OpenViDial:一个大规模多模态对话数据集

实验表明,融合细粒度的视觉信息,模型能够生成质量更高的对话,而只有文本的模型效果最差,这验证了视觉信息在对话中的必要性。本文希望所提出的数据集及模型能促进学界大规模多模态对话学习的发展。

论文标题:
OpenViDial: A Large-Scale, Open-Domain Dialogue Dataset with Visual Contexts
论文作者:
Yuxian Meng, Shuhe Wang, Qinghong Han, Xiaofei Sun, Fei Wu, Rui Yan, Jiwei Li
论文链接:
https://arxiv.org/abs/2012.15015
代码与数据集链接:
https://github.com/ShannonAI/OpenViDial

对话中的视觉信息

上述两个例子充分体现了视觉信息在人类对话中的必要性,正是这种多模态的信息融合,人们的对话才变得精准而可靠。
然而,当前的对话模型大都忽视了对话过程中的视觉信息,这主要是相应数据集的缺失造成的。

基于上述视觉特征在对话中的必要性,以及当前多模态对话数据集缺失的现状,本文构造了一个大规模多模态对话数据集 OpenViDial。OpenViDial 中的数据来自电影与电视剧,使用 OCR 从视频中抽取出对话文本,并配以当前对话所在的图像,因此,每一句话都有相应视觉背景,最终形成包含百万余条句子的大规模多模态对话数据集。
基于 OpenViDial,本文还构建了三个视觉对话模型,将图像信息融入到对话生成的过程中。实验表明,融入视觉信息的模型可以生成质量更高的对话,而融入细粒度的视觉信息,如物体,可以实现最好效果。这验证了视觉信息对于对话生成的重要性。
总的来说,本文的贡献如下:
-
构建并开源 OpenViDial,一个大规模多模态对话生成数据集,包含百万余条对话句子,每条句子都配以对应的视觉背景; -
提出视觉对话模型,将视觉信息以不同的粒度融入到对话生成中; -
通过实验验证了视觉信息对高质量对话生成的必要性,促进学界对多模态对话数据集及模型的研究。

如何抽取视频中的字幕?
-
如何确保对话完整性与连续性?
OpenViDial 分别用 OCR 与后处理解决上述问题。

为了从视频中抽取字幕文本,OpenViDial 首先训练了一个 OCR 模型。训练数据通过“图片+添加字幕”的形式构造得到。所添加的字幕文本从 CommonCrawl 随机获得,而图片则使用现有的 OCR 模型 EasyOCR,去检测电影或电视剧中不包含任何文本的图片。
这里没有使用互联网上普遍存在的图片,如 ImageNet,而使用现有的 OCR 模型从视频中抽取,是为了尽可能保证数据分布的一致性。
在获得了文本和图片后,就可以把文本随机添加到图片上构造训练数据。在文本定位阶段(detection),OpenViDial 使用 PSE 模型作为模型架构。在文本识别阶段(recognition),则使用 CRNN 作为模型架构。
训练后的模型在测试集上取得字级别 99.98% 的准确率,在句级别上取得 98.4% 的准确率,满足字幕抽取的需求。

数据后处理
在得到原始数据集后,还需要考虑一些特殊情况,减少所包含的噪音。
第二是重复图片问题。由于字幕停留往往会跨越多个连续图片,所以就可能造成诸多高度相似的数据点。如果出现这种情况,则 OpenViDial 只保留中间的数据点而丢弃其他数据点。


