清华&伯克利ICLR论文:重新思考6大剪枝方法
新智元报道
新智元报道
来源:arXiv
编辑:肖琴、大明
【新智元导读】模型剪枝被认为是一种有效的模型压缩方法。然而,剪枝方法真的有文献中声称的那么有效吗?最近UC Berkeley、清华大学的研究人员提交给ICLR 2019的论文《重新思考剪枝》质疑了六种剪枝方法,引起关注。
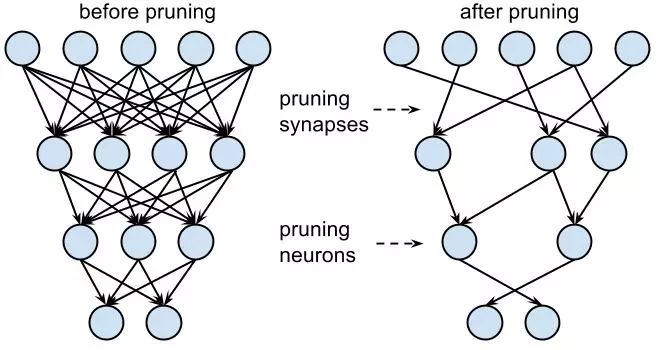
网络剪枝(Network Pruning)是常用的模型压缩方法之一,被广泛用于降低深度模型的繁重计算量。
一个典型的剪枝算法通常有三个阶段,即训练(大型模型),剪枝和微调。在剪枝过程中,根据一定的标准,对冗余权重进行修剪并保留重要权重,以最大限度地保持精确性。
剪枝通常能大幅减少参数数量,压缩空间,从而降低计算量。
然而,剪枝方法真的有它们声称的那么有效吗?
最近一篇提交给ICLR 2019的论文似乎与最近所有network pruning相关的论文结果相矛盾,这篇论文质疑了几个常用的模型剪枝方法的结果,包括韩松(Song Han)获得ICLR2016最佳论文的“Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding”。
这篇论文迅速引起关注,有人认为它甚至可能改变我们在工业中训练和部署模型的workflow。论文作者来自UC Berkeley和清华大学,他们在OpenReview上与被他们质疑的模型作者有一些有意思的反馈,感兴趣的读者可以去看看。地址:
https://openreview.net/forum?id=rJlnB3C5Ym

论文地址:
https://arxiv.org/pdf/1810.05270.pdf
在这篇论文里,作者发现了几个与普遍观念相矛盾的的观察。他们检查了6种最先进的剪枝算法,发现对剪枝后的模型进行fine-tuning,只比使用随机初始化权重训练的网络的性能好一点点,甚至性能更差。
作者说:“对于采用预定义目标网络架构的剪枝算法,可以摆脱整个pipeline并直接从头开始训练目标网络。我们的观察结果对于具有多种网络架构,数据集和任务的各种剪枝算法是一致的。”
作者总结认为,这一发现有几个意义:
1)训练一个大型、over-parameterized的模型对于最终得到一个efficient的小模型不是必需的;
2)为了得到剪枝后的小模型,求取大模型的“important” weights不一定有用;
3)剪枝得到的结构本身,而不是一组“important” weights,是导致最终模型效果提升的原因。这表明一些剪枝算法可以被视为执行了“网络结构搜索”(network architecture search)。
过度参数化(over-parameterization)是深度神经网络的一个普遍属性,这会导致高计算成本和高内存占用。作为一种补救措施,网络剪枝(network pruning)已被证实是一种有效的改进技术,可以在计算预算有限的情况下提高深度网络的效率。
