深度学习实践:从零开始做电影评论文本情感分析
最近读了《Python深度学习》, 是一本好书,很棒,隆重推荐。
本书由Keras之父、现任Google人工智能研究员的弗朗索瓦•肖莱(François Chollet)执笔,详尽介绍了用Python和Keras进行深度学习的探索实践,涉及计算机视觉、自然语言处理、生成式模型等应用。书中包含30多个代码示例,步骤讲解详细透彻。由于本书立足于人工智能的可达性和大众化,读者无须具备机器学习相关背景知识即可展开阅读。在学习完本书后,读者将具备搭建自己的深度学习环境、建立图像识别模型、生成图像和文字等能力。
各方面都很好,但是总感觉哪里有点欠缺,后来想想,可能是作者做得太好了,把数据预处理都做得好好的,所以你才能“20行搞定情感分析”,这可能也是学习其他深度学习工具过程中要面临的一个问题,很多工具都提供了预处理好的数据,导致学习过程中只需要调用相关接口即可。不过在实际工作中,数据的预处理是非常重要的,从数据获取,到数据清洗,再到基本的数据处理,例如中文需要分词,英文需要Tokenize, Truecase或者Lowercase等,还有去停用词等等,在将数据“喂”给工具之前,有很多事情要做。这个部分,貌似是当前一些教程有所欠缺的地方,所以才有了这个“从零开始做”的想法和系列,准备弥补一下这个缺失,第一个例子就拿《Python深度学习》这本书第一个文本挖掘例子练手:电影评论文本分类-二分类问题,这也可以归结为一个情感分析任务。
首先介绍一下这个原始的电影评论数据集aclIMDB: Large Movie Review Dataset, 这个数据集由斯坦福大学人工智能实验室于2011年推出,包含25000条训练数据和25000条测试数据,另外包含约50000条没有标签的辅助数据。训练集和测试集又分别包含12500条正例(正向评价pos)和12500负例(负向评价neg)。关于数据,更详细的介绍可参考该数据集的官网:http://ai.stanford.edu/~amaas/data/sentiment/, paper: Learning Word Vectors for Sentiment Analysis, 和数据集里的readme。
然后下载和处理这份数据:Large Movie Review Dataset v1.0,下载链接;
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
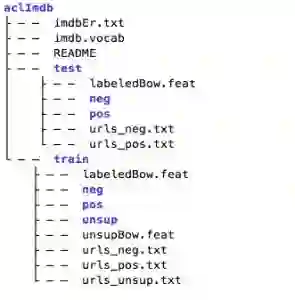
下载之后进行解压:tar -zxvf aclImdb.tar.gz,可以用tree命令看一下aclImdb的目录结构:
tree aclImdb -L 2
继续进入训练集正例的目录看一下: cd aclImdb/train/pos/:

这个里面包含了12500篇英文评论,我们随机打开一个看一下里面的文本内容:
vim 1234_10.txt
I grew up watching this movie ,and I still love it just as much today as when i was a kid. Don't listen to the critic reviews. They are not accurate on this film.Eddie Murphy really shines in his roll.You can sit down with your whole family and everybody will enjoy it.I recommend this movie to everybody to see. It is a comedy with a touch of fantasy.With demons ,dragons,and a little bald kid with God like powers.This movie takes you from L.A. to Tibet , of into the amazing view of the wondrous temples of the mountains in Tibet.Just a beautiful view! So go do your self a favor and snatch this one up! You wont regret it!
