才是创业公司的壁垒。拥有核心技术,金融数据本身并不是不可替代。
雷锋网诚招编辑、运营、兼职、外翻等岗位
详情点击招聘启事

关注雷锋网(leiphone-sz)回复 2 加读者群交个朋友