模型
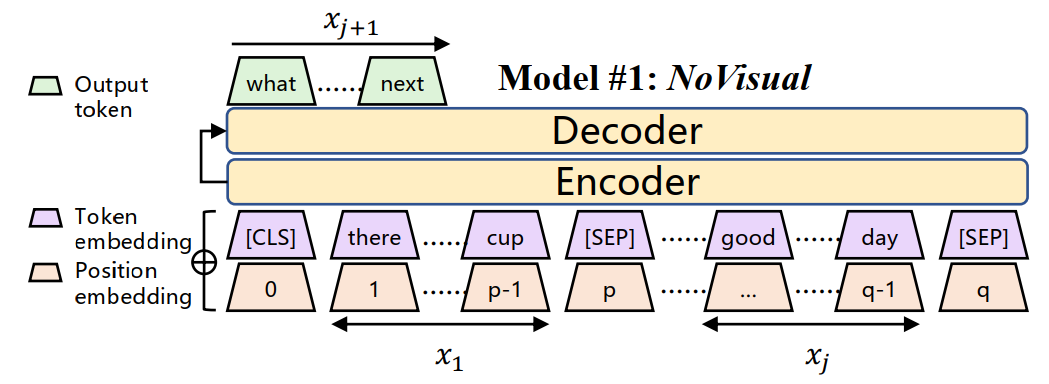
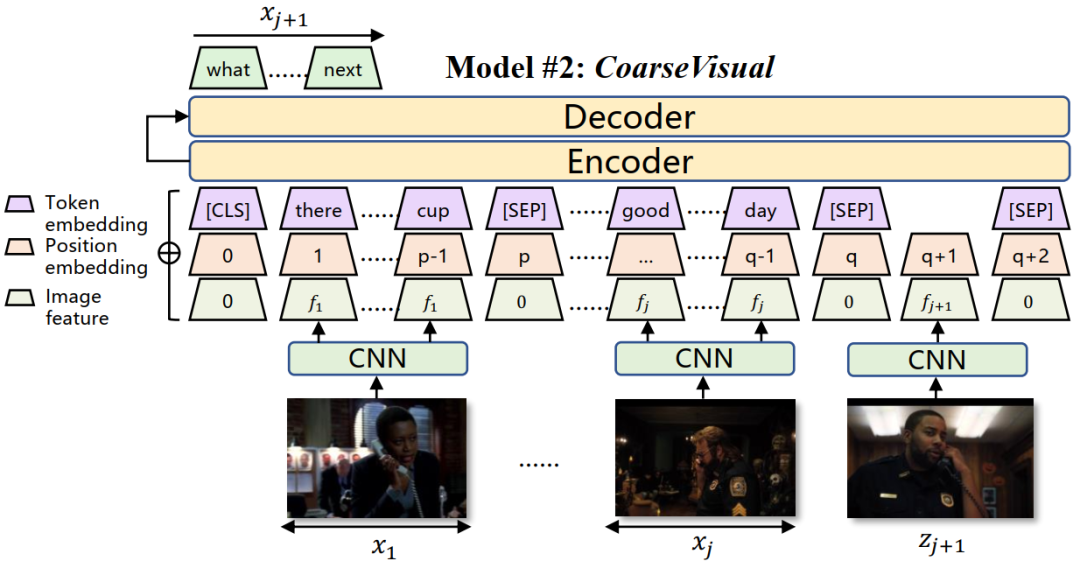
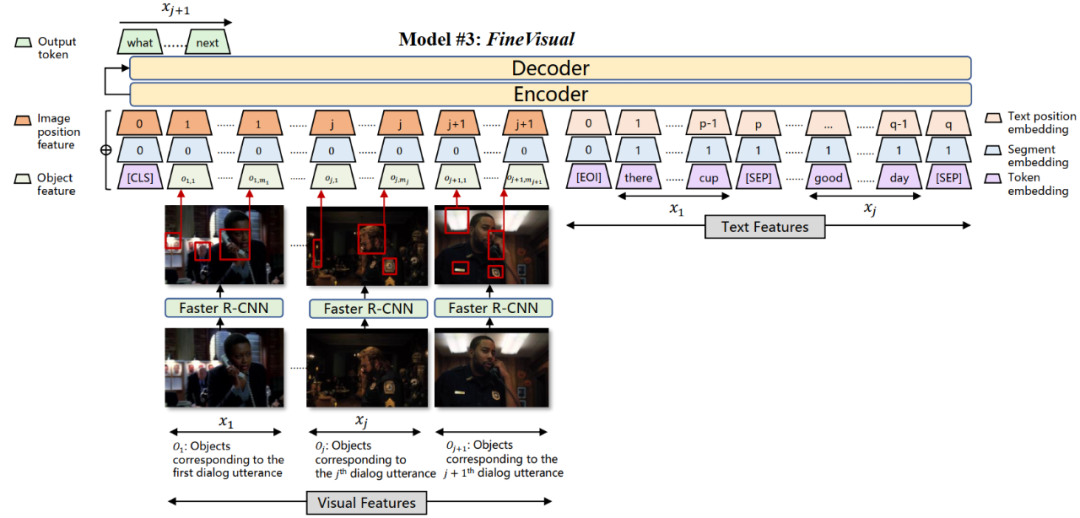

