「off-policy强化学习」被低估!Google Brain等提出使用off-policy算法的「机器人抓取」任务基准


本文转自雷克世界(ID:raicworld)
编译 | 嗯~阿童木呀
在本文中,我们探讨了用于基于视觉的机器人抓取操作的深度强化学习算法。无模型深度强化学习(RL)已经在一系列具有挑战性的环境中得到了成功应用,但算法的激增使得我们难以辨别出哪种特定的方法最适合于执行一个丰富的、多样化的任务,例如抓取。为了回答这一问题,我们提出了一个机器人抓取的模拟基准,强调了对于没见过的目标的策略学习和泛化。
Off-policy学习能够在各种各样的目标上对抓取数据加以利用,而且多样性对于使该方法能够在训练期间泛化到没见过的目标中起到至关重要的作用。我们对针对各种Q函数估计方法的基准任务进行了评估,一种是以往提出的,使用深度神经网络模型进行机器人抓取,以及一种基于蒙特卡罗回归估计(Monte Carlo return estimation)和off-policy校正相组合的新方法。我们的研究结果表明,几种简单的方法为诸如双Qlearning这样的通用算法提供了一个令人惊讶的强大竞争对手,而我们对稳定性的分析揭示了算法之间的相对权衡。

机器人抓取是最基本的机器人操作任务之一:在与环境中的目标进行交互之前,机器人通常必须从先抓取它们开始。在以前的机器人操作研究中往往试图通过各种各样的方法解决抓取问题,从分析抓取度量到基于学习的方法。直接从自我监督中学习抓取为这一领域提供了相当有发展前景的研究方向:如果机器人能够通过反复的经验逐渐提高自身的抓取能力,那么它可能会在极少人为干预的情况下达到非常高的熟练程度。
实际上,受计算机视觉技术启发的,基于学习的方法近年来取得了良好的效果。然而,这些方法通常不是导致抓取任务序列方面结果的原因所在,要么选择一个单一的抓取姿势,要么贪婪地反复选择下一个最有希望抓取的姿势。虽然先前的研究已经在一个序列决策上下文中,对使用深度强化学习(RL)作为机器人抓取的框架进行了探索,但这样的研究要么仅限于单一的目标,要么是诸如立方体这样的简单几何形状。
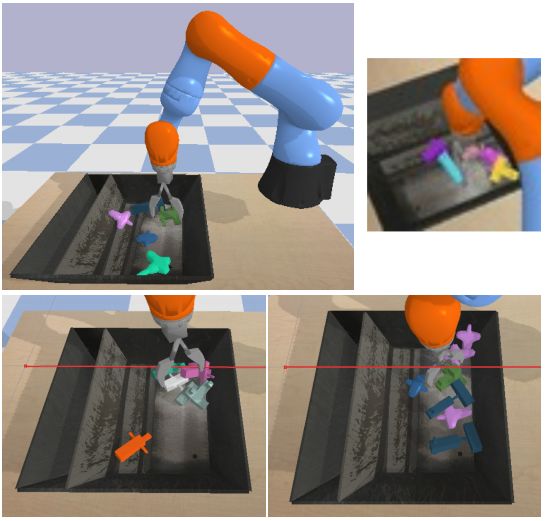
左上角:我们模拟抓取环境的演示。机器人必须在容器中拾取目标,所使用的随机目标如图2所示的。右上角:对机器人的样本观察。左下角:在第一个任务中,机器人选择了各种各样的随机目标,并将其泛化到没见过的测试目标中。右下角:在第二项任务中,机器人必须从杂乱的箱子中挑出一个紫色的十字形物体。
在这项研究中,通过在一个真实的模拟基准中对各种强化学习方法加以比较,我们探讨了强化学习是如何用于自动学习用于不同物体的机器人抓取技巧。
