归一化激活层的进化:谷歌Quoc Le等人利用AutoML 技术发现新型ML模块
选自arXiv
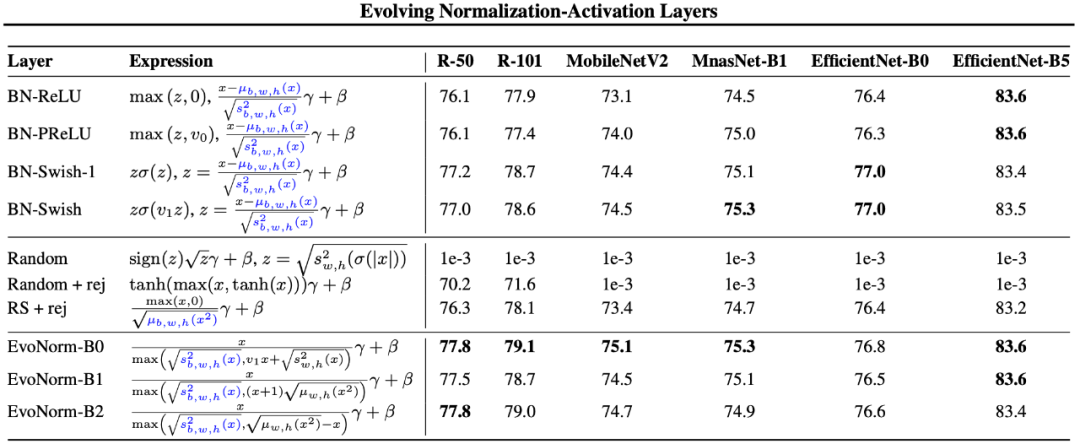
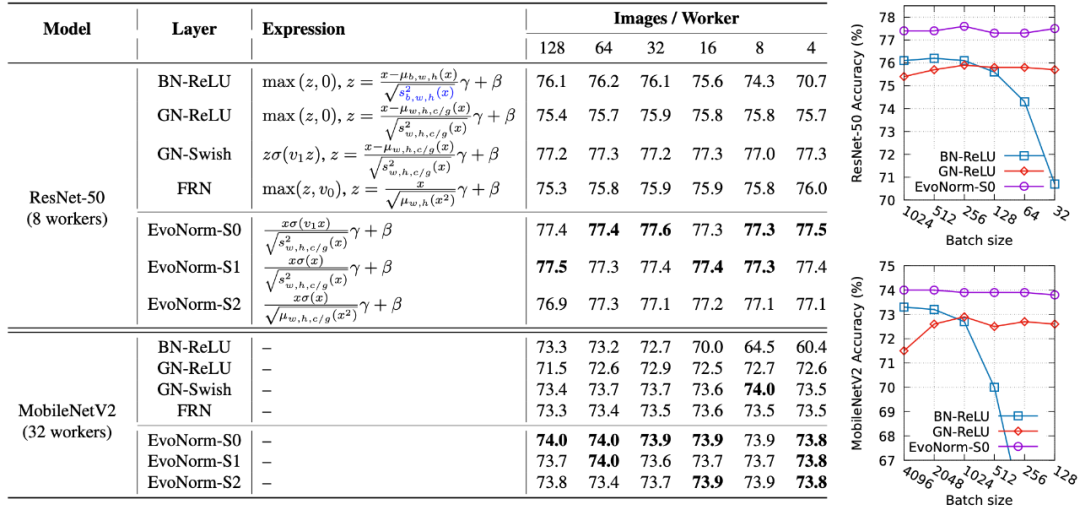
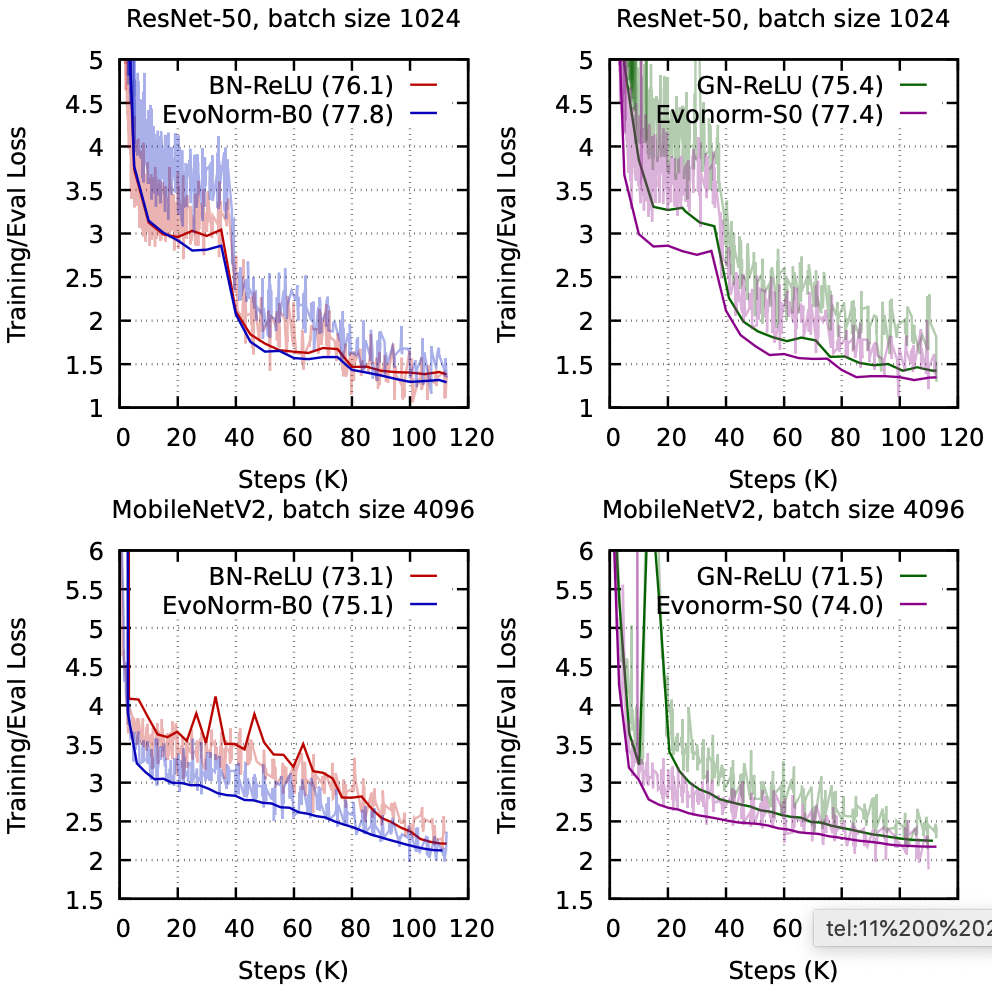
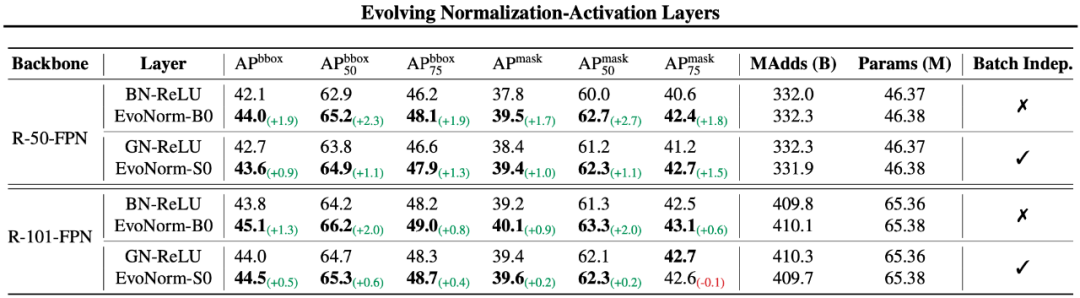