在预处理之前,还要想好目标是什么?这里主要想复用一下Keras的相关接口,Keras官方提供了一个调用imdb预处理数据的Python脚本imdb.py,但是(貌似)没有提供做这个数据的脚本(如果提供了,也不用写这篇文章了),这个脚本在Keras官方的github路径如下:
https://github.com/keras-team/keras/blob/master/keras/datasets/imdb.py
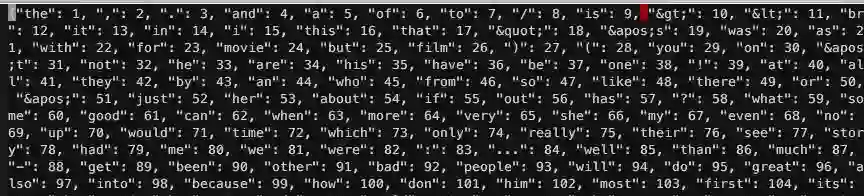
这个脚本主要读两个数据,一个是 imdb_word_index.json ,另外一个是 imdb.npz。前者是单词索引文件,按单词频率高低排序,第一个索引是"the: 1", 可以看一下:

后者是Numpy NPZ 文件,存了多个 numpy 数组文件,这里主要包括imdb的训练集和测试集基于上面的单词索引文件转化为id后的数据,我们看一下:
In [1]: import numpy as npIn [2]: f = np.load('imdb.npz')In [3]: f.keys()Out[3]: ['x_test', 'x_train', 'y_train', 'y_test']In [4]: x_train, y_train, x_test, y_test = f['x_train'], f['y_train'], f['x_test'], f['y_test']In [5]: len(x_train), len(y_train), len(x_test), len(y_test)Out[5]: (25000, 25000, 25000, 25000)In [6]: x_train.shapeOut[6]: (25000,)In [7]: y_train.shapeOut[7]: (25000,)...In [12]: x_train[0:2]Out[12]:array([ [23022, 309, 6, 3, 1069, ... , 3, 2237, 12, 9, 215],[23777, 39, 81226, 14, 739, ... , 6018, 22, 5, 336, 406]], dtype=object)In [13]: y_train[0:2]Out[13]: array([1, 1])In [14]: x_test.shapeOut[14]: (25000,)In [15]: y_test.shapeOut[15]: (25000,)In [16]: x_test[0:2]Out[16]:array([ [10, 432, 2, 216, 11, ... , 64, 9, 156, 22, 1916],[281, 676, 164, 985, 5696, ... , 1012, 5, 166, 32, 308]], dtype=object)In [17]: y_test[0:2]Out[17]: array([1, 1])
现在就可以按照这个思路处理原始的aclIMDB数据了,我已在Github上建了一个项目: AINLP(与我们的公众号AINLP同名,欢迎同时关注), 子项目 aclimdb_sentiment_analysis_from_scratch 里分别提供了几个Python脚本,兼容Python2和Python3, 已在Python2.7和Python 3.6, 3.7的环境下运行通过(其他没测),不过在运行这几个脚本之前,需要先安装一下相关的依赖:requirement.txt
numpy==1.15.2 sacremoses==0.0.5 six==1.11.0
其中sacremoses提供了英文tokenizer的接口,之前是通过NLTK调用里面的MosesTokenizer,但是发现最近这个接口因开源证书的问题从NLTK里面移除了,sacremoses是单独移植的一个版本,接口完全一致。首先来建立单词索引,由脚本 build_word_index.py 来完成,这里只处理训练集和测试集中的数据,忽略没有标签的数据(unsup):
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author: TextMiner (textminer@foxmail.com)# Copyright 2018 @ AINLPfrom __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport argparseimport jsonimport numpy as npimport reimport sixfrom collections import OrderedDictfrom os import walkfrom sacremoses import MosesTokenizertokenizer = MosesTokenizer()def build_word_index(input_dir, output_json):word_count = OrderedDict()for root, dirs, files in walk(input_dir):for filename in files:if re.match(".*\d+_\d+.txt", filename):filepath = root + '/' + filenameprint(filepath)if 'unsup' in filepath:continuewith open(filepath, 'r') as f:for line in f:if six.PY2:tokenize_words = tokenizer.tokenize(line.decode('utf-8').strip())else:tokenize_words = tokenizer.tokenize(line.strip())lower_words = [word.lower() for word in tokenize_words]for word in lower_words:if word not in word_count:word_count[word] = 0word_count[word] += 1words = list(word_count.keys())counts = list(word_count.values())sorted_idx = np.argsort(counts)sorted_words = [words[ii] for ii in sorted_idx[::-1]]word_index = OrderedDict()for ii, ww in enumerate(sorted_words):word_index[ww] = ii + 1with open(output_json, 'w') as fp:json.dump(word_index, fp)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-id', '--input_dir', type=str, nargs='?',default='./data/aclImdb/',help='input data directory')parser.add_argument('-ot', '--output_json', type=str, nargs='?',default='./data/aclimdb_word_index.json',help='output word index dict json')args = parser.parse_args()input_dir = args.input_diroutput_json = args.output_jsonbuild_word_index(input_dir, output_json)
注意里面的文件目录位置,我的文件结构大概是这样的:

这里把解压后的aclIMDB目录放在data下,如果你按这个结构来安排数据,就可以直接执行,否则,请根据程序里的参数指定文件目录。运行:
python build_word_index.py
