史上最全!27种神经网络简明图解:模型那么多,我该怎么选?

大数据文摘作品
编译:田奥leo、桑桑、璐、Aileen
27种?!神经网络竟有那么多种?这篇文章将逐一介绍下面这张图片中的27种神经网络类型,并尝试解释如何使用它们。准备好了吗?让我们开始吧!
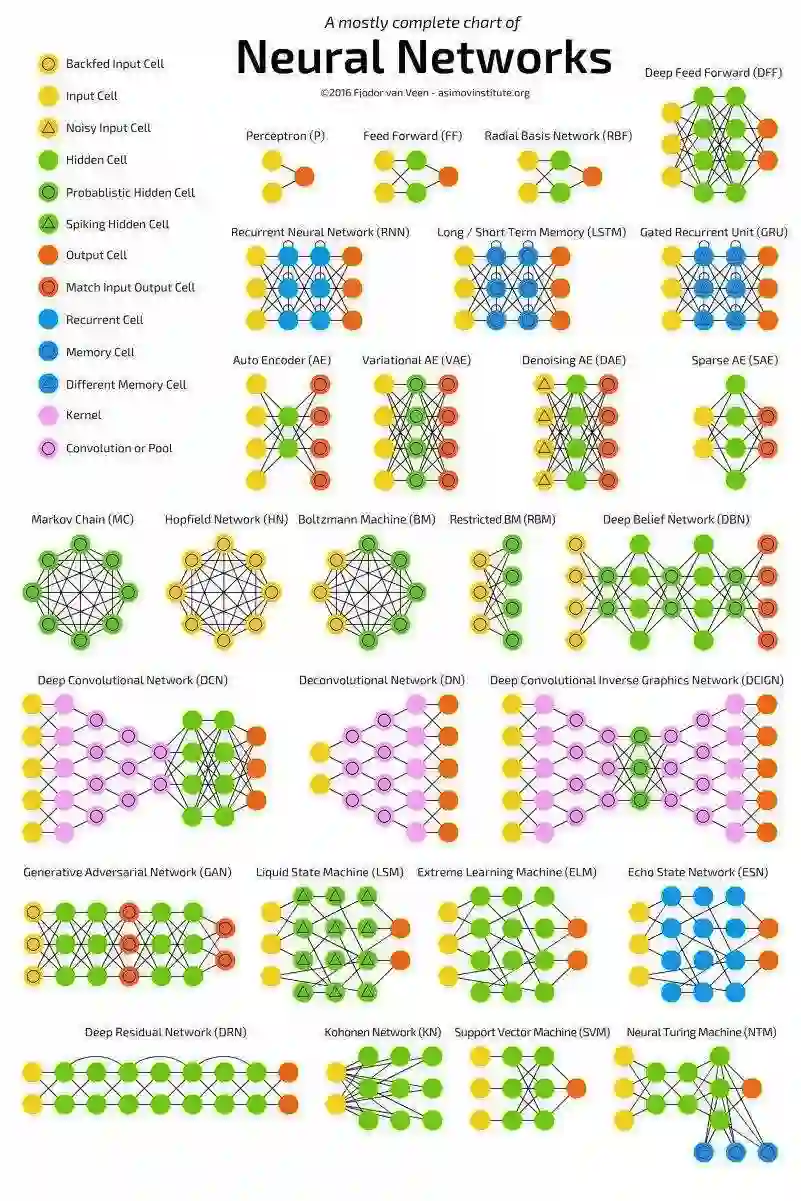
神经网络的种类越来越多,可以说是在呈指数级地增长。我们需要一个一目了然的图表,在这些新出现的网络构架和方法之间进行导航。
幸运的是,来自Asimov研究所的Fjodor van Veen编写了一个关于神经网络的精彩图表(就是上面那张大图)。
下面,我们就来逐一看看图中的27种神经网络:
Perceptron 感知机
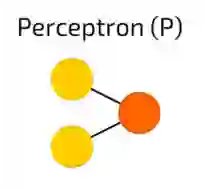
Perceptron 感知机,我们知道的最简单和最古老的神经元模型。接收一些输入,把它们加总,通过激活函数并传递到输出层。这没什么神奇的地方。
前馈神经网络(FF)
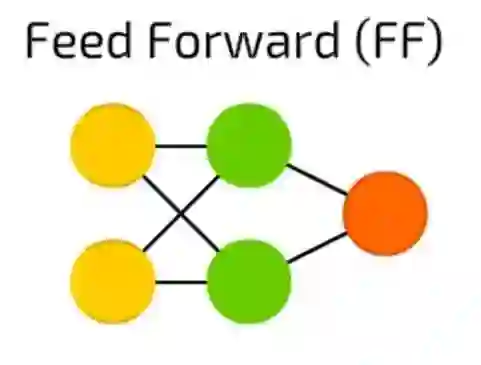