网络剪枝的过程一般包括三个阶段:1)训练一个大型,过度参数化的模型,2)根据特定标准修剪训练好的大模型,以及3)微调(fine-tune)剪枝后的模型以重新获得丢失的性能。
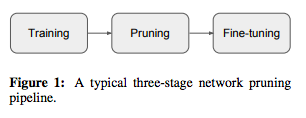
网络剪枝的三个阶段
通常,这种剪枝程序背后有两个共同的信念。
首先,人们认为从训练一个大型的、过度参数化的网络开始是很重要的,因为它提供了一个高性能的模型,从中可以安全地删除一组冗余参数而不会显着损害准确性。因此,这通常被认为是比直接从头开始训练较小的网络更好的方法,也是一种常用的baseline方法。
其次,修剪后得到的结构及其相关权重被认为是获得最终的有效模型所必需的。
因此,大多数现有的剪枝技术选择fine-tune剪枝模型,而不是从头开始训练。剪枝后保留的权重通常被认为是关键的,因此如何准确地选择重要权重集是一个非常活跃的研究课题。
在这项工作中,我们发现上面提到的两种信念都不一定正确。
基于对具有多个网络架构的多个数据集的最新剪枝算法的经验评估,我们得出了两个令人惊讶的观察。
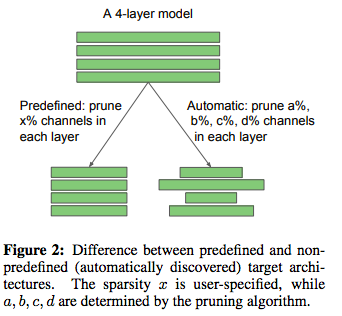
图2:预定义和非预定义目标架构的区别
首先,对于具有预定义目标网络架构的剪枝算法(图2),从随机初始化开始直接训练小型目标模型可以实现与剪枝方法获得的模型相同(甚至更好)的性能。在这种情况下,不需要从大型模型开始,而是可以直接从头开始训练目标模型。
其次,对于没有预定义目标网络的剪枝算法,从头开始训练剪枝模型也可以实现与fine-tune相当或甚至更好的性能。这一观察表明,对于这些剪枝算法,重要的是获得的模型架构,而不是保留的权重,尽管找到目标结构需要训练大型模型。
我们的结果主张重新思考现有的网络剪枝算法。似乎在第一阶段的训练期间的过度参数化并不像以前认为的那样有益。此外,从大型模型继承权重不一定是最优的,并且可能将修剪后的模型陷入糟糕的局部最小值,即使权重被剪枝标准视为“重要”。
相反,我们的结果表明,自动剪枝算法的价值在于识别有效的结构和执行隐式架构搜索(implicit architecture search),而不是选择“important”权重。我们通过精心设计的实验验证了这一假设,并展示了剪枝模型中的模式可以为有效的模型架构提供设计指导。
本节描述了从头开始训练小型目标模型的方法。
目标剪枝架构(Target Pruned Architectures)
我们首先将网络剪枝方法分为两类。在pruning pipeline中,目标剪枝模型的架构可以由人(即预定义的)或剪枝算法(即自动的)来确定(见图2)。
数据集,网络架构和剪枝方法
在network pruning 的相关文献中,CIFAR-10,CIFAR-100和ImageNet数据集是事实上的基准,而VGG,ResNet和DenseNet是常见的网络架构。
