5分钟图解Hbase列式存储
作者 | 李新杰
来源 | 微信公众号“编程新说”
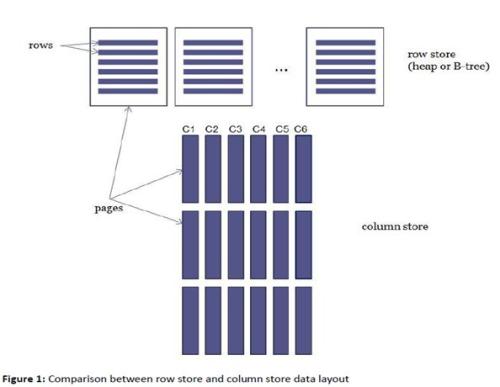
行式存储
传统的数据库是关系型的,且是按行来存储的。如下图:
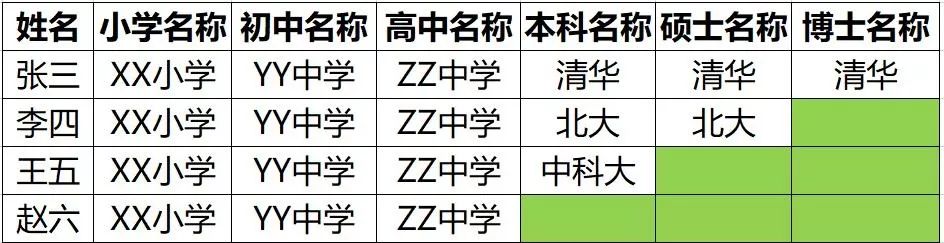
其中只有张三把一行数据填满了,李四王五赵六的行都没有填满。
因为这里的行结构是固定的,每一行都一样,即使你不用,也必须空到那里,而不能没有。
来一张形象的图:


不管你坐或不坐,座位都在那里,不离不弃。
为了与传统的区别,新型数据库叫做非关系型数据库,是按列来存储的。如下图:
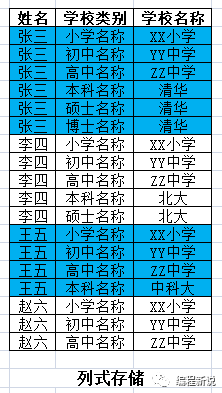
初次看列式存储稍微有点懵,下面给出行存与列存的转换: 原来张三的一列(单元格)数据对应现在张三的一行数据。
原来张三的六列数据变成了现在的六行。
原来的六列数据是在一行,所以共用一个主键(即张三)。现在变成了六行,每行都需要一个主键(不然不知道这行数据是谁的),
所以原来的主键(即张三)重复了六次。如下图:
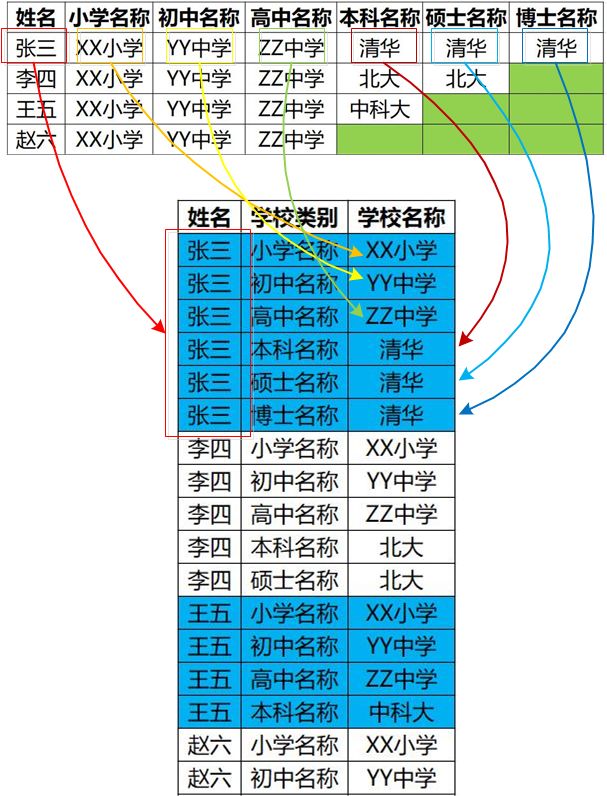
由于原来的列变为了现在的行,如果有需要就加一行,没需要就不加,不会造成空间浪费。
来一张形象的图:

摆渡车内部就是一个大平板,你要站便站,我给你空间,你不站便不站,还给我空间。
1. 行式存储倾向于结构固定,列式存储倾向于结构弱化。 (行式存储相当于套餐,即使一个人来了也给你上八菜一汤,造成浪费;列式存储相等于自助餐,按需自取,人少了也不浪费)
2.行式存储一行数据只需一份主键,列式存储一行数据需要多份主键。
3. 行式存储存的都是业务数据,列式存储除了业务数据外,还要存储列名。
4. 行式存储更像一个Java Bean,所有字段都提前定义好,且不能改变;列式存储更像一个Map,不提前定义,随意往里添加key/value。
