AI综述专栏|跨领域推荐系统文献综述(下)
AI综述专栏简介
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
导读
跨领域推荐系统(Cross domain recommender systems,CDRS)能够通过源领域的信息对目标领域进行辅助推荐,CDRS由三个基本要素构成:领域(domain),用户-项目重叠场景(user-item overlap scenarios)和推荐任务(recommendation tasks)。这篇研究的目的就是明确几种广泛使用的CDRS三要素的定义,确定它们之间的通用特征,在已明确的定义框架下对研究进行分类,根据算法类型将同类研究进行组合,阐述现存的问题,推荐CDRS未来的研究方向。文章分为上、下两部分,本篇为“下篇”。
「关注本公众号,回复"CDRS",获取英文版PDF」
五 结果
本节回答了四.1节提出的问题。具体分为四个部分,第一部分是总结了各CDRS三要素定义的共通点,第二部分根据分类坐标系对一级研究进行了分类,第三部分强调了一些当前CDRS使用的算法,第四部分指出了未来发展趋势。
每个部分都使用了跨案例分析方法[Milesand Huberman 1994]去综合分析结果,跨案例分析方法包括了各种不同的表现方式,如图表等方式,通过密集编码的形式,在不破坏原有意思的情况下,对已经确定的数据进行管理和表示。在文本中,我们使用标签法对数据进行编码,我们的数据就是一级研究,我们使用跨案例分析方法设计分类指标,对一级研究进行分类和组合。
1 RQ1:DRS三要素的定义去如何扩展才能够将大量的一级研究进行分类?
这个研究问题主要指向如何确定不同CDRS三要素定义之间的共同特征。首先,领域定义的共同点已经提到了。第二,类域也已被提出,作为Ivan提出的属性等级、项目类型等级和项目等级的定义的补充。第三,用户-项目重叠场景根据候选文献的标准进行选择。第四,推荐任务通过候选文献提出的定义进行定义。总的来说,提出的定义集已被使用于生成分类坐标系,使用分类坐标系对一级研究进行的分类将会在后面的章节讨论。
·领域
图6简化了领域定义,图中显示了在Li[2011]和Ivan[2015]的研究中系统领域定义的共同点。Ivan关于项目属性的定义被组合成一个领域,即类域,这样做很有用,因为Ivan的定义使用项目的属性和类型进行区分,没有指定区分需要的属性的数量,属性的数量对于区分项目属性等级和项目类型等级是很有必要的。
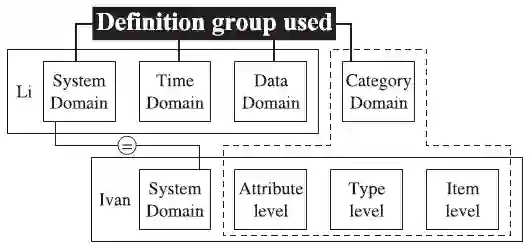
图6 使用的领域定义
类域:推荐系统的项目可以根据在单领域中项目的属性或者类型被分组。因此,每个属性或者类型都可以认为是一种不同的类。当进行推荐时,信息从不同的类之间进行转移,这被认为是类域的迁移,例如:
-Hu etal. [2013a] 和 Loni et al. [2014]在AMAZON中的书籍、CD、DVD和VHS之间完成了信息迁移
-Tanget al. [2012] 和 Shapira et al. [2013] 在Facebook中的音乐、电影、电视节目、书籍之间完成了信息迁移。