我们评估了三种预定义目标架构的剪枝方法:Li et al. (2017), Luo et al. (2017), He et al. (2017b),以及评估了三种自动发现目标模型的剪枝方法Liu et al. (2017), Huang & Wang (2018), Han et al. (2015)。
训练预算
一个关键问题是,我们应该花多长时间从头开始训练这个剪枝后的小模型?用与训练大型模型同样的epoch数量来训练可能是不公平的,因为小模型在一个epoch中需要的计算量要少得多。
在我们的实验中,我们使用Scratch-E表示训练相同epoch的小剪枝模型,用Scratch-B表示训练相同数量的计算预算。
实现(Implementation)
为了使我们的设置尽可能接近原始论文,我们使用了以下协议:
1)如果以前的剪枝方法的训练设置是公开的,如Liu et al.(2017)和Huang & Wang(2018),就采用原始实现;
2)对于更简单的剪枝方法,如Li et al.(2017)和Han et al.(2015),我们重新实现了剪枝方法,得到了与原论文相似的结果;
3)其余两种方法(Luo et al., 2017; He et al., 2017b),剪枝后的模型是公开的,但是没有训练设置,因此我们选择从头训练目标模型。
结果和训练模型的代码可以在这里中找到:
https://github.com/Eric-mingjie/rethinking-networks-pruning
在本节中,我们将展示实验结果,这些实验结果比较了从头开始的训练剪枝模型和基于继承权重进行微调,以及预定义和自动发现的目标体系结构的方法。此外还包括从图像分类到物体检测的转移学习实验。
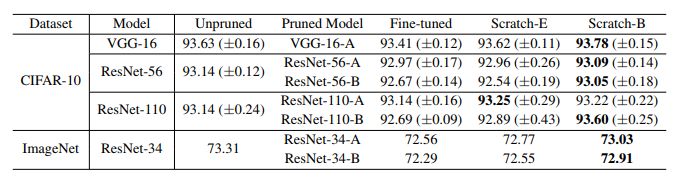
表1:基于L1范数的通道剪枝的结果(准确度)。“剪枝模型”是从大型模型中进行剪枝的模型。原模型和剪枝模型的配置均来自原始论文。
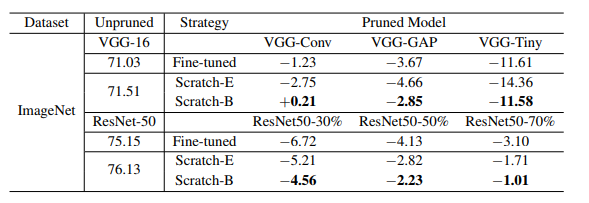
表2:ThiNet的结果(准确度)。“VGG-GAP”和“ResNet50-30%”等指ThiNet中配置的剪枝模型。为了适应本文的方法和原论文之间不同框架的影响,我们比较了相对于未剪枝的大型模型的相对精度下降。例如,对于剪枝后的模型VGG-Conv为-1.23,即表示相对左侧的71.03的精度下降,后者为原始论文中未剪枝的大型VGG-16的报告精度
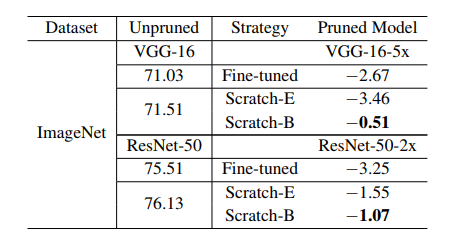
表3:基于回归的特征重建结果(准确度)。与表2类似,我们比较了相对于未剪枝的大型模型的相对精度下降。
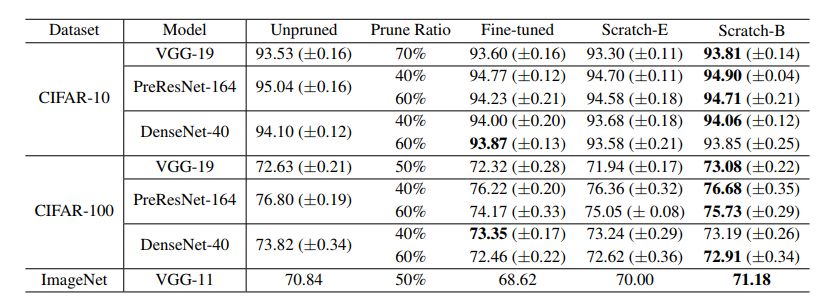
表4:网络Slimming的结果(准确度)“剪枝比”表示在整个网络中,剪枝通道所占的总百分比。每种模型使用与原论文的相同比率。

