CV困境如何破:训练样本有限、2D视觉平面 VS 3D真实场景...
机器之心原创
本文介绍了计算机视觉在实际场景和实际任务中存在的三种困境,以案例详细说明,并给出了潜在的解决方案。

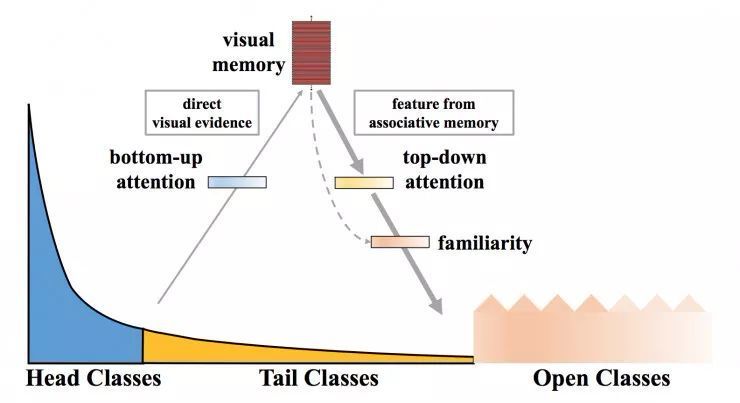
3. 潜在解决方案

登录查看更多
相关内容

Arxiv
5+阅读 · 2018年12月15日
Arxiv
15+阅读 · 2018年5月24日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年12月15日
Arxiv
15+阅读 · 2018年5月24日