程序执行完毕后在data目录下产生一个单词索引文件:aclimdb_word_index.json ,因为程序中使用了OrderedDict, dump之后的json文件还能看到有序的单词索引,注意,这里没有清除标点符号, 也没有去掉 html tag,有兴趣的同学可以试试进一步完善:
接下来,我们提供第二个脚本 build_data_index.py 对训练集和测试集进行处理,基于上一个脚本产生的单词索引文件 aclimdb_word_index.json 将训练集和测试集的明文转换为数字id,生成4个numpy数组(x_train, y_train, x_test, y_test),并存储为npz文件:
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author: TextMiner (textminer@foxmail.com)# Copyright 2018 @ AINLPfrom __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport argparseimport jsonimport numpy as npimport reimport sixfrom collections import OrderedDictfrom os import walkfrom sacremoses import MosesTokenizertokenizer = MosesTokenizer()def get_word_index(word_index_path):with open(word_index_path) as f:return json.load(f)def build_data_index(input_dir, word_index):train_x = []train_y = []for root, dirs, files in walk(input_dir):for filename in files:if re.match(".*\d+_\d+.txt", filename):filepath = root + '/' + filenameprint(filepath)if 'pos' in filepath:train_y.append(1)elif 'neg' in filepath:train_y.append(0)else:continuetrain_list = []with open(filepath, 'r') as f:for line in f:if six.PY2:tokenize_words = tokenizer.tokenize(line.decode('utf-8').strip())else:tokenize_words = tokenizer.tokenize(line.strip())lower_words = [word.lower() for word in tokenize_words]for word in lower_words:train_list.append(word_index.get(word, 0))train_x.append(train_list)return train_x, train_yif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-trd', '--train_dir', type=str, nargs='?',default='./data/aclImdb/train/',help='train data directory')parser.add_argument('-ted', '--test_dir', type=str, nargs='?',default='./data/aclImdb/test/',help='test data directory')parser.add_argument('-wip', '--word_index_path', type=str, nargs='?',default='./data/aclimdb_word_index.json',help='aclimdb word index json')parser.add_argument('-onz', '--output_npz', type=str, nargs='?',default='./data/aclimdb.npz',help='output npz')args = parser.parse_args()train_dir = args.train_dirtest_dir = args.test_dirword_index_path = args.word_index_pathoutput_npz = args.output_npzword_index = get_word_index(word_index_path)train_x, train_y = build_data_index(train_dir, word_index)test_x, test_y = build_data_index(test_dir, word_index)np.savez(output_npz,x_train=np.asarray(train_x),y_train=np.asarray(train_y),x_test=np.asarray(test_x),y_test=np.asarray(test_y))
运行这个脚本 python build_data_index.py 之后会在data目录下生成一个 aclimdb.npz 文件,这个文件和官方imdb.npz的结构是一致的,这里就不展开了。
到目前为止,两份数据已经准备的差不多了,但是Kereas官方提供的 imdb.py 貌似不支持指定本地文件路径,所以这里模仿 imdb.py 脚本写了一个简化版的 aclimdb.py , 用来支持上述两个本地文件调用:
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author: TextMiner (textminer@foxmail.com)# Copyright 2018 @ AINLPfrom __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport jsonimport numpy as npdef get_word_index(path='./data/aclimdb_word_index.json'):with open(path) as f:return json.load(f)def load_data(path='./data/aclimdb.npz', num_words=None, skip_top=0,seed=113, start_char=1, oov_char=2, index_from=3):"""A simplify version of the origin imdb.py load_data functionhttps://github.com/keras-team/keras/blob/master/keras/datasets/imdb.py"""with np.load(path) as f:x_train, labels_train = f['x_train'], f['y_train']x_test, labels_test = f['x_test'], f['y_test']np.random.seed(seed)indices = np.arange(len(x_train))np.random.shuffle(indices)x_train = x_train[indices]labels_train = labels_train[indices]indices = np.arange(len(x_test))np.random.shuffle(indices)x_test = x_test[indices]labels_test = labels_test[indices]xs = np.concatenate([x_train, x_test])labels = np.concatenate([labels_train, labels_test])if start_char is