前馈神经网络(FF),这也是一个很古老的方法——这种方法起源于50年代。它的工作原理通常遵循以下规则:
1.所有节点都完全连接
2.激活从输入层流向输出,无回环
3.输入和输出之间有一层(隐含层)
在大多数情况下,这种类型的网络使用反向传播方法进行训练。
RBF 神经网络
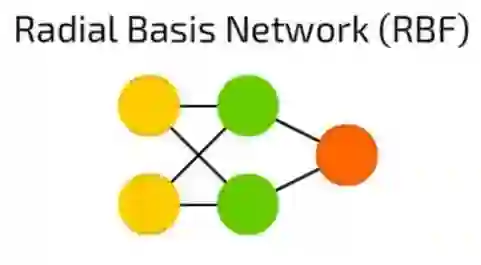
RBF 神经网络实际上是激活函数是径向基函数而非逻辑函数的FF前馈神经网络(FF)。两者之间有什么区别呢?
逻辑函数将某个任意值映射到[0 ,... 1]范围内来,回答“是或否”问题。适用于分类决策系统,但不适用于连续变量。
相反,径向基函数能显示“我们距离目标有多远”。 这完美适用于函数逼近和机器控制(例如作为PID控制器的替代)。
简而言之,这些只是具有不同激活函数和应用方向的前馈网络。
DFF深度前馈神经网络
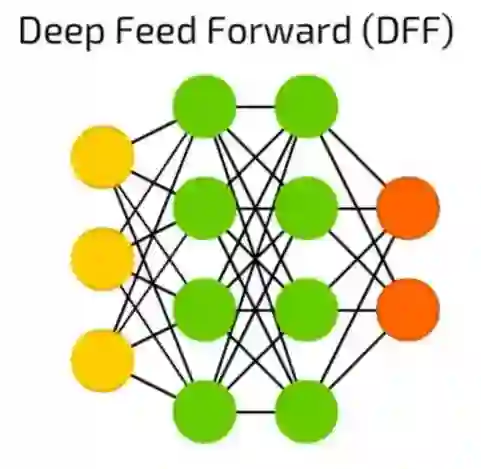
DFF深度前馈神经网络在90年代初期开启了深度学习的潘多拉盒子。这些依然是前馈神经网络,但有不止一个隐含层。那么,它到底有什么特殊性?