-Berkovskyet al. [2007] 和 Nakatsuji et al. [2010]在EachMovies的不同项目之间完成了信息迁移。
·用户-项目重叠场景
对于用户-项目重叠场景,Cremonesiet al. [2011]提出的定义现在已经被主流的研究所接受,因此,本文也使用他们对一级研究分类的定义。
·推荐任务
推荐任务由Cremonesi et al.[2011]提出,Fernandez-Tobias et al. [2012]和Ivan Cantador[2015]虽然对其有不同的定义方式,但是表达的概念都比较相似。为简单起见,我们创建了三种推荐任务,如表7所示。每种类型为Cremonesi、Fernandez-Tobias和Ivan Cantador提出的推荐任务提供了明确的解释。
表7 推荐任务比较
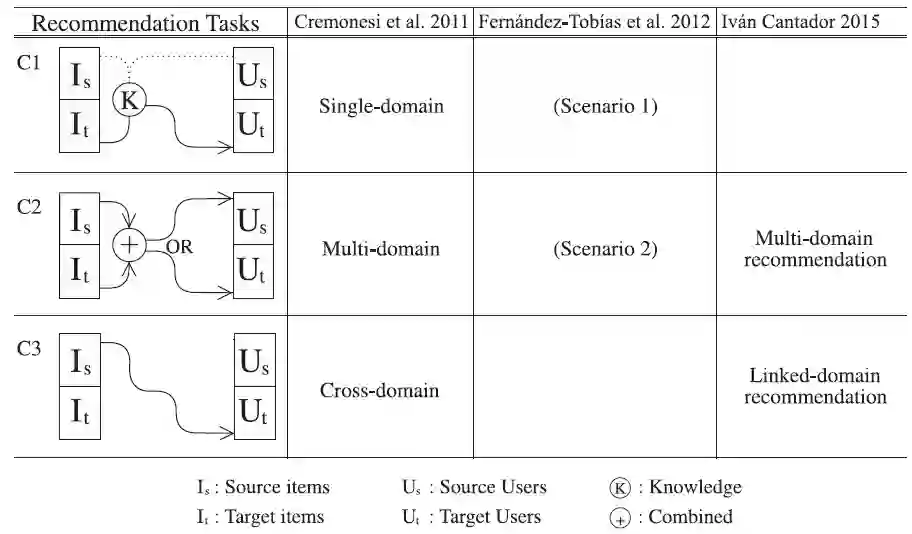
C1:单任务领域推荐。通过从其它领域获取到的信息,将一个领域的项目推荐给各自领域的用户。这种场景和单领域推荐很相似,Cremonesi et al. [2011]和Fernandez-Tobias etal. [2012]分别描述了推荐质量改善的场景。
C2:组合推荐。将物品推荐给某两个领域或其中之一领域的用户的过程中,两个领域对推荐都做出贡献。这种场景和Cremonesi et al. [2011]、Ivan Cantador[2015]和Fernandez-Tobiaset al. [2012] 描述的多领域推荐和相邻用户-项目重叠推荐场景非常相似。
C3:跨领域推荐。根据从两个领域的用户和项目之间收集到的信息,将其中一个领域的项目推荐给其他领域的用户。这种场景和Cremonesi et al. [2011]和Ivan Cantador[2015]描述的相关领域推荐和跨领域推荐很相似。
总结
本节回答了提出的第一个研究问题。首先区分了领域之间的相似性,提出了类域,然后讨论了推荐场景,最后,对推荐任务进行了组合,下一节中将根据此组合对一级研究进行分类。
2 RQ2:在大部分相关推荐场景的构建都是基于领域差异、推荐场景和推荐任务的情况下,跨领域推荐系统研究中这些场景所占比率是怎么样的?
跨领域推荐系统的研究立足于三个基本要素,即领域信息转移,用户项目重叠和推荐生成(推荐任务)。此问题的目的是正确的定位一级研究在分类坐标系中的位置。对一级研究进行分类时,“用户-项目”重叠被认为在包含多领域和推荐任务的文献中具有共同之处。因此,为了更方便的在坐标图中表示研究,我们设置了两种变化形式:
-领域vs用户-项目重叠场景坐标图
-推荐任务vs用户-项目重叠场景坐标图
(1)领域vs用户-项目重叠场景坐标图
共有86篇文献被用于绘制领域vs用户-项目重叠场景坐标图,根据它们的文献ID,将这些研究在表8中列出,具体如图7所示。
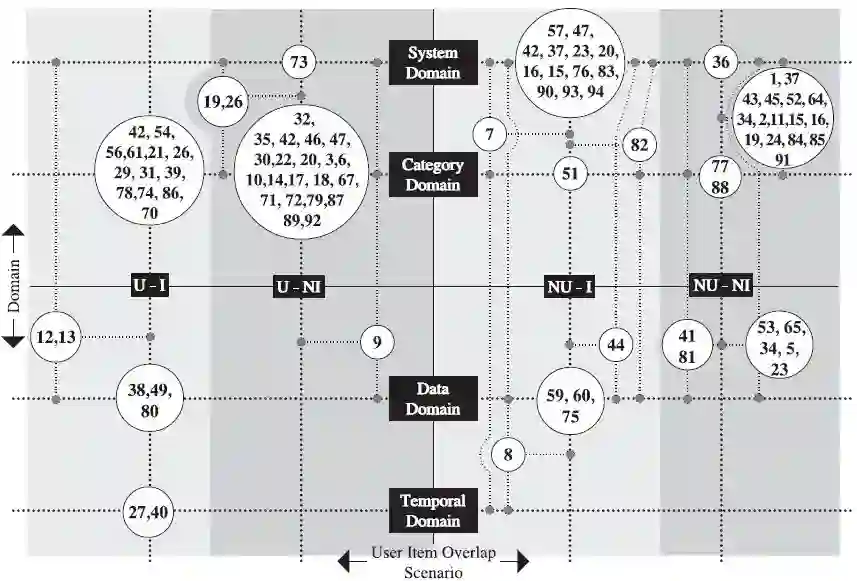
图7 领域vs用户-项目重叠场景坐标图
坐标图描述:横轴为用户-项目重叠场景。“用户-项目”,“用户-无项目”处于左象限,“无用户-项目”,“无用户-无项目”处于右象限。类似的,在纵轴上,系统和类域处于上象限,数据和时间域处于下象限,此坐标图中没有负值,每个地方都是由文献ID组成的。坐标图中的虚线表示各轴元素间的联系。水平的虚线表示与领域有联系,垂直的虚线表示与用户-项目重叠场景有联系。