not None:xs = [[start_char] + [w + index_from for w in x] for x in xs]elif index_from:xs = [[w + index_from for w in x] for x in xs]if not num_words:num_words = max([max(x) for x in xs])# 0 (padding), 1 (start), 2(OOV)if oov_char is not None:xs = [[w if (skip_top <= w < num_words) else oov_char for w in x]for x in xs]else:xs = [[w for w in x if skip_top <= w < num_words]for x in xs]idx = len(x_train)x_train, y_train = np.array(xs[:idx]), np.array(labels[:idx])x_test, y_test = np.array(xs[idx:]), np.array(labels[idx:])return (x_train, y_train), (x_test, y_test)
现在,可以按《Python深度学习》书中第3.4节的流程来快速过一遍我们自己处理的数据了,这里测试的环境是Mac OS, Python 2.7, Keras 2.14, Tensorflow 1.6.0, CPU环境,这个模型训练无需GUP也很快,请注意在上述几个代码存放的目录执行相关代码:
In [1]: import aclimdb# 注意,代码里已经写了数据文件aclimdb.npz的相对路径,如果在其他位置运行,请加上参数pathIn [2]: (train_data, train_labels), (test_data, test_labels) = aclimdb.load_data(num_words=10000)In [3]: train_data[0]Out[3]:[1,7799,1459,...11,13,3320,2]In [4]: train_labels[0]Out[4]: 0In [5]: max([max(sequence) for sequence in train_data])Out[5]: 9999In [6]: word_index = aclimdb.get_word_index()In [8]: reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])In [9]: decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])In [10]: decoded_reviewOut[10]: u'? hi folks < br / > < br / > forget about that movie . john c. should be ashamed that he appears as executive producer in the ? bon ? has never been and will never be an actor and the fx are a joke . < br / > < br / > the first vampires was good ... and it was the only vampires . this thing here just wears the same name . < br / > < br / > just a waste of time thinks ... < br / > < br / > jake ?'In [11]: import numpy as npIn [13]: def vectorize_sequences(sequences, dimension=10000):...: results = np.zeros((len(sequences), dimension))...: for i, sequence in enumerate(sequences):...: results[i, sequence] = 1...: return results...:In [14]: x_train = vectorize_sequences(train_data)In [15]: x_test = vectorize_sequences(test_data)In [16]: x_train[0]Out[16]: array([0., 1., 1., ..., 0., 0., 0.])In [17]: y_train = np.asarray(train_labels).astype('float32')In [18]: y_test = np.asarray(test_labels).astype('float32')In [19]: from keras import modelsUsing TensorFlow backend.In [20]: from keras import layersIn [21]: model = models.Sequential()In [22]: model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))In [23]: model.add(layers.Dense(16, activation='relu'))In [24]: model.add(layers.Dense(1, activation='sigmoid'))In [25]: model.compile(optimizer='rmsprop',...: loss='binary_crossentropy',...: metrics=['accuracy'])In [26]: model.fit(x_train, y_train, epochs=4, batch_size=512)Epoch 1/425000/25000 [==============================] - 3s 140us/step - loss: 0.4544 - acc: 0.8192Epoch 2/425000/25000 [==============================] - 2s 93us/step - loss: 0.2632 - acc: 0.9077Epoch 3/425000/25000 [==============================] - 2s 92us/step - loss: 0.2053 - acc: 0.9244Epoch 4/425000/25000 [==============================] - 2s 92us/step - loss: 0.1708 - acc: 0.9388Out[26]: <keras.callbacks.History at 0x206cfdc10>In [27]: resuls = model.evaluate(x_test, y_test)25000/25000 [==============================] - 4s 145us/stepIn [28]: resulsOut[28]: [0.2953770682477951, 0.88304]In [29]: model.predict(x_test)Out[29]:array([[9.9612302e-01],[9.5416462e-01],[1.5807265e-05],...,[9.9868757e-01],[8.4713501e-01],[5.7828808e-01]], dtype=float32)
详细的细节请参考《Python深度学习》,无论英文版还是中文翻译版都写得比较清楚,这里就不做补充了。最后,欢迎大家关注我们的github项目: AINLP (https://github.com/panyang/AINLP),预期配套这个系列相关的文章和教程,欢迎大家关注,也欢迎大家关注我们的微信号: AINLP,有问题随时反馈和交流:






