集成学习20问答案及获奖名单公布!你都答对了吗?


作为“集成学习月”的收官,数据派研究部于上个星期举行了“集成学习20问”答题活动。本次一共有48人参与问卷,平均答题时间34分5秒。
结果总览
下图是得分分布图,以帮助你评估自己的能力:
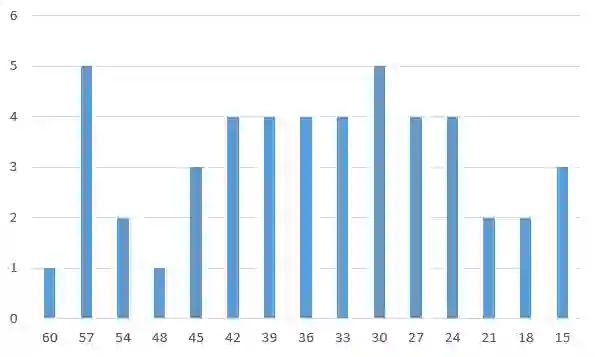
48个人参加了该技能测试,测试一共20题,每题3分,最高得分是60分。下面是关于本次活动得分分布的一些统计:
总体分布
平均得分:35.69
得分中位数:30
本次答题活动题目内容包括集成模型的基础知识及其实际应用,能有效检验你对集成学习这一热门机器学习方法的熟悉程度。
错过答题时间的读者注意啦!接下来小编为你揭晓试题及详细答案,快来看看你能得多少分,估计一下自己集成学习上在数据派小伙伴中的排名吧。
问题&答案
1. 下列哪个算法不是集成建模的例子?
A. 额外树回归
B. 随机森林
C. 梯度提升
D. 单一决策树
答案:(D)
D是正确选项。对于单一决策树,只建立了一个单一的树且不需要集成。
2. 关于集成模型的优点,下面哪个选项是正确的?
1.具有更优良的性能
2.属于广义模型
3.具有更好的可解释性
A. 1和3
B. 2和3
C. 1和2
D. 1,2和3
答案:(C)
1和2是集成模型优点。选项3不正确,因为当我们集成多个模型时,我们丢失了模型的可解释性。
3. 下面哪个选项对选择集成的基础学习器是正确的?
1.不同的学习器可以来自具有不同超参数的相同算法
2.不同的学习器可以来自不同的算法
3.不同的学习器可以来自不同的训练空间
A.1
B.2
C.1和2
D.1,2和3
答案:(D)
我们可以根据以上任一选项创建一个集成。所以选项D是正确的。
4. 判断对错:集成学习只能应用于监督学习方法。
A.正确
B.错误
答案:(B)
一般来说,我们将集成技术应用于监督学习算法。但我们也可以将集成应用于无监督学习算法。参考此链接【https://en.wikipedia.org/wiki/Consensus_clustering】。
5. 关于集成模型中使用的弱学习器,应用下列哪一项是正确的?
1.它们具有较小方差且通常不会过度拟合
2.它们具有较大偏差,不能解决高难度学习问题
3.它们具有较大方差且通常不会过度拟合
A.1和2
B.1和3
C.2和3
D.都不是
答案:(A)
弱学习器对问题的特定部分有把握。所以通常不会过度拟合,这意味着弱学习器有小方差和大偏差。
6. 一般地,如果独立基础模型_________,集成方法效果更好?
注意:假设每个独立基础模型精度大于50%。
A.预测结果之间的相关性低
B.预测结果之间的相关性高
C.相关性对集成输出结果没有影响
D.以上都不是
答案:(A)
集成模型成员之间的相关性较低会增加模型的纠错能力。因此,在创建集成时,最好使用低相关性的模型。
7. 已知通过测试数据集‘n’个不同模型得到(M1,M2, …. Mn)对应的‘n’个预测值。下列哪种方法可以将这些模型之间的预测组合起来?
注意:我们正在研究的是回归问题。
1.中位数
2.乘积
3.平均数
4.加权求和
5.最大值和最小值
6.广义平均值
A.1,3和4
B.1,3和6
C.1,3,4和6
D.以上全部
答案:(D)
以上所有选项都是集成不同模型的有效方法(在使用回归模型的情况下)。
8. 如何将权重分配给集成中的不同模型的输出?
1.使用算法返回最优权重
2.使用交叉验证选择权重
3.给予高精度模型高权重
A.1和2
B.1和3
C.2和3
D.以上全部
答案:(D)
当选择一个集成中单个模型的权重时以上所有选项都是正确的。
9. 关于平均集成,下列哪项是正确的?
A.它只能用于分类问题
B.它只能用于回归问题
C.它既能用于分类问题也能用于回归问题
D.以上都不对
答案:(C)
平均集成既可用于分类也可用于回归。在分类中,你可以取预测概率的平均值;而在回归中,你可以直接取不同模型的预测值的平均值
10.
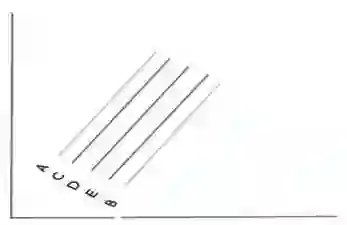
上图中,直线A和B是分别两个模型(M1,M2)的预测值。现在你要用一个集合,该集合是用加权平均来聚合这两个模型结果的。如果M1,M2模型权重分别为0.7和0.3,下列哪个结果最可能是该集合的输出结果?
A.A
B.B
C.C
D.D
E.E
答案:(C)
11. 下列关于加权多数表决的论述哪一个是正确的?
1.我们赋予性能优良的模型更多权重
2.如果低级模型的集体加权票数高于最佳模型,则较低级的模型可以推翻最佳模型
3.表决是加权表决的特例
A.1和3
B.2和3
C.1和2
D.1,2和3
E.以上都不对
答案:(D)
以上所有论述都是正确的。
12. 下列关于stacking算法说法正确的是:
1.一个机器学习模型是在多个机器学习模型的预测值的基础上训练的。
2.logistic回归在第二阶段中一定优于其它分类方法。
3.第一阶模型是使用测试数据集的全部/部分特征空间进行训练的
A.1和2
B.2和3
C.1和3
D.以上都是
答案:(C)
1.在stacking算法中,一个机器学习模型是在多个基础模型的预测值基础之上训练的。
2.不一定——我们可以使用不同的算法来堆叠结果。
3.第一阶模型是利用所有原始特征进行训练的。
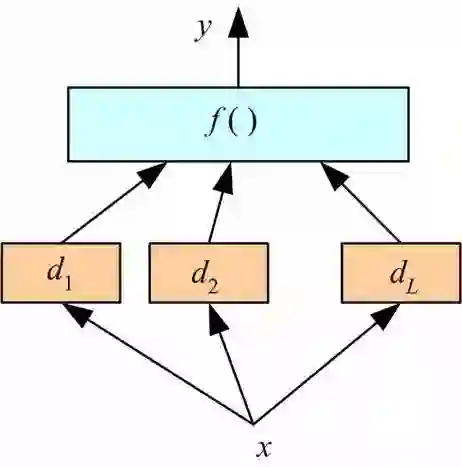
13. 下列示意图表达了stacking算法的是:
A.
B.
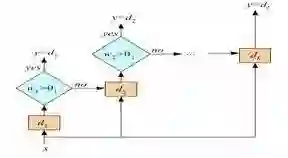
C.以上都不是
答案:(A)
A选项正确是由于图示中使用f函数(也可以说是一个模型)将基础模型的结果d1,d2...dL进行了堆叠。
14. 下列关于bagging算法说法正确的是:
1.bagging算法可以是并行的
2.实行bagging算法的意义是减小偏差而不是方差
3.bagging算法更容易避免过度拟合
A. 1和2
B. 2和3
C. 1和3
D.以上都是
答案:(C)
1选项在bagging算法中,个体学习器互不依赖,因此是可以并行的。
2-3选项bagging算法适合于方差大而偏差小的模型,或者说是较为复杂的模型。
15. 以下是两个集成模型:
E1(M1, M2, M3)
E2(M4, M5, M6)
Mx是个体基础模型。
若已知E1,E2,应该选择:
E1: 个体模型精确度高,但每个模型都是同一类别,即不够多样化。
E2: 个体模型精确度高,但每个模型都是不同类别,即本来就很多样化。
A.E1
B.E2
C.E1或E2
D.以上都不是
答案:(B)
选择E2模型,因为包含多样的模型。
16. 假设你有2000个不同的模型和它们的预测值,想用最好的x个模型的预测值进行集成。以下选择x个模型进行集成的方法有:
A.前进式逐步选择
B.后退式删除筛选
C.两者都使用
D.以上都不是
答案:(C)
可以两种算法都应用。在前进式逐步选择中,先从空预测集开始,在可以提高模型精确度的前提下,一次一次逐步加入模型预测值。在后退式删除筛选中,从全部特征集开始,在可以提高模型精确度的前提下,一次一次逐步删除模型预测值。
17. 假设,你想用前进式逐步选择方法选择最好的模型进行集成。下列步骤顺序正确的是:注意:你有超过1000个模型预测值
1. 在集成过程中逐个加入模型预测值(也就是说取平均值),提高在验证集的指标。
2. 从空集开始
3. 返回在验证数据集上有着最优表现的嵌套集合的集成
A.1-2-3
B.1-3-2
C.2-1-3
D.以上都不是
答案:(C)
C选项的步骤正确。
18. 在神经网络中,Dropout可以被认为是集成的技术之一,子网络通过“丢弃”神经元之间某种联系来进行共同训练。
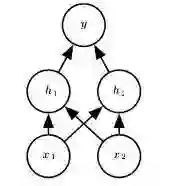
假设,我们在神经网络中有以下一个隐藏层。
可被用于分类的子网络有几种组合的可能?
A.1
B.9
C.12
D.16
E.以上都不是
答案:(B)
共有16种组合的可能。其中9种可行,6种不可行(分别是表格中的6,7,12,13,14,15,16)。
19. 为了找到更好的集成模型,可以对以下基于bagging的模型中哪些参数进行微调:
1.样本最大值
2.样本特征
3.对样本进行多次重复抽样(Boostrapping)
4.对特征进行多次重复抽样(Boostrapping)
A.1和3
B.2和4
C.1,2和3
D.1,3和4
E.以上都是
答案:(E)
给出的调整方法都可以应用于集成更好的模型。
20. 假如有25个基础分类器。每个分类器的错误率为e=0.35。
若使用取平均值法作为集成方法。使用以上25个分类器集成得到错误预测的几率是:
注意:所有的分类器之间相互独立。
A.0.05
B. 0.06
C. 0.07
D. 0.09
答案:(B)
参考链接【https://stats.stackexchange.com/questions/21502/how-are-classifications-merged-in-an-ensemble-classifier】。
本期活动中奖名单
188****8339
134****2604
130****5445
188****1860
186****1992
恭喜第一名的读者获得精美读本《深度学习》一本,2~4名并列,成绩很接近第一名,故数据派THU决定扩大福利范围,另送4份别的福利给他们。小编已根据大家答题时留的联系方式对接过了,将在稍后为各位派发奖品。

结束语
希望你在“集成学习月”中已经深入了解了集成学习这一高效机器学习方法,往后数据派将推出更多主题知识月活动,更多精彩敬请留意公众号“数据派THU”。
如果您对以上问题有任何疑问,请通过留言告诉我们。另外,如果您有什么意见或者建议,也可以在留言中作出您的反馈。

Yan,生物统计硕士在读。坐标美国。数据派研究部算法模型组成员。专业研究方向是基因医疗方面的数据挖掘。喜欢旅行,钟爱滑雪等各种运动。

李江莹,数据派研究部志愿者,硕士研究生,现就读于北京科技大学,研究方向是成像算法。喜欢读书,喜欢民谣,闲暇时爱打乒乓球和羽毛球。
【集成学习】系列往期回顾:
以下为研究部出品的往期干货大合集:
后台回复关键词“福利”,下载PDF版文章合集。
数据派研究部介绍
数据派研究部成立于2017年初,志于打造一流的结构化知识分享平台、活跃的数据科学爱好者社群,致力于传播数据思维、提升数据能力、探索数据价值、实现产学研结合!
研究部的逻辑在于知识结构化、实践出真知:梳理打造结构化基础知识网络;原创手把手教以及实践经验等文章;形成专业兴趣社群,交流学习、组队实践、追踪前沿。
兴趣组是研究部的核心,各组既遵循研究部整体的知识分享和实践项目规划,又会各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至datapi@tsingdata.com

公众号底部菜单有惊喜哦!
企业,个人加入组织请查看“联盟”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”



点击“阅读原文”加入组织~