在基于学习的抓取中,最重要的挑战之一是泛化能力:该系统能够学习抓取模式和线索,从而使其能够成功对训练期间不可见的目标实现抓取吗?成功的泛化通常需要对各种各样的目标和场景进行训练,以获得可泛化的感知和控制。先前有关抓取的监督学习研究已经使用了数万乃至数百万个抓取动作,涉及数百个不同的目标。
这种机制对于强化学习来说是一个重大挑战:如果学习主要是on-policy进行的,那么机器人必须反复重访先前所看到的目标以避免遗忘,这使得处理极其多样化的抓取场景变得更加困难。因此,Off-policy强化学习方法可能更适用于诸如抓取这样的任务,其中各种先前看到的目标对于泛化来说具有至关重要的作用。事实上,在以前的研究中所探讨的监督学习方法可以被形式化为Off-policy强化学习的特例,而不考虑抓取任务的序列本质。

左:用于训练的900个物件中的30个。右:100个测试物件中的10个。
我们在本文中的研究目标是了解哪些Off-policy强化学习算法最适合基于视觉的机器人抓取任务。
近年来,为解决Atari游戏和简单模拟机器人的控制等问题,科学家们已经提出了许多无模型、Off-policy深度强化学习方法。然而,这些研究并没有对机器人抓取任务中出现的各种各样的高度变化的情况进行探索,重点通常集中在最终的性能表现上(例如期望奖励),而不是泛化到新的目标和场景中。此外,训练通常涉及逐步收集越来越多的on-policy数据,同时将旧的off-policy数据保留在重放缓冲区中。我们研究这些算法的相对性能是如何在一个强调多样性和泛化能力的off-policy机制中进行变化的。
我们对这些方法的讨论,为以往研究中的各种Q-函数估计技术提供了一个统一的处理方法。我们的研究结果表明,深度强化学习可以成功地从原始像素中学习抓取多种目标,并且可以在我们的模拟器中对以往没有见过的目标进行抓取,且平均成功率为90%。
令人惊讶的是,在这个具有挑战性的领域中,朴素蒙特卡罗评估是一个强有力的基准,尽管在off-policy情况下存在一定的偏差。我们提出的无偏差、校正版本实现了可与其相媲美的性能表现。深度Q-learning在数据有限的机制系统下表现得也很出色。我们还分析了不同方法的稳定性,以及在on-policy 和off-policy情况下,不同off-policy数据数量情况下的性能差异。我们的研究结果揭示了不同方法是如何在现实的模拟机器人任务上进行比较的,并提出了开发新的、更有效的用于机器人操作的深度强化学习算法的途径。
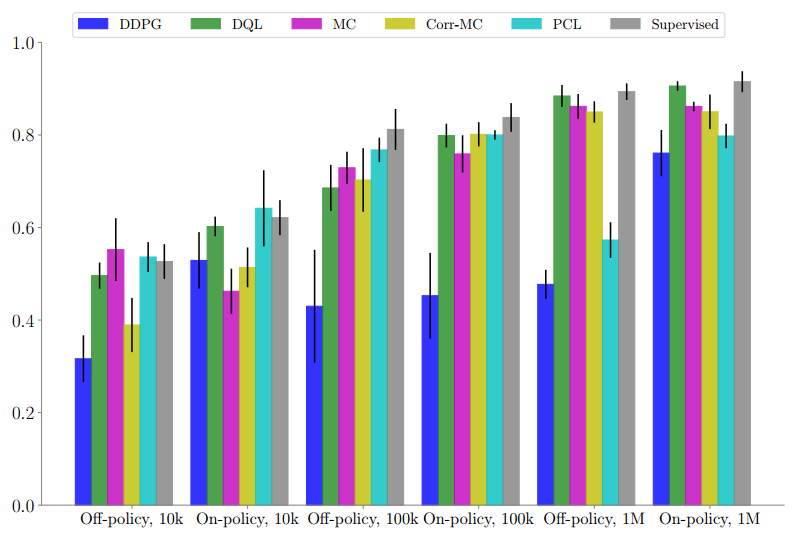