表5:使用稀疏结构选择的残余块剪枝结果(准确度)。在原始论文中不需要微调,因此存在一个“剪枝”列,而不是“微调”列
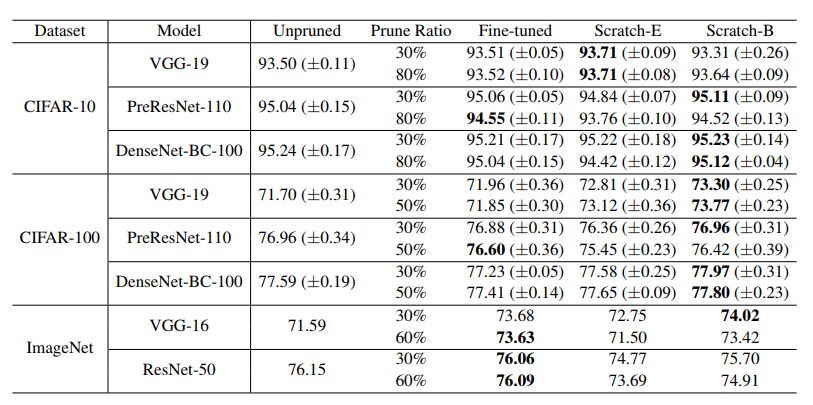
表6:非结构化剪枝的结果(准确度)“剪枝比”表示在所有卷积权重集中,进行剪枝的参数的比例。

表7:用于检测任务的剪枝结果(mAP)。Prune-C指的是剪枝分类预训练的权重,Prune-D指的是在权重转移到检测任务后剪枝。 Scratch-E / B表示从头开始训练分类剪枝模型,移至检测任务。
总之,对于面向预定义目标架构的剪枝方法而言,使用与大型模型(Scratch-E)数量相同的迭代次数来训练小模型,通常就足以实现与三步输出的模型相同的精度。再加上目标架构是预定义的,在实际应用中,人们往往更愿意直接从头开始训练小模型。
此外,如果具备与大型模型相当的计算预算(算力)时,从头训练的模型的性能甚至可能微调模型更高。
我们建议,未来应采用相对高性能的基线方法来评估剪枝方法,尤其是在预定义目标的体系结构剪枝。除了高精度之外,从头开始训练预定义的目标模型与传统的网络剪枝相比具有以下优势:
• 由于模型较小,可以使用更少的GPU资源来训练模型,而且可能比训练原始大型模型速度更快。
• 无需实施剪枝的标准和流程,这些流程有时需要逐层微调和/或需要针对不同的网络架构进行定制。
• 可以避免调整剪枝过程中涉及的其他超参数。
我们的结果可利用剪枝方法来寻找高效的架构或稀疏模式,可以通过自动剪枝方法来完成。此外,在有些情况下,传统的剪枝方法比从头开始训练要快得多,比如:
• 已经提供预训练的大型模型,且训练预算很少。
• 需要获得不同大小的多个模型,在这种情况下,可以训练大型模型,然后以不同的比例剪枝。
总之,我们的实验表明,从头开始训练小修剪模型几乎总能达到与典型的“训练-剪枝-微调”流程获得的模型相当或更高的精度。这改变了我们对过度参数化的必要性的理解,进一步证明了自动剪枝算法的价值,可以用来寻找高效的架构,并为架构设计提供指导。
论文地址:
Rethinking the Value of Network Pruning
https://arxiv.org/pdf/1810.05270.pdf
新智元AI WORLD 2018
世界人工智能峰会全程回顾
新智元于9月20日在北京国家会议中心举办AI WORLD 2018世界人工智能峰会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
全程回顾新智元 AI World 2018 世界人工智能峰会盛况:
爱奇艺
上午:https://www.iqiyi.com/v_19rr54cusk.html
下午:https://www.iqiyi.com/v_19rr54hels.html
新浪:http://video.sina.com.cn/l/p/1724373.html