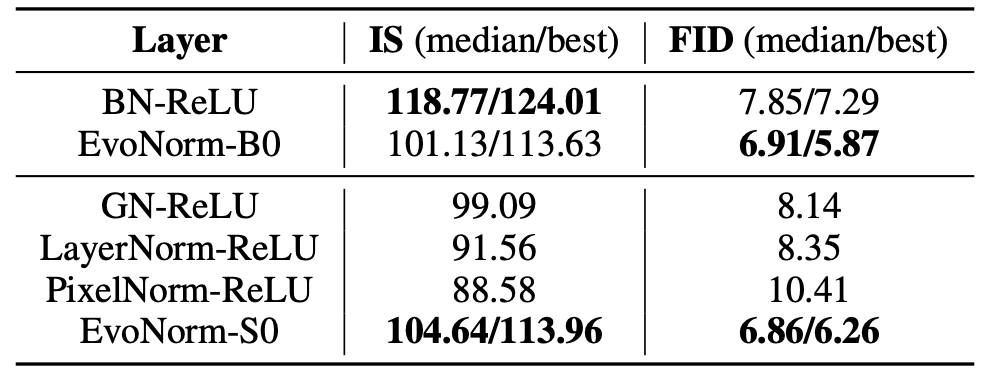
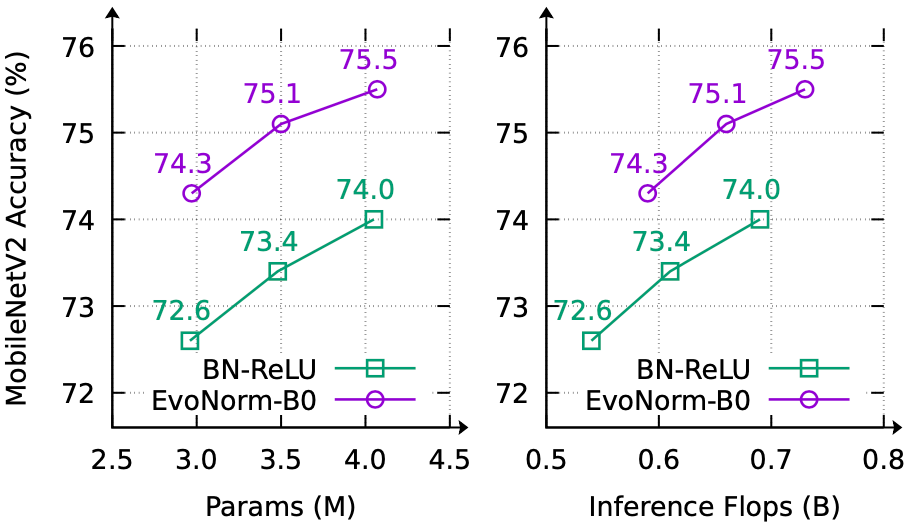
最近,谷歌大脑团队和 DeepMind 合作发布了一篇论文,利用 AutoML 技术实现了归一化激活层的进化,找出了 BatchNorm-ReLU 的替代方案 EvoNorms,在 ImageNet 上获得 77.8% 的准确率,超越 BN-ReLU(76.1%)。