在训练传统的前馈神经网络时,我们只向上一层传递了少量的误差信息。由于堆叠更多的层次导致训练时间的指数增长,使得深度前馈神经网络非常不实用。直到00年代初,我们开发了一系列有效的训练深度前馈神经网络的方法; 现在它们构成了现代机器学习系统的核心,能实现前馈神经网络的功能,但效果远高于此。
RNN递归神经网络
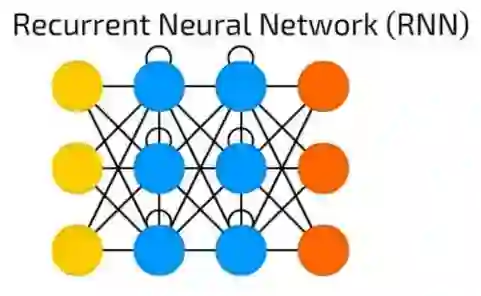
RNN递归神经网络引入不同类型的神经元——递归神经元。这种类型的第一个网络被称为约旦网络(Jordan Network),在网络中每个隐含神经元会收到它自己的在固定延迟(一次或多次迭代)后的输出。除此之外,它与普通的模糊神经网络非常相似。
当然,它有许多变化 — 如传递状态到输入节点,可变延迟等,但主要思想保持不变。这种类型的神经网络主要被使用在上下文很重要的时候——即过去的迭代结果和样本产生的决策会对当前产生影响。最常见的上下文的例子是文本——一个单词只能在前面的单词或句子的上下文中进行分析。
LSTM长短时记忆网络
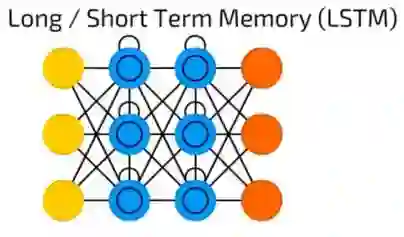
LSTM长短时记忆网络引入了一个存储单元,一个特殊的单元,当数据有时间间隔(或滞后)时可以处理数据。递归神经网络可以通过“记住”前十个词来处理文本,LSTM长短时记忆网络可以通过“记住”许多帧之前发生的事情处理视频帧。 LSTM网络也广泛用于写作和语音识别。
存储单元实际上由一些元素组成,称为门,它们是递归性的,并控制信息如何被记住和遗忘。下图很好的解释了LSTM的结构:

上图的(x)是门,他们拥有自己的权重,有时也有激活函数。在每个样本上,他们决定是否传递数据,擦除记忆等等 - 你可以在这里(http://colah.github.io/posts/2015-08-Understanding-LSTMs/)阅读更详细的解释。 输入门(Input Gate)决定上一个样本有多少的信息将保存在内存中; 输出门调节传输到下一层的数据量,遗忘门(Forget Gate)控制存储记忆的损失率。
然而,这是LSTM单元的一个非常简单的实现,还有许多其他架构存在。
GRU
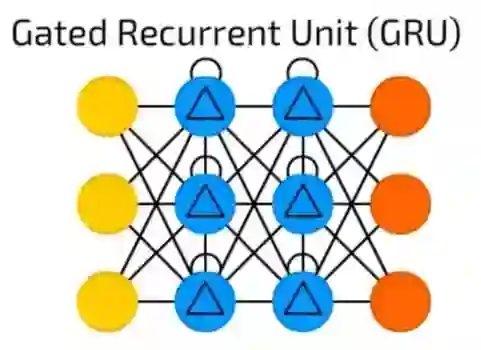
GRU是具有不同门的LSTM。
听起来很简单,但缺少输出门可以更容易基于具体输入重复多次相同的输出,目前此模型在声音(音乐)和语音合成中使用得最多。
实际上的组合虽然有点不同:但是所有的LSTM门都被组合成所谓的更新门(Update Gate),并且复位门(Reset Gate)与输入密切相关。
它们比LSTM消耗资源少,但几乎有相同的效果。
Autoencoders自动编码器
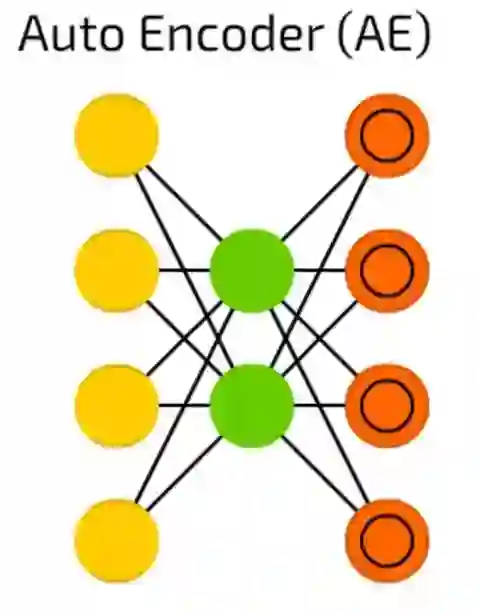
Autoencoders自动编码器用于分类,聚类和特征压缩。
当您训练前馈(FF)神经网络进行分类时,您主要必须在Y类别中提供X个示例,并且期望Y个输出单元格中的一个被激活。 这被称为“监督学习”。
另一方面,自动编码器可以在没有监督的情况下进行训练。它们的结构 - 当隐藏单元数量小于输入单元数量(并且输出单元数量等于输入单元数)时,并且当自动编码器被训练时输出尽可能接近输入的方式,强制自动编码器泛化数据并搜索常见模式。
变分自编码器
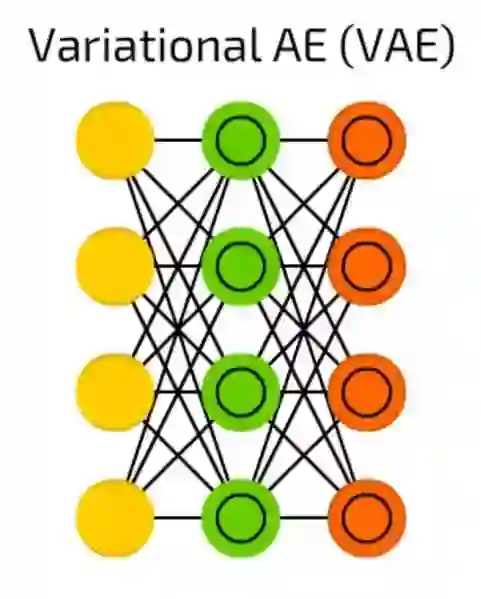
变分自编码器,与一般自编码器相比,它压缩的是概率,而不是特征。
尽管如此简单的改变,但是一般自编码器只能回答当“我们如何归纳数据?”的问题时,变分自编码器回答了“两件事情之间的联系有多强大?我们应该在两件事情之间分配误差还是它们完全独立的?”的问题。
在这里(https://github.com/kvfrans/variational-autoencoder)可以看到一些更深入的解释(含代码示例)。
降噪自动编码器(DAE)
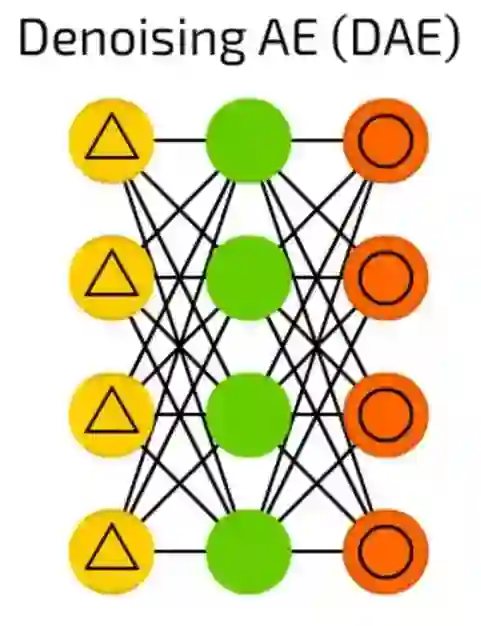
虽然自动编码器很酷,但它们有时找不到最鲁棒的特征,而只是适应输入数据(实际上是过拟合的一个例子)。
降噪自动编码器(DAE)在输入单元上增加了一些噪声 - 通过随机位来改变数据,随机切换输入中的位,等等。通过这样做,一个强制降噪自动编码器从一个有点嘈杂的输入重构输出,使其更加通用,强制选择更常见的特征。
稀疏自编码器(SAE)
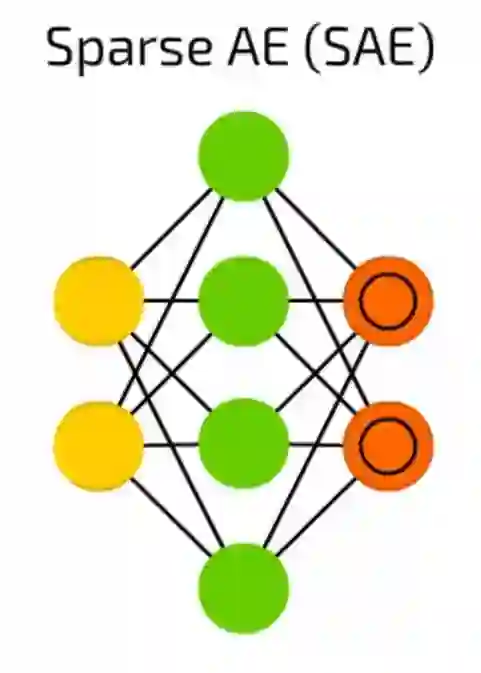
稀疏自编码器(SAE)是另外一个有时候可以抽离出数据中一些隐藏分组样试的自动编码的形式。结构和AE是一样的,但隐藏单元的数量大于输入或输出单元的数量。
马尔可夫链(Markov Chain, MC)

马尔可夫链(Markov Chain, MC)是一个比较老的图表概念了,它的每一个端点都存在一种可能性。过去,我们用它来搭建像“在单词hello之后有0.0053%的概率会出现dear,有0.03551%的概率出现you”这样的文本结构。
这些马尔科夫链并不是典型的神经网络,它可以被用作基于概率的分类(像贝叶斯过滤),用于聚类(对某些类别而言),也被用作有限状态机。
霍普菲尔网络(HN)
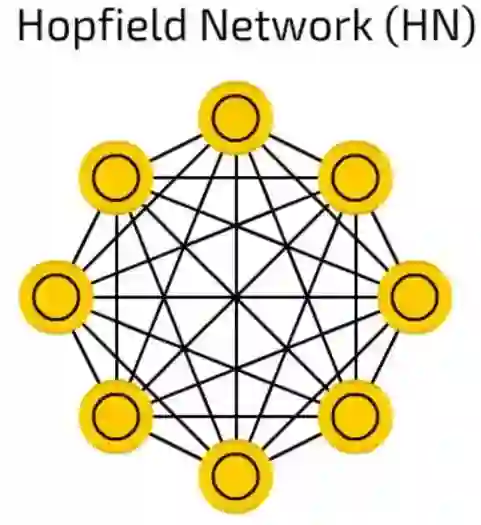
霍普菲尔网络(HN)对一套有限的样本进行训练,所以它们用相同的样本对已知样本作出反应。
在训练前,每一个样本都作为输入样本,在训练之中作为隐藏样本,使用过之后被用作输出样本。
在HN试着重构受训样本的时候,他们可以用于给输入值降噪和修复输入。如果给出一半图片或数列用来学习,它们可以反馈全部样本。
波尔滋曼机(BM)
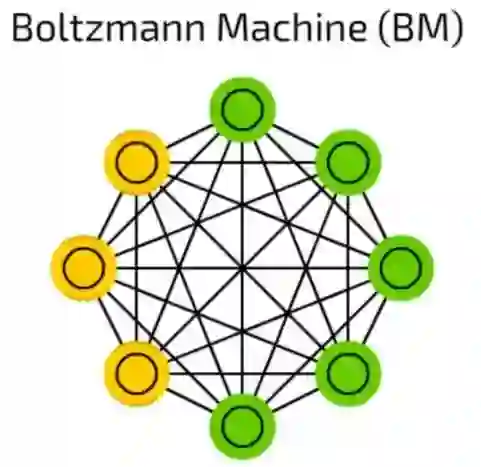
波尔滋曼机(BM)和HN非常相像,有些单元被标记为输入同时也是隐藏单元。在隐藏单元更新其状态时,输入单元就变成了输出单元。(在训练时,BM和HN一个一个的更新单元,而非并行)。
这是第一个成功保留模拟退火方法的网络拓扑。
多层叠的波尔滋曼机可以用于所谓的深度信念网络(等一下会介绍),深度信念网络可以用作特征检测和抽取。
限制型波尔滋曼机(RBM)
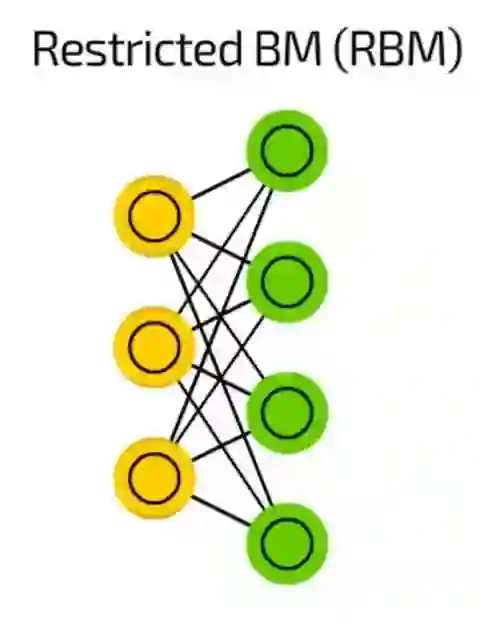
在结构上,限制型波尔滋曼机(RBM)和BM很相似,但由于受限RBM被允许像FF一样用反向传播来训练(唯一的不同的是在反向传播经过数据之前RBM会经过一次输入层)。
深度信念网络(DBN)
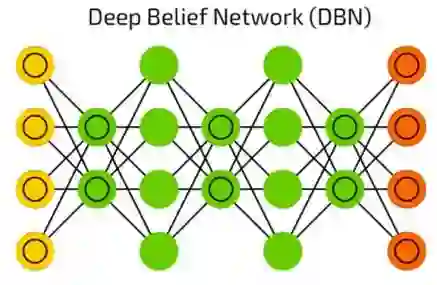
像之前提到的那样,深度信念网络(DBN)实际上是许多波尔滋曼机(被VAE包围)。他们能被连在一起(在一个神经网络训练另一个的时候),并且可以用已经学习过的样式来生成数据。
深度卷积网络(DCN)
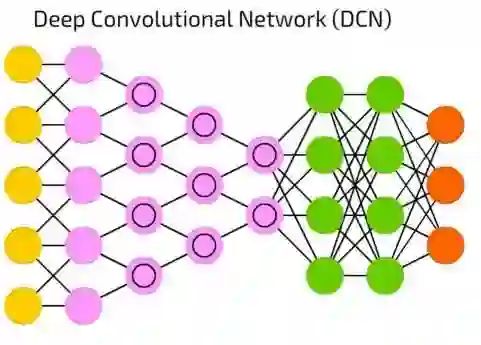
当今,深度卷积网络(DCN)是人工神经网络之星。它具有卷积单元(或者池化层)和内核,每一种都用以不同目的。
卷积核事实上用来处理输入的数据,池化层是用来简化它们(大多数情况是用非线性方程,比如max),来减少不必要的特征。
他们通常被用来做图像识别,它们在图片的一小部分上运行(大约20x20像素)。输入窗口一个像素一个像素的沿着图像滑动。然后数据流向卷积层,卷积层形成一个漏斗(压缩被识别的特征)。从图像识别来讲,第一层识别梯度,第二层识别线,第三层识别形状,以此类推,直到特定的物体那一级。DFF通常被接在卷积层的末端方便未来的数据处理。
去卷积网络(DN)
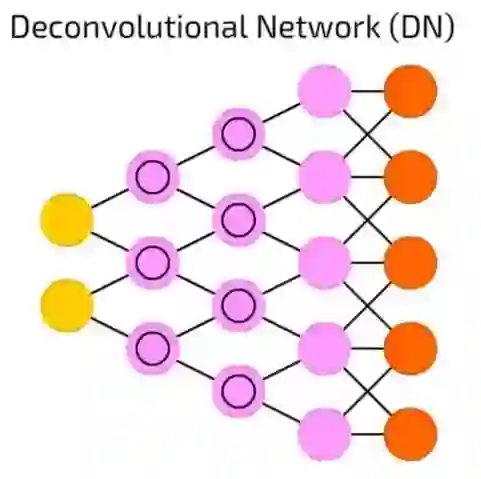
去卷积网络(DN)是将DCN颠倒过来。DN能在获取猫的图片之后生成像(狗:0,蜥蜴:0,马:0,猫:1)一样的向量。DNC能在得到这个向量之后,能画出一只猫。
深度卷积反转图像网络(DCIGN)
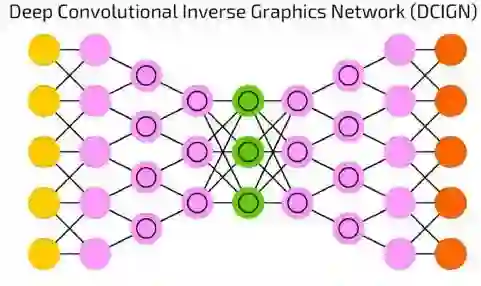
深度卷积反转图像网络(DCIGN),长得像DCN和DN粘在一起,但也不完全是这样。
事实上,它是一个自动编码器,DCN和DN并不是作为两个分开的网络,而是承载网路输入和输出的间隔区。大多数这种神经网络可以被用作图像处理,并且可以处理他们以前没有被训练过的图像。由于其抽象化的水平很高,这些网络可以用于将某个事物从一张图片中移除,重画,或者像大名鼎鼎的CycleGAN一样将一匹马换成一个斑马。
生成对抗网络(GAN)
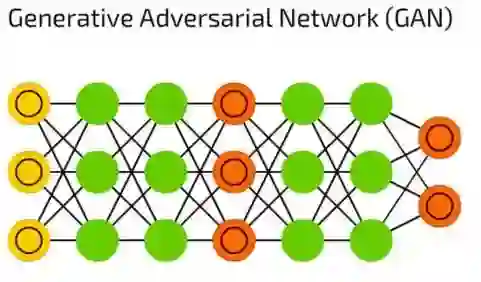
生成对抗网络(GAN)代表了有生成器和分辨器组成的双网络大家族。它们一直在相互伤害——生成器试着生成一些数据,而分辨器接收样本数据后试着分辨出哪些是样本,哪些是生成的。只要你能够保持两种神经网络训练之间的平衡,在不断的进化中,这种神经网络可以生成实际图像。
液体状态机(LSM)
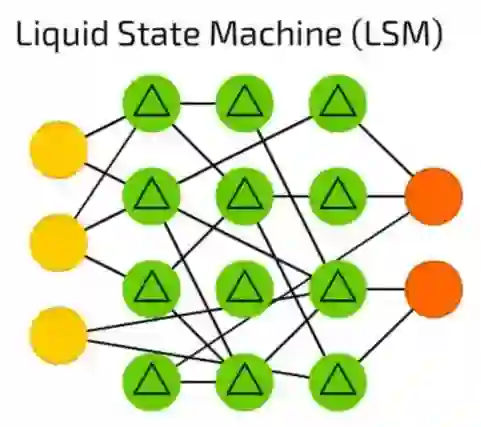
液体状态机(LSM)是一种稀疏的,激活函数被阈值代替了的(并不是全部相连的)神经网络。只有达到阈值的时候,单元格从连续的样本和释放出来的输出中积累价值信息,并再次将内部的副本设为零。
这种想法来自于人脑,这些神经网络被广泛的应用于计算机视觉,语音识别系统,但目前还没有重大突破。
极端学习机(ELM)
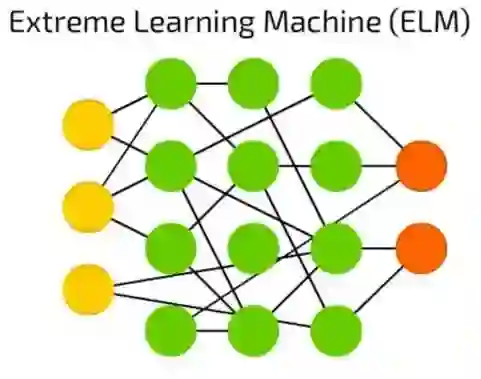
极端学习机(ELM)是通过产生稀疏的随机连接的隐藏层来减少FF网络背后的复杂性。它们需要用到更少计算机的能量,实际的效率很大程度上取决于任务和数据。
回声状态网络(ESN)

回声状态网络(ESN)是重复网络的细分种类。数据会经过输入端,如果被监测到进行了多次迭代(请允许重复网路的特征乱入一下),只有在隐藏层之间的权重会在此之后更新。
据我所知,除了多个理论基准之外,我不知道这种类型的有什么实际应用。欢迎留下你的不同意见~
深度残差网络(DRN)
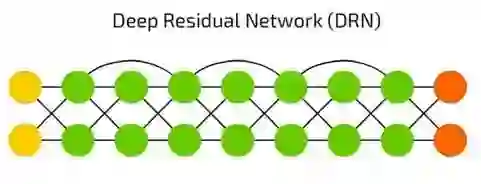