实验
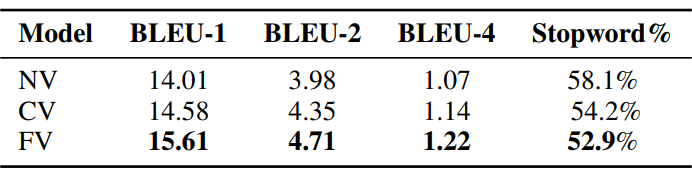
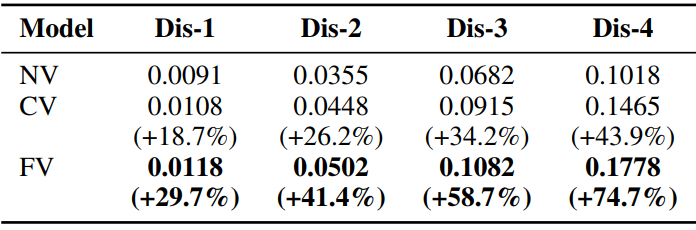
本文使用上述三个模型在 OpenViDial 上进行实验。测评指标有 BLEU、Diversity 和 Stopword%,用于衡量所生成对话的精确性、多样性和丰富性。
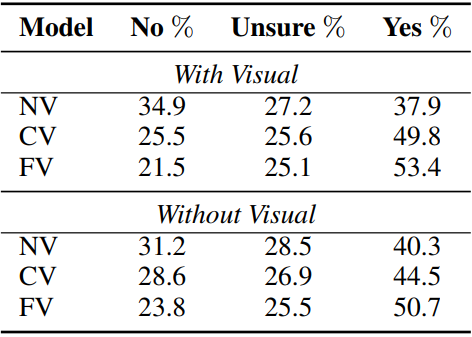
下表是人工测评的结果。给定图片及模型生成的对话,标注者需要评价所生成的回答是否(1)与图片相关,(2)足够具有多样性,(3)可读。人工给出的评价将被归为 No/Unsure/Yes 这三个维度。
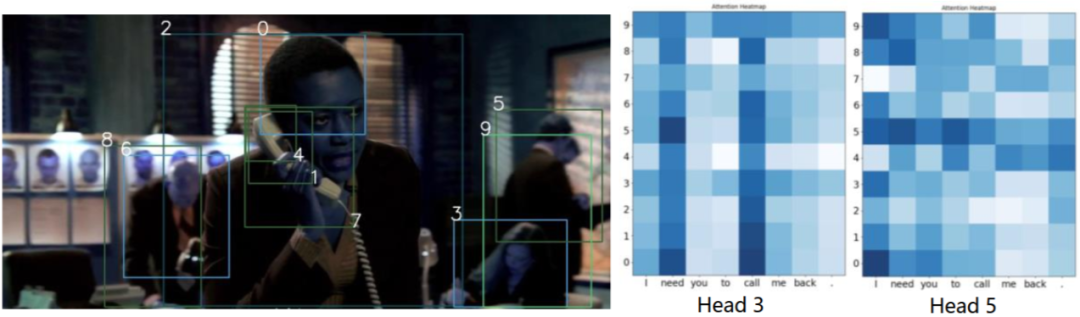
下面是两个具体的例子,给定前两步的图片与对话,模型需要根据当前步的图片生成对应的对话。纯文本模型 NV 与粗粒度模型 CV 总是生成无意义的回复,如 I'm sorry 或者 I don't know,而细粒度模型 CV 能够根据图片中的物体生成相关的对话。


小结
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