简单观察坐标图中的圆,能发现两个结论,第一,圆总是存在于两个虚线的交汇处。如在左下方,一个包含两篇文献的圆(27,40)存在于“用户-项目重叠”和“时间域”虚线的交汇处,这意味着这些一级研究的都是根据时域的变化将源领域的信息转移到目标领域,而且在两个领域中它们都有相同的用户和项目。
第二,圆总是存在于通过窄虚线连接到领域和用户-项目重叠的虚线的方块中。在坐标图中,有10个圆处于方块中,它们可以分为两类,第一类包括连接到两个领域和一条用户-项目重叠虚线(例如左上角包含(19.26)的圆分别连接到系统域、类域和用户-无项目重叠)的圆。第二类包括连接到三个领域和一条用户-项目重列虚线((8)这个圆连接到数据域、时间域、系统域和无用户-项目重叠)。
连接到两个领域的圆表示涉及保持用户-项目重叠相同的情况下两个领域之间的信息转移,类似的,连接到三个领域的圆表示三个领域之间的信息转移。
综上:
开放研究贡献:单领域vs用户-项目重叠
目前尚无研究是关于以下几种场景的:系统领域vs用户-项目重叠;数据领域vs用户-无项目重叠及无用户-无项目重叠;时间领域和用户-无项目重叠;无用户-项目和无用户-无项目重叠如图8(A)所示,Fernandez-Tobıas强调它的原因是这个研究趋势一般没有合适的数据集。事实上,由相同数据源分出来的人工数据被一些研究者用来在不同的领域场景都进行过实验,比如Berkovsky et al. [2008], Winoto and Tang[2008], 以及Zhang etal. [2012]。
开放研究贡献:多领域和用户-项目重叠
某些研究完成了两个领域之间信息的转移,还有少部分完成三个领域的。更多领域之间信息转移受到阻碍的主要原因是算法的复杂度过高。当然,这个方向上也有许多的组合可以拿来研究。
图8(B)是涉及不同领域数时不同重叠方案之间的比较,单领域场景非常多,三领域重叠方案最少
成熟的方案
由于从入选的一级研究中获得了最大权重,领域vs用户-项目重叠场景被认为是成熟的方案。对于某个单领域有贡献的一级研究被用于计算整个领域的贡献。根据这一准则,37篇文献讨论过类域,所占比重最高,只有两篇文献讨论过时域,所占比重最低。图8(C)为所有领域的权重。
在用户-项目重叠比较的例子中,所有的场景的参与程度都被认为是相近的,具体见图8(D)。

图8 领域vs用户-项目重叠方向一级研究分析
(2)推荐任务vs用户-项目重叠场景坐标图
共有65篇文献都被用于绘制推荐任务vs用户-项目重叠场景坐标图,根据它们的文献ID,将这些文献在表8中列出,具体如图9所示。
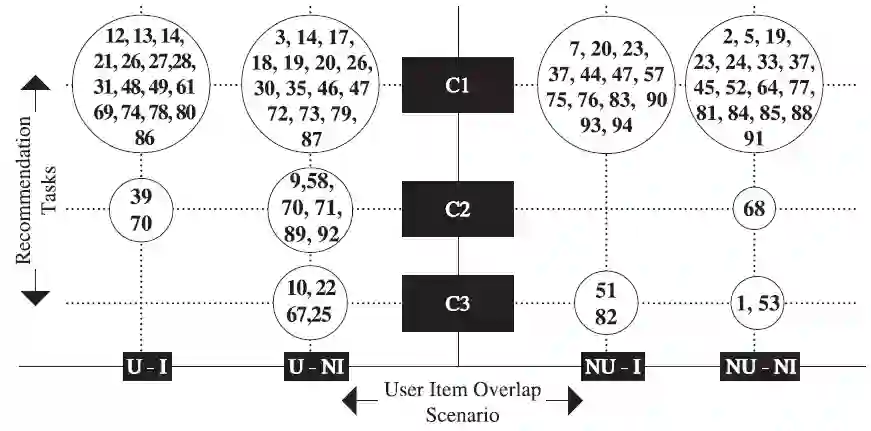
图9 推荐任务vs用户-项目重叠场景坐标图
坐标图描述:横轴为用户-项目重叠场景。“用户-项目”,“用户-无项目”处于左象限,“无用户-项目”,“无用户-无项目”处于右象限。纵轴代表推荐任务,和前面类似,此坐标图中没有负值,表格中的圆包含代表文献ID的一级研究。
综上:
开放研究贡献:C2,C3
在所有的推荐任务中,单领域推荐(C1)提供了主要的贡献,然后是联合推荐(C2),最后是跨领域推荐(C3)。收集的一级研究表明,跨领域推荐(C3)的相互作用,用户-项目重叠和联合推荐(C2),以及无用户-项目重叠还处于研究空白。每种推荐任务所占比例如图10(A)所示。
对于所有推荐任务-用户项目重叠场景,用户-无项目重叠场景所占比重最大,无用户-项目重叠场景所占比重最小,只有20%,具体信息如图10(B)。
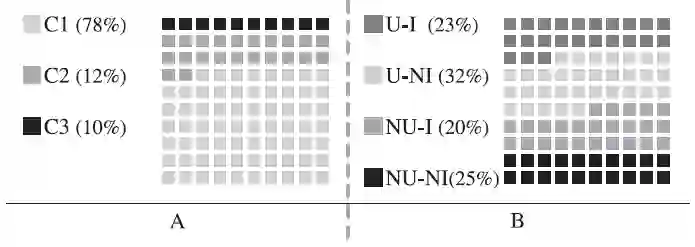
图10 推荐任务vs用户-项目重叠方向一级研究分析
总结:
本节根据领域vs用户-项目重叠场景和推荐任务vs用户-项目重叠场景将CDRS的一级研究进行了分类。分类的结果指出了CDRS目前已经成熟的研究方向和缺乏关注的研究方向。
3 RQ3:目前CDRS主流的技术方法和分析算法
CDRS目前使用的算法可以被分成7类:聚类、语义分析、基于图的算法、概率分布、因式分解、基于标签关联的方法和其它。为了进一步理解每类算法,下一节中将会逐一举例说明。
(1)算法
聚类:CDRS方向最先提出聚类算法的是Morenoet al. [2012]。他们设计的算法能够根据用户和具有相同评分模式的物品对源领域进行聚类。然后将整个类转移到目标领域,并且能够根据相似的用户和项目进行扩展。其它研究聚类算法在CDRS上的应用的还有Chen et al. [2013],Wang et al. [2012], Gao et al. [2013b], Yi et al.[2015], Li et al. [2009],Berkovsky et al. [2007], Li et al. [2016], Tang et al.[2013], Li et al. [2011], and Li et al.[2016]。
语义分析:基于语义分析的方法来自于知识工程和本体论,主要思想是根据源领域中的知识生成知识图谱,并将其转移到目标领域中,根据目标领域中的评分对项目进行分类。研究此类算法在CDRS上的应用的有Moe and Aung [2014a],以及Kumar et al. [2014b]。
基于图的方法:基于图的方法尝试去建立源领域中用户和项目的联系,进而在目标领域中相似的用户和项目之间也建立联系。研究此类算法在CDRS上的应用的有Jiang et al. [2012], Shapira et al. [2013], Iwata and Takeuchi[2015], Biadsy et al. [2013], Guo and Chen [2014], 以及 Nakatsujiet al. [2010]。
概率分布:概率分布主要面向于两个领域之间表征相似的项目,此种方法尝试根据源领域中的所有用户去学习每个项目的概率,寻找到合适的推荐分数。一旦学习成功,就将信息转移到目标领域中。使用概率分布的文献有Aizenberg et al. [2012], Ren et al. [2015], and Lu et al. [2013]。
因式分解:尝试去将源评分矩阵分解为一对特征矩阵,以此能更好的和目标评分矩阵组合,补全没有的评分。研究此类算法在CDRS上的应用的有Shi et al.[2011], [Hu et al. 2013a], Huang et al. [2012], Gao et al.[2013b], Xin et al. [2014], Zhao et al. [2013], Loni et al. [2014], Shi et al.[2013a], Pan et al. [2012], Pan and Yang [2013], Shi et al. [2013b], Jing etal. [2014], Pan et al. [2015a], and Pan et al. [2015b]。
基于标签关联的方法:指根据源领域用户和项目的标签建立标签关联,对用户和项目进行组合。同时关联源领域和目标领域已定义标签,据此共享评分矩阵。Dong and Zhao [2012], Yang et al. [2014], Guo and Chen [2013b], 以及Moe andAung [2014b] 等文献通过此方法将源领域的信息转移到目标领域。
其他:包括研究领域之间信息迁移的其它文献,此处举例都是有明确应用的,因此,有些技术并未提及。
文献需要使用一定的分析技术去衡量提及的算法的优劣程度,本文同时也对CDRS研究中使用的分析技术进行了阐述。从72篇进入备选范围的一级研究中提取出分析技术,并对其进行组合,最终形成三组评价指标,即分类指标,预测指标,排名指标。分类指标被用于衡量算法根据一定规则对正负样本正确分类的能力,预测指标和分类指标相似,主要用于能够在每次迭代中进行算法的改进。预测指标统计算法的结果和真实值之间的误差的数量。排名指标通常用于衡量两个已排名物品列表之间的相似程度。共找到了16种分析技术,其中3种对涉及分类指标,3种涉及预测指标,9种涉及排名指标。图11为算法和分析指标关系。
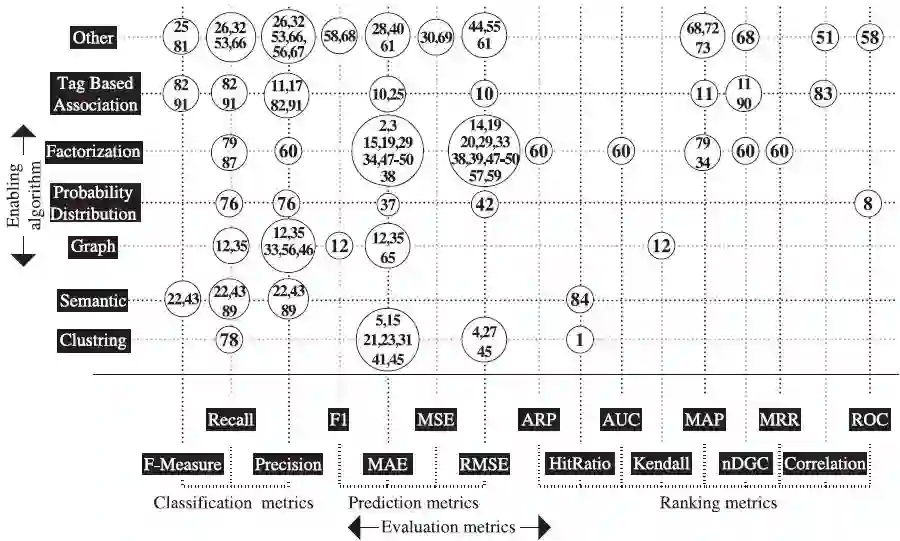
图11 算法和分析指标
坐标图描述:为了能够更好的比较算法,将所有的一级研究放在坐标图中,坐标图的y轴是各类算法,x周是分析指标,如图11所示。分析指标被分为三类,即分类指标,预测指标,排名指标。此坐标图中的圆为表8列出的一级研究的文献ID。圆在虚线的交界处,虚线表示算法或者分析指标。
总结:
从图12(A)中可以看出,研究主要集中于因式分解,基于图的方法和聚类方法。从图12(B)中可以看出最常用的分析指标为预测指标,其次是分类指标,最后是排名指标。
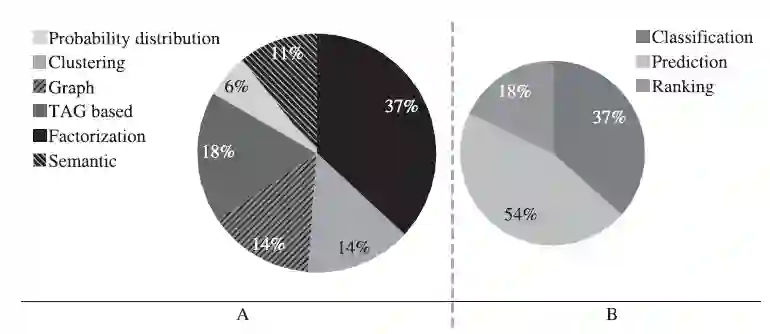
图12 涉及各算法和分析指标的研究分布
(2)使用的数据集
在收集算法和分析指标的同时,数据集信息同样被收集,MovieLens数据集被使用次数最多,有23篇文献使用,占总数的22%,接下来是Netflix,有11篇文献使用。此外,还有很多其它公共数据集被使用,如图13所示,其中4篇文献使用了自己的数据。总之,进入备选范围的一级研究中共使用了29个数据集,大多数研究者只关注最流行的数据集。
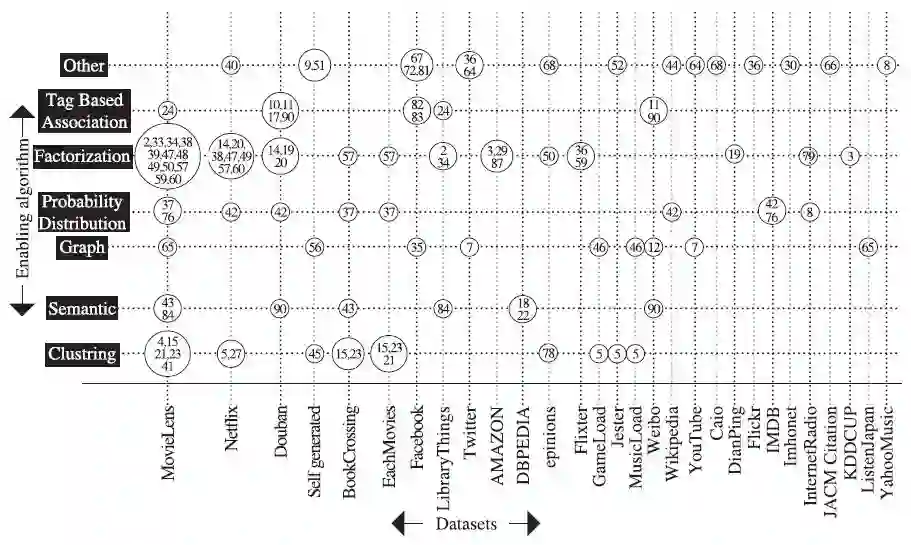
图13 数据集分布
总结:
本节首先根据分析指标对所有算法和其所属的一级研究进行分析,分析指标能够帮助CDRS将源领域的信息转移到目标领域中。其次,本节也根据使用的算法对一级研究使用的数据集进行了分析。
4 RQ4:现有的方法能够解决什么研究问题,并应用于未来的研究中?
(1)问题
跨领域推荐系统尝试通过领域间信息转移的方法解决传统的推荐系统问题。本节讨论以下几个方面,一是传统推荐系统已经能解决的问题,二是CDRS方面尝试解决传统推荐系统存在问题的研究,三是CDRS遇到的问题。
传统推荐系统解决的问题:
传统推荐系统研究尝试改善准确率和与其它系统的差异性,Ricci et al. [2011]列出了推荐系统最热门的研究问题,作为图14中的x轴,这些问题中的一部分与推荐系统的数量正相关,如准确率,独立性和差异性等等,一些特性逆相关,如稀疏性,覆盖率,冷启动等,图14中的绿色箭头表示单独的问题和推荐系统数量之间的关系。
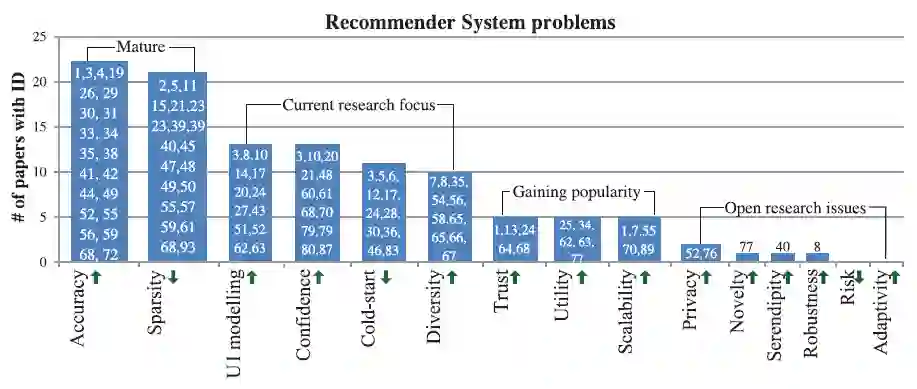
图14 推荐系统问题跨领域解决方法
CDRS方面尝试解决传统推荐系统存在问题的研究:
跨领域推荐系统旨在解决现存的推荐系统问题。现存的推荐系统的问题根据收集的一级研究被分成4类:如图14所示。第一类问题是关于准确率和稀疏性的,这类问题被认为是“成熟”的,因为研究其的文献非常多;第二类问题是关于用户-项目模型,独立性和覆盖率的,这类问题属于“前沿研究关注”,因为目前大部分研究都着眼于这些问题;第三类问题是关于信任度,实用性和可扩展性的,这类问题属于“正在获得关注”,包括的问题正在被研究,取得的进展较少;第四类问题是关于隐私问题,惊喜度,意外性,鲁棒性,风险和适应性的,这类问题属于“开放性研究问题”,在这些方面的研究几乎还是空白。
CDRS面临的问题:
五.2中强调,跨领域推荐系统缺乏合适的数据集用于多重推荐场景和任务。这使得此方面的探究迫切的需要能够兼容独立推荐场景的数据。某些研究者提出了一些新的数据集,如Dooms et al.[2013]使用的MovieTweetings,也有一些人尝试在某些假设成立的情况下使用现有的数据集。
CDRS遇到的另一个问题是基于语境的推荐,大部分时间里,向目标领域辅助推荐的源领域会带来新的信息,这些额外的信息是和共享信息相关的元数据,因此被称为是语境。语境可以扮演领域;然而,它没有被定义,关于这方面的一级研究仍然处于初始阶段,此阶段中可能会不适合使用其作为一个领域。使用其作为语境的一些研究有Fernandez-Tobias et al. [2011], Roy et al. [2012a], and Cao et al.[2015]。
(2)未来研究方向
CDRS未来的研究方向可以被分成5类:分别是领域相似性提升,算法改善,使用大数据作为源领域,传统推荐系统问题和数据集扩展。下面细说明这5类研究方向:
·领域相似性提升: 现有的跨领域推荐系统技术依赖于参与领域之间的相似性,研究者通常根据以下方法来寻找提升领域相似性的方法。
a. 析异构数据:用户的相互行为存在于不同的数据类型中,如喜欢-不喜欢,播放音乐,数字评分等。这表明在CDRS中,异构数据转移将会是一个非常有潜力的研究方向。
b. 分析用户兴趣转移: 用户兴趣随时处于变化之中,因此,为了能随时根据用户兴趣生成新的推荐,可以根据时间对用户行为进行分析。这种特殊的场景和时域跨领域推荐有关,Hu et al. [2013a]申明他们将持续研究相关内容。
c. 包括相关领域: 多位研究者都将其实验的扩展部分作为其未来研究方向。在这个方向上,他们打算使用不止一个源领域,在多个领域上进行实验,或者分析多个领域以找出究竟哪个领域能够提供最精确的结果。
d. 语境增强: 研究者们发现源领域往往包含和目标领域上相同的用户和项目有关的附加属性[Roy et al. 2012b; Kaminskas 2009; Shi et al. 2013a; Shapira et al.2013; Tang et al. 2011; Roy et al. 2012a; Hoxha et al. 2013]。这些属性能够增强用户或者项目的语境,进而生成效果更好的推荐。
·算法改善: 领域的相似性可以通过改善使用的算法进行提高,因此,研究者会在未来的研究中努力改进跨领域推荐生成算法[Moreno et al. 2012; hang et al. 2012; Li et al. 2016; Kumar et al.2014a; Cao et al. 2015]
·使用大数据作为源领域: 使用大数据作为源领域有三个可行的研究方向,分别是:
a. 大数据作为源领域:根据Roy et al.[2012b], Aizenberg et al. [2012], Yan et al. [2013], 以及 Lu et al.[2013] 等研究的建议,跨领域推荐系统可以使用大数据服务去调整目标领域的推荐。通过人口统计或者其他统计信息获得的大数据能够帮助对跟人进行推荐。
b. 分布式实现:研究者通过使用分布式算法去提升跨领域推荐的效果,分布式算法能够根据需求调整规模,Su et al. [2010]提出了此研究方向。
c. 利用社交媒体:社交媒体包括面对各种不同项目的用户行为,这些行为的大部分都是可以获得的,他们广泛的存在于Facebook, twitter, LinkedIn等网站。研究者强调了社交媒体用户行为是一个能够改善目标领域推荐效果的潜在源领域[Zhao et al. 2013; Pan and Ming 2014; Xu et al. 2011a; Tang et al.2013; Pan et al. 2012; Dong and Zhao 2012; Fern´andez-Tob´ıas et al. 2011],最近,Khan etal. [2016]验证了Facebook上的用户行为在外部推荐系统上的应用,这是社交网络数据的首次应用。
·传统推荐系统问题: 传统推荐算法的问题是由Ricciet al. [2011]提出的,这部分和CDRS的关系不大。
a. 风险: 由Ricci et al. [2011]描述,风险和由于不正确或不适合推荐导致的用户丢失有关。CDRS可以通过使用其它领域的用户评价观点来协助,从而降低推荐风险。
b. 适应性: 适应性和随时变化的用户兴趣有关。CDRS能够在某个时间段内将源领域的信息进行转移,从而改善适应性。基于时间的CDRS推荐不仅能够帮助改善适应性,还能改善惊喜度和新颖性。
c. 棒性: 鲁棒性的定义为,当存在虚假评分时,能够避免推荐的能力。CDRS能够通过从超过一个领域中提取出的信息进行的信息转移协助改善鲁棒性,从而减少使用虚假评分的概率。
d. 惊喜度: 惊喜度的定义为,推荐系统推荐的物品是否是用户没有见过或不知道的。CDRS能够将源领域中和用户感兴趣的物品相似但用户不知道的物品推荐给用户。
e. 隐私问题: 隐私和是否能够识别喜欢相似物品的用户的身份或者目标用户有关。CDRS推荐不会遇到隐私问题,因为推荐是在多个不同的系统领域之间进行的,没有哪个系统能够保证自己的用户的其他系统的相似。为了使CDRS推荐包含各系统领域,CDRS中使用的算法一般都不直接将源领域的评分映射到目标领域,取而代之的是提供用户的信息。
·数据集兼容:跨领域推荐系统依赖于数据集进行推荐辅助;现存的数据集都是为了传统的推荐系统创建的,这使得CDRS的研究者能够自由的使用这些数据集,有时候CDRS研究者也将这些数据集用于本来不是这些数据集生成的场景。例如,Pan and Yang [2013]将Movie-Lens数据集用于数字和0/1评分中,他们还通过阈值法将数字评分转化为0/1形式,用于模仿喜欢/不喜欢行为。尽管能够使用现成的算法对数据进行转化,但是往往转化的结果不能匹配真实的场景,数据集的不兼容性能够在未来的研究中通过以下方法得到改善:
a. 新数据集:指创建新的数据集并根据相应的领域、推荐场景或推荐任务对其进行分类。尽管这是可行的,但是可能要花大量的时间。
b. 现有数据集:将现有的数据用在CDRS上,当将现有的数据集用在具有某个特定领域、某个推荐场景或者某个推荐任务的方案中时,需要标准化使用条件,并且考虑限制条件。
总结:
本节总结了CDRS能够解决的传统推荐存在的问题。同时,也对CDRS面临的问题进行了讨论,最后,将CDRS未来的研究方向分成了五大类。
六 不足之处
本文献综述试图对跨领域推荐系统的相关一级研究进行比较和分类,相关的二级研究有一些潜在的限制,然而,系统文献综述总的来说是值得去做的。预期的不足之处主要存在于一级研究的识别和选择,数据提取不充足和未完成的结果这几方面。
1 一级研究的识别和选择的不足之处
为了能够对CDRS进行更深入的了解,我们尝试去收集尽可能多的一级研究,从收集的研究中提取出尽可能多的跨领域推荐场景,力争避免偏差,我们遇到的另一个挑战是改变领域和推荐任务的定义。
为了避免偏差,确保覆盖到所有的实验结果,我们使用通用的关键词法对现有的二级研究进行选择,构建搜索字符串,搜索字符串的使用使得4.2中提到的研究指数服务更加有说服力。这一做法在减少偏差的同时,也能够显著增加识别的任务数量。
分类标准被设计用于正确挑选和分类尽可能多的一级研究。需要分析的文献多达94篇,所以我们的方法还是不能像有些系统文献综述那样为每篇文献提供相对质量评分。相反,我们使用了标签法去收集所有的一级研究并对其进行相同的分析。
2 数据提取的不足之处
尽管我们已经尽可能多的收集了数据,但是根据我们观点仍然还有新的研究问题被不断提出。读者有可能找出本文所没有考虑到的一些问题并对研究趋势做出更好的分析。数据提取的另一个不足之处是没有利用质量评分。质量评分能够帮助优先考虑结果的输出和研究趋势。同时,为了简短和准确的说明问题,某些包括多重CDRS研究场景的文献被简化成只有一个有效场景了。
3 综合结果的不足之处
一级研究的质量评分能够产生更好的综合结果。然而,我们的目标是通过对一级研究进行分析,根据通用的标签对CDRS的研究进行可视化,尽可能的使读者能够理解分析过程。为了完成这一目标,所有一级研究被标注,领域场景被划分到分类坐标系中,用于提取出当前研究的趋势。我们认为更深一步的领域场景之间的数据集联系和研究问题之间的关系不大,但是仍然能够对CDRS提供比较好的理解。下一节中我们将对全文进行总结,并提出未来的展望。
七 结论
本文的目的是明确普遍认可的CDRS三个基本要素的定义,对当前CDRS研究在已定义三要素的框架之下进行分类和可视化,同时,根据算法的类型和现有的问题对CDRS研究进行组合,提出CDRS未来的发展方向。为了完成这些提到的目标,我们使用了一系列系统文献综述方法,对相关文献进行收集,尽量减少偏差,同时公开过程和结果,接受批评。
根据系统文献综述的准则,我们提出了两个研究问题,即本文做出两个贡献,第一个是通过将普遍认可的领域、用户-项目重叠场景和推荐任务的定义进行重组,确定CDRS三要素的定义,并尝试根据三要素去理清CDRS研究的混乱之处。第二是将所有进入备选范围的一级研究进行重新分类,构建坐标图,指明CDRS研究的趋势。
尽管本文尝试去解决提出的问题,但是仍然还有一些地方没有涉及到。本文在四.6节中指出CDRS目前的研究势头非常猛,在未来的文献研究中,有效的CDRS工具包将会给新的研究者提供更有用的信息。同时,能够看到数据集和CDRS三要素共同作用下,正确识别出某个特定场景下数据集的特征也是非常有趣的。
总的来说,随着CDRS的发展,我们相信总有一天CDRS的三个基本要素的定义会被标准化,也逐渐会有专用的工具包,为提升CDRS的效果提供巨大的帮助。
扫描下方二维码加入跨领域推荐系统述讨论群

感谢内容伙伴雷智文推荐并翻译本文
内容伙伴持续招募中,有意者联系微信号"前沿讲习班小助手(ID:must-tech)"

历史文章推荐:
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI