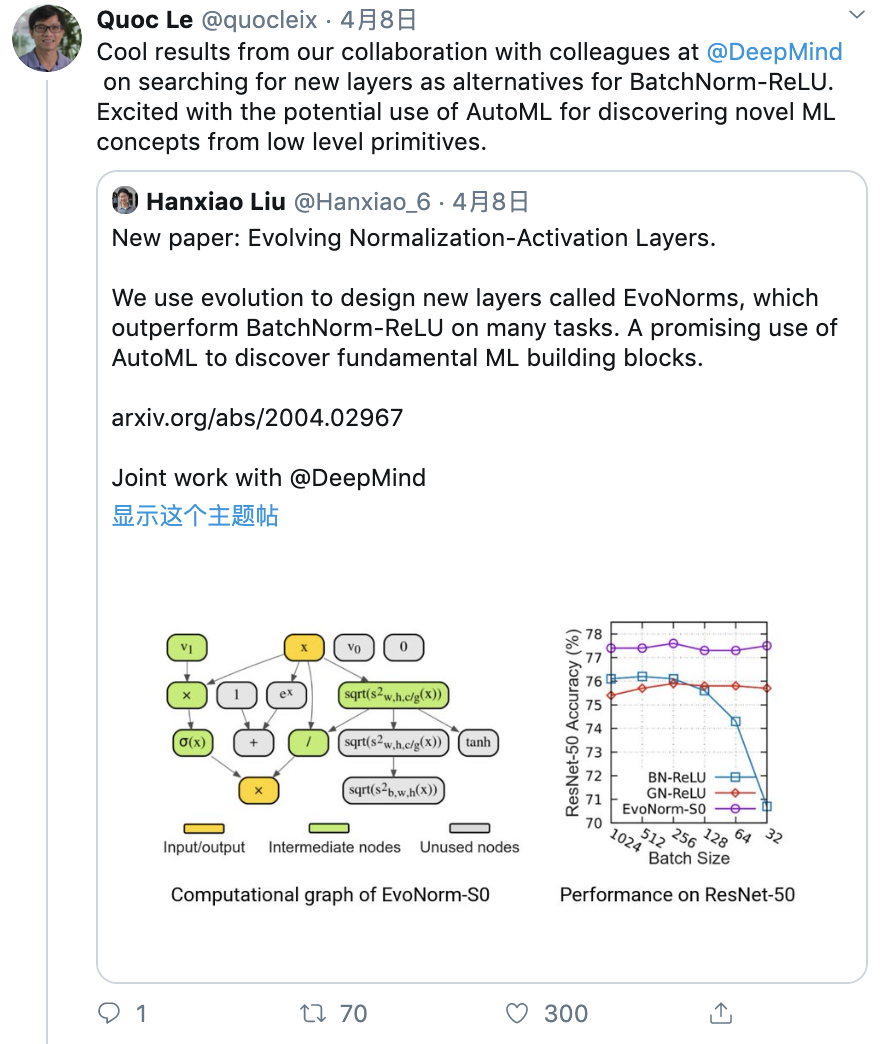
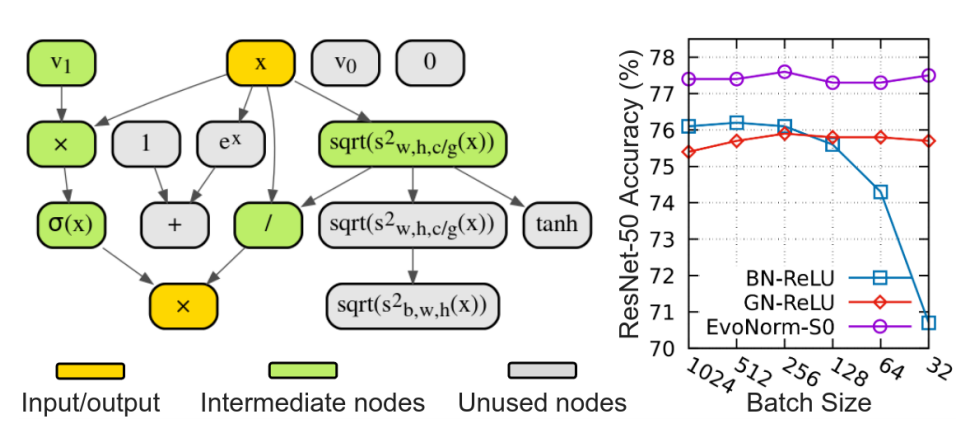
论文地址:https://arxiv.org/abs/2004.02967
视频:https://youtu.be/RFn5eH5ZCVo

