深度度量学习-论文简评
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
缘起:
有人说起深度度量学习,就会觉得这里面水文多,或者觉得鱼龙混杂,参见曾经上了知乎热榜的一个问题:
如何看待研究人员声称近13年来在 deep metric learning 领域的进展实际并不存在?
作为在这个坑里摸爬了一段时间,也发了两三篇顶会的从业人员.我的看法是,有的文章确实是纯粹的水文,有些文章还是挤挤的话,还是有些营养的.与其去嘲笑别人,不如从别人的亮点中获得启发.这里我以随笔的形式,不定时的分享我对这个领域的一些文章的思考,破开文章的层层包装,直达本质,让读者不被它们的层层套路所误导,迷失方向,甚至有了一些偏见,从而更加快速地对DML领域有个我认为的清晰正确的见解.
如果大家遇到一些有意思的文章,也可以在评论里告诉我,我可以去看看,并写下我的感想.
总览
我认为,metric learning的方法有两大分支:pair-based 和 proxy-based. pair-based是基于真实的样本对,比如contrastive loss, triplet loss, N-pair loss和MS loss等,而proxy-based是利用proxy去表示类别的特征,或者样本特征,比如说softmax, Proxy-NCA等.proxy是一个非常宽泛的概念,在softmax中,它是fc层的列;在memory的方法中,它是存储在memory中的特征.
pair-based的方法的好处在于简单准确,准确的意思是你的feature是从当前模型前向出来的,可以精确的表示当前的模型;缺点在于计算量大,信息局限,pair-based只可以利用当前mini-batch的信息,不能看到模型在整体的数据的表现,一直在做局部的优化.
那么,proxy的好处在于可以有global的信息,但是,缺点是什么?proxy是基于历史信息,或者是网络一步步学过来的,未必能够准确的表达当前模型.
论文点评
1.MS Loss(CVPR-2019)
https://arxiv.org/pdf/1904.06627.pdf
首先要说的是自己的文章,MS Loss, 虽然文章的名字是一个loss,但是我认为我的这个文章最值得的看点,可以成为一种思考所有pair based loss方法的方法是GPW:
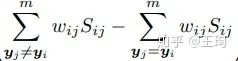
这个GPW (general pair weighting)的意思就是,无论你的loss的形式有多么花哨,无论你故事讲得有多么的骚,一切不过是一个对于pairwise similarity的加权求和罢了,而这个权重恰恰是一阶导数,详细的请看论文.在论文中,我们用GPW之刀解剖了目前市面上常见的几种loss functions:

表格1.几种loss对于负样本对的权重
建议读文章,仔细体会这个想法,最好能够用两种形式写出写出binomial loss,并验证结果的一致性,从而更加深刻的理解这个思路,以后遇到pair-based loss的论文就可以一眼看穿本质,不会被天花乱坠的故事迷了方向.
另外,MS里面讲的SNP multi-similarity的故事,理论和实验其实都不算扎实全面,并不能完全验证,只是一个实验结果还不错的一个反向思考结果,或者说是一个可以近乎自圆其说的story.
2.lifted structure loss (CVPR-2016)
SOP数据从这里来,这个文章是比较早的deep metric learning论文.
文章的想法就一句话总结:过去 contrastive loss的训练是这样的:先配好样本对在送进去网络,这种太浪费了,一个mini-batch大小为n,结果只有n/2对样本.他的做法是:任意两两配对,样本的个数直接平方( n*(n-1)/2 ).当然,这个现在大家都这么做啦.
这个文章的实验效果是很低的:
原因有二:
1.当时的调参技术还比较拙劣.
2.后来我也复现了这个loss,按照论文里的设置,效果是真的不行.故事讲的不错,loss设计的是真的有点菜(没有对特征normalize并且没有调temperature).
3.Sampling Matters in embedding learning (ICCV-2017)
https://arxiv.org/abs/1706.07567
这个文章的作者也算是个小有名气的大佬了,现在应该是跟着kaiming的.但是我认为这篇论文,其实题文是不太符合的.这个文章我至少读了五六遍,并且看了作者公布的代码,并与同行进行了一些讨论,自己复现也做了一些实验.我的感想这个文章应该改个名字:Margin Matters.