对不同数据集大小的测试目标的定期抓取性能展示。DQL和监督基线性能表现最好。从9个独立运行的随机seeds中计算的标准差。
我们提出了一系列off-policy、无模型深度强化学习算法的经验评估。我们的算法集包括通用的无模型方法,如双Q-learning、DDPG和PCL,以及基于监督学习的使用合成动作的先验方法。
除此之外,我们的方法中还涵盖一个朴素蒙特卡罗方法,它在off-policy情况下存在偏差,但却能够取得合理的性能表现,且常常优于DDPG,以及一个该蒙特卡罗方法的修正版本,也是这项研究的一个新成果。我们的研究实验是在一个涉及两种任务的多样化抓取模拟器上进行的,一个抓取任务是对训练期间全新的、不可见随机目标的泛化能力的评估,以及一个目标抓取任务,它需要在混乱状态下的特定类型的目标进行分离并抓取。
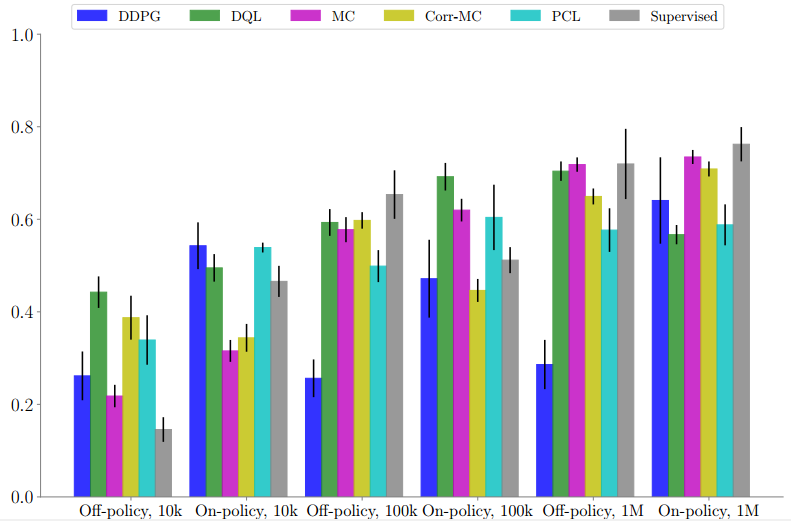
针对不同的数据集大小,将抓取目标锁定在一个有三个目标物件和四个非目标物件的混乱的箱子中。DQL在较少数据和off-policy环境中表现良好,而蒙特卡罗和修正版蒙特卡罗方法在具有最大量数据的环境中表现最好。
我们的评估结果表明,无论是对于on-policy还是off-policy学习来说,DQL的性能表现都要比较少数据机制下的其他算法好得多,并且附加带有对超参数选择具有鲁棒性的理想属性。当数据更丰富时,诸如蒙特卡罗或蒙特卡罗修正版本这样的回归到多步返回的算法,通常会获得稍好的性能表现。
在考虑算法特征时,我们发现使用演员网络(actor network)会大大降低稳定性,导致性能表现较差和严重的超参数敏感性。当数据充足时,使用完整事件值进行监督的方法往往表现得更好,而自助式(bootstrapped)DQL方法在较少数据情况下表现更好。
这些结果表明,在可以使用off-policy数据的机器人环境中,更适合使用单一网络方法以维护稳定性;而在数据充足时,使用(修正)完整事件返回的方法是更好的首选,而bootstrapped方法更适合用于较少数据环境中。这一结果的本质含义是,在未来,对机器人强化学习算法的研究可能会集中在通过调整基于数据可用性的目标值类型以将最佳自助式和多步返回结合起来。我们研究的另一个自然延伸是在实际环境中评估类似的方法。由于我们所评估的算法都能在off-policy环境下成功运行,因此在现实环境中使用它们也可能是一个合理且实用的选择。
原文来源:arXiv
作者:Deirdre Quillen、Eric Jang、Ofir Nachum、Chelsea Finn、Julian Ibarz、Sergey Levine
原文链接:https://arxiv.org/pdf/1802.10264.pdf