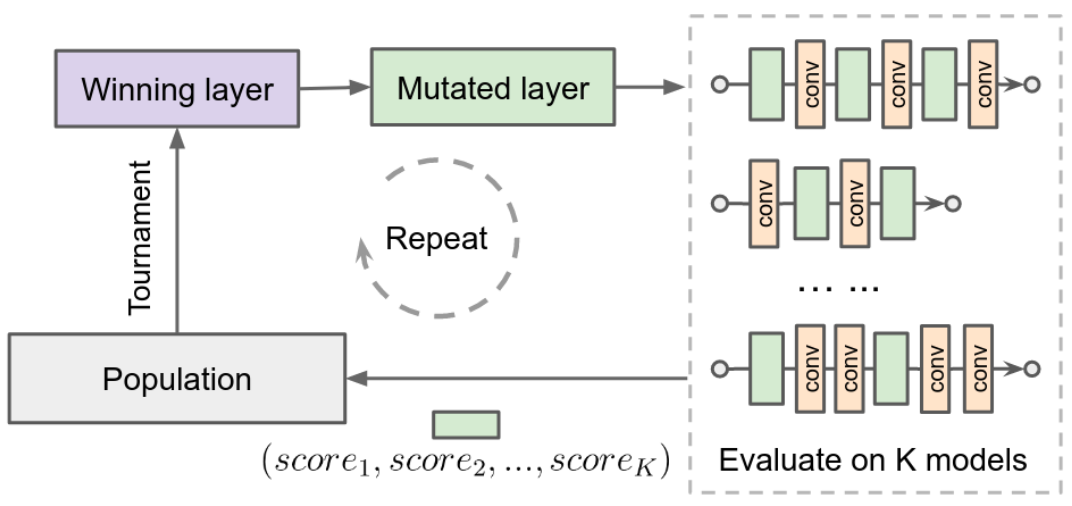
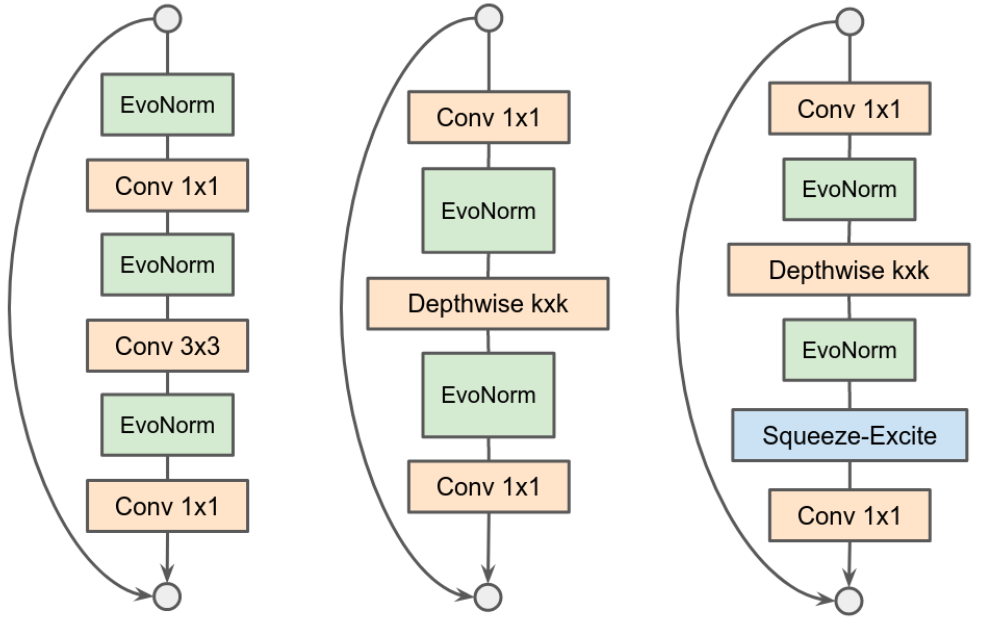
将每个层与多个架构进行配对,并在轻量级代理任务中训练模型,从而评估每个层的性能。
通过进化算法来优化多目标边界,使用高效的否决机制(rejection mechanism)进行增强,从而过滤掉不需要的层。
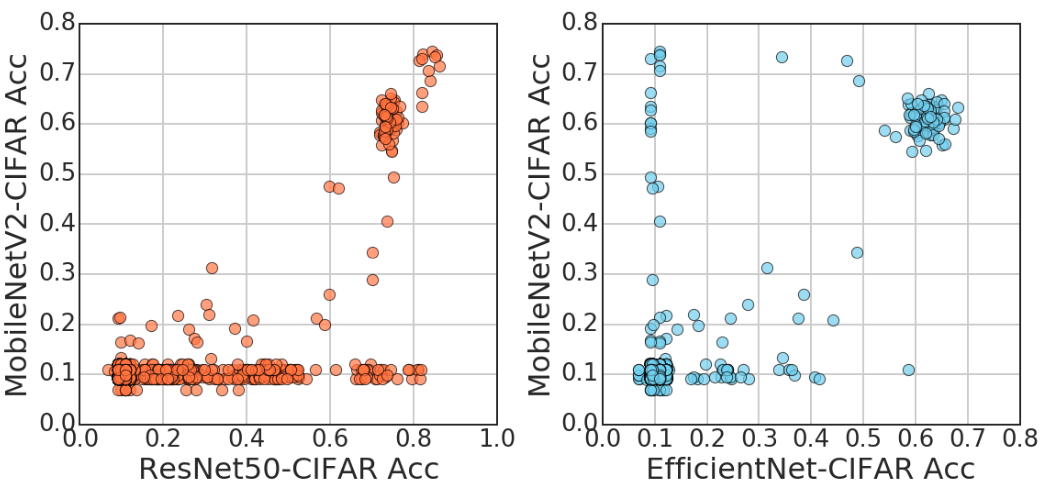