有了前面的介绍,我们可以进入HBase了。
HBase的目标是管理超级大表-数十亿行 * 数百万列。 Hbase是一个开源的、分布式的、带版本的、非关系型数据库,模仿谷歌的BigTable。
BigTable使用Google File System作为分布式数据存储,同理Hbase使用HDFS。
Hbase虽然弱化了结构,但并不等于放任不管。传统关系型数据库在插入数据前表结构(即所有列和列的数据类型)已经是严格确定的。 Hbase的表在放入数据前也有需要确定下来的东西,那就是Column Family(常译为列族/列簇)。
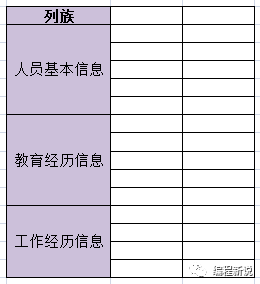
单词Family就是家庭的意思,所以列族就是列的家庭。那么列自然就是家庭成员了,通常家庭成员都有多个,所以一个列族包含多个列。
一个家庭的成员之间具有血缘关系,所以一个列族的多个列之间通常也具有某种关系,比如相似或同种类别。所以列族可以看作是某种分类(归类)。
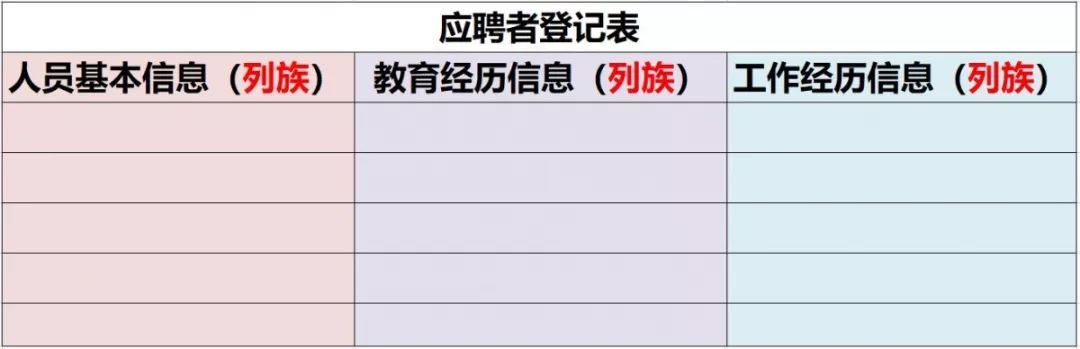
一个非常常见的例子,去面试的时候,一般前台MM都会让填一张表,通常信息很多,每个公司又不尽相同。但大致可以分三类:人员基本信息,教育经历信息,工作经历信息,这三个类别其实就相当于三个列族。如下图:
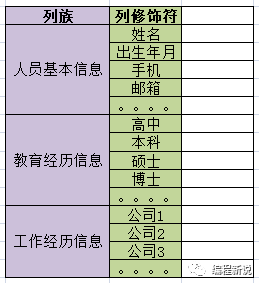
每个类别里都会有具体的信息,比如人员基本信息里有姓名、电话、出生年月等,它们就相当于一个个标识符(变量名),在Hbase中叫做Column Qualifier(列修饰符)。列修饰符位于列族里面用来标识一条条数据。如下图:
在Hbase中一个列族(Column Family)和一个列修饰符(Column Qualifier)组合起来才叫一个列(Column),使用冒号(:)分割,列族:列修饰符,如下图:

在传统数据库中每一行的唯一标识符叫做主键,在Hbase中叫做row key(行键)。如下图:
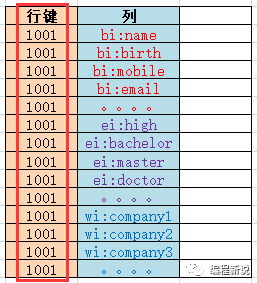
数据在进入Hbase时都会被打上一个时间戳,这个时间戳可以作为版本号来使用。
在t1时间我存入一个人的基本信息,之后发现姓名错了,在t2时间又更新了姓名,此时并不会去更新原来的那条数据,而是又插入了一条新数据且打上新的时间戳。
此时去查询获取的是新数据,仿佛是更新了,但其实只是默认返回了最新版本的数据而已。如下图:
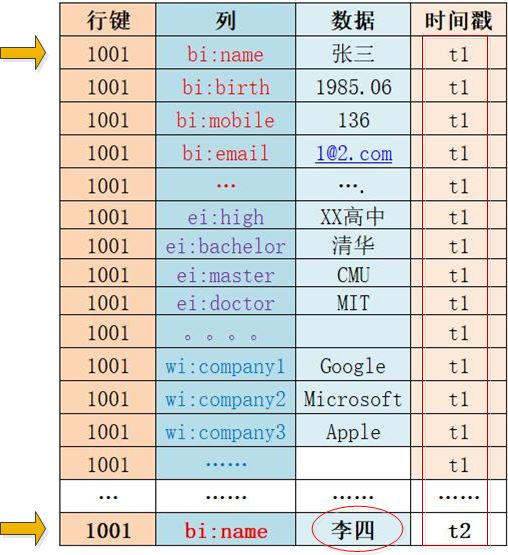
一个行键、列族、列修饰符、数据和时间戳组合起来叫做一个单元格(Cell)。
这里的行键、列族、列修饰符和时间戳其实可以看作是定位属性(类似坐标),最终确定了一个数据。
下图中的一行相等于Hbase中的一个单元格:
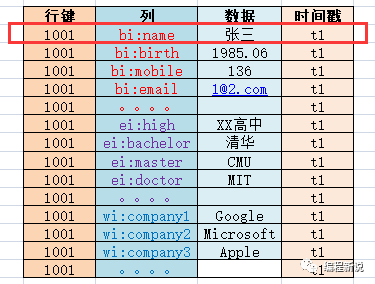
一个行键、一到多列(包括数据)组合起来叫做一行(Row)。下图中所有1001的数据合起来相当于Hbase中的一行,1002的相当于另一行:
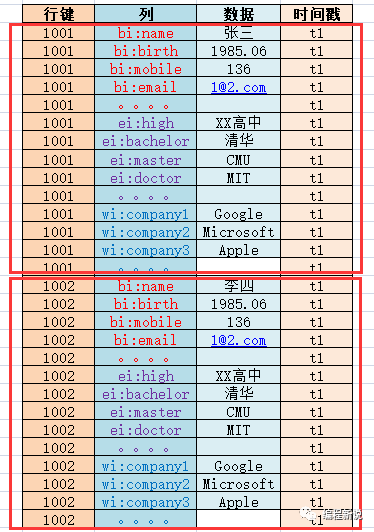
在Hbase中,只要确定了列族(具体的列不用管),表(Table)就确定了。如下图:
官方文档中提醒:把传统数据库中的表/行/列的概念用在Hbase中不是一个有帮助的类比。
相反可以把Hbase的表想象成一个多(两)维Map(Map套Map)。列族是第一维,列修饰符是第二维。
一点思考:任何细微的差别在大数量时都会被无限放大,那么列族和列修饰符的名字起的短一些是不是能够节省可观的空间呢?
ps : 从严格的列式存储的定义来看,Hbase并不属于列式存储,有人称它为面向列的存储,但是还是有很多人习惯称之为“列式存储”。