深度残差网络(DRN)是有些输入值的部分会传递到下一层。这一特点可以让它可以做到很深的层级(达到300层),但事实上它们是一种没有明确延时的RNN。
Kohonen神经网络(KN)
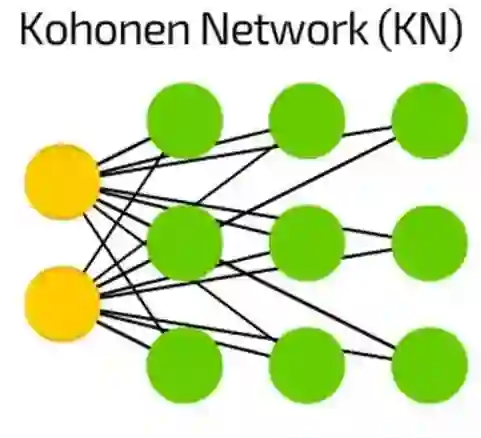
Kohonen神经网络(KN)引入了“单元格距离”的特征。大多数情况下用于分类,这种网络试着调整它们的单元格使其对某种特定的输入作出最可能的反应。当一些单元格更新了, 离他们最近的单元格也会更新。
像SVM一样,这些网络总被认为不是“真正”的神经网络。
支持向量机(SVM)
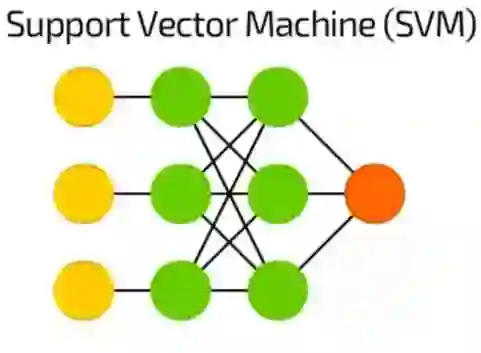
支持向量机(SVM)用于二元分类工作,无论这个网络处理多少维度或输入,结果都会是“是”或“否”。
SVM不是所有情况下都被叫做神经网络。
神经图灵机(NTM)
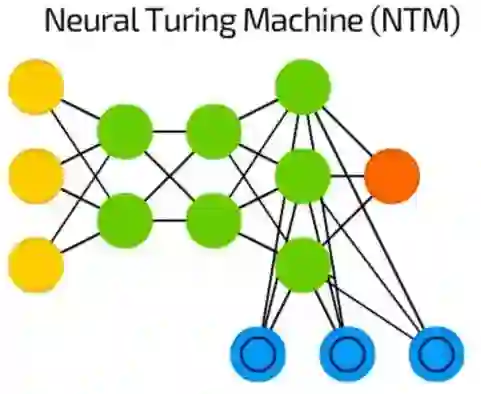
神经网络像是黑箱——我们可以训练它们,得到结果,增强它们,但实际的决定路径大多数我们都是不可见的。
神经图灵机(NTM)就是在尝试解决这个问题——它是一个提取出记忆单元之后的FF。一些作者也说它是一个抽象版的LSTM。
记忆是被内容编址的,这个网络可以基于现状读取记忆,编写记忆,也代表了图灵完备神经网络。
希望这篇总结对你们有所帮助。如文中有错误或者疏漏,欢迎留言给我们纠正或补充。
原文链接:
https://medium.com/towards-data-science/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
【今日机器学习概念】
Have a Great Defination
线下课程推荐|机器学习和人工智能方向
新年新目标,稀牛喊你找工作啦!
✪ 高频面试考点
✪ 行业项目经验
✪ 简历修改完善
✪ 面试注意事项
VIP小班授课,定制化服务,2018春招Offer触手可即!
志愿者介绍
回复“志愿者”加入我们