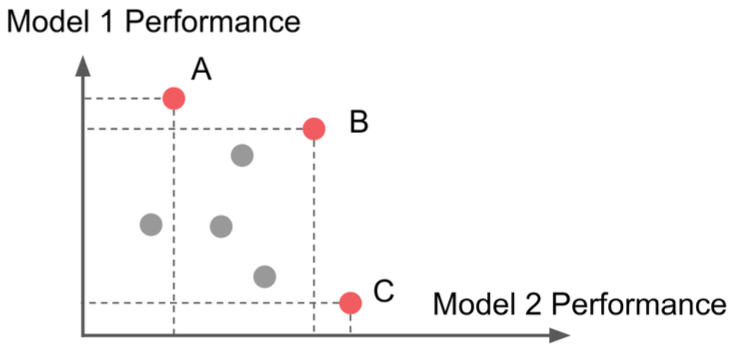
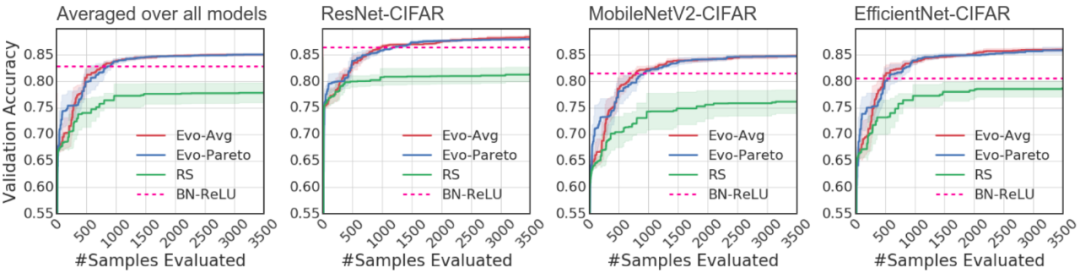
平均值:具备最高平均准确率的层获胜(如图 6 中的 B);
帕累托:位于帕累托边界上的随机层获胜(如图 6 中的 A、B、C 均获胜)。
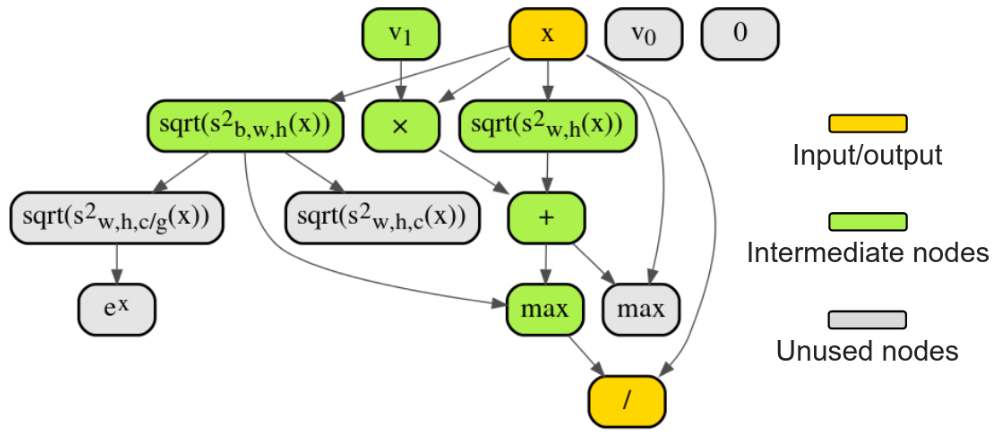
随机均匀选择中间节点;
随机均匀地使用表 1 中的新操作替换当前操作;
随机均匀地选择该节点的新的继任者。


登录查看更多
相关内容
Arxiv
15+阅读 · 2020年3月31日
Arxiv
14+阅读 · 2019年1月17日

相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日
Arxiv
14+阅读 · 2019年1月17日