陈天奇创业公司首个SaaS产品:快速构建部署ML应用,跨平台优化、基准和封装一条龙
作者:Jason Knight
机器之心编译
机器之心编辑部
我们都知道,将机器学习模型部署到设备时需要耗费大量的时间和算力,有时会力不从心。去年,知名人工智能青年学者、华盛顿大学博士陈天奇参与创建了 ML 创业公司 OctoML。该公司致力于打造一个可扩展、开放、中立的端到端栈,用于深度学习模型的优化和部署。这不,他们推出了首个 SaaS 产品 Octomizer,其能够帮助开发者或数据科学家更方便、更省事省力地将 ML 模型部署到设备上。
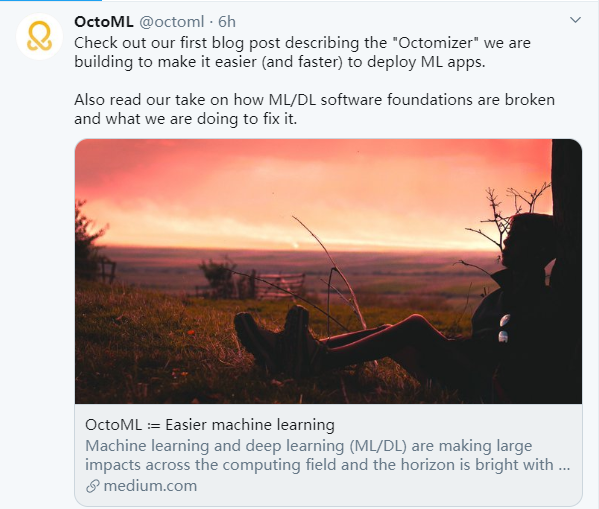
减少从模型训练到模型部署期间的周转时间,进而提升数据科学团队工作效率;
降低 ML 云操作成本;
将更多模型部署到边缘、移动端和 AIoT 设备上,实现云操作零成本。
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年3月15日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月15日