文章前面讲了一波很好的高维空间中向量分布的故事,统计,数学显得专业,但是,distance weighted sampling这个点,真的是理论上有点扯,效果上也很崩盘.那文章最后咋效果很好呢,原因在于两点:
1.当时大家的baseline都比较低,看了作者代码,真的是调参比较努力的,带了一些tricks,另外别人用googlenet,他用了resnet. 不是说resnet一定好,但是确实网络不同,还是有很大不同的.
2.文章提出了margin(就是对相似度卡阈值),且这里的margin 是动态的学习的.其实这个是提点的关键.所以,我说吗,可以改名字叫做Margin Matters哈.
说回来,为什么觉得文章方法的动机不对,distance weighted sampling说pair 的距离分布是不均匀的,所以要变成均匀的,所以要丢弃比较多的那部分.因为多所以就要丢弃样本对,这个逻辑不是很成立,实验也说明了这个点.我认为更合理的说法还是easy, hard那一套,有些样本对简单,对当前模型训练意义小;有些样本对难,可以对模型的训练有很大的促进作用.这种完全没必要一定 非用欠采样的方法变成balance的分布,扔掉那么多的多样本对,会丢失很多信息的. 通过加权的方式完全可以解决得轻松舒服.
4. BIER (ICCV-2017 Oral)
http://openaccess.thecvf.com/content_ICCV_2017/papers/Opitz_BIER_-_Boosting_ICCV_2017_paper.pdf
思路很直接,为了解决高维空间特征的冗余,所以,把高维空间拆开,通过gradient boosting 还有对抗训练使得每个子空间的学习出来的特征尽量不同,那么从集成学习的思路去想,这样子把他们拼到一起后的空间,自然效果提升大.
metric learning 当时在顶会中的oral论文还是挺少的.这个文章真的做得很好,很扎实.想法也是很好的.我个人很喜欢.建议精读,与其把时间浪费在没有营养的水文,不如从这个文章多多体会.后来作者扩充了这个文章,被PAMI接收.
另外,这里对loss梯度的分析,还有使用的binomial deviance loss是对我MS Loss论文有很大的启发.我的MS loss 可以认为就是把binomial 和lifted structure loss拼起来了.
5. Proxy-NCA (ICCV-2017)
狗大户的文章,在当时可以认为效果爆表,不过爆表有一大部分的原因在于从他开始把googlenet换到了inceptionBN, 而且也不怎么调baseline. 就用了过去的很低的,另外,狗大户真的有钱爱调参,最后选出来的参数还有优化器怎么看都是暴力调的.
方法的话,其实是softmax或者NCA的一个换装.不过,文章还是很有亮点的:这里提出的proxy的概念真的是棒,我当时理解了很久.
6.Divide and Conquer (CVPR-2019)
https://arxiv.org/abs/1906.05990
同BIER,去拆分了空间,不同的是这儿为了使得每个子空间学的不相似,采用的方法是:类似于集成学习中的数据扰动策略(参见西瓜书 P188)的方法,对每个子空间采用不同的数据去学习,从而使得每个分支学得尽量不同.
7.softtriple(ICCV-2019)
https://arxiv.org/abs/1909.05235
出自达摩院.讲的故事是多中心/类别,其实大家如果看过CUB数据,就会发现类内区别确实大,所以文章把softmax拓展为多中心的形式,方法上未必是多么创新:这个和proxy-nca的多中心时其实是很近似的,或者说proxy就是把softmax 拓展到了单中心,多中心,甚至多个类别共享中心的广义形式.
文章的文笔我认为很不错,introduction写的很好,对传统的metric learnning做了简略的回顾,并且对deep metric learning这几年的发展做了个很好的总结.尤其是关于batch size那一小部分,写得我感觉很恰当.是很好的入门导入.
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




