推荐系统“始祖”亚马逊:回顾个性化推荐20年变迁之路
在过去的近二十年里,Amazon.com 为每个客户构建了一个定制化的网上商店。当每个用户浏览 Amazon.com 网站时,仿佛走进了一个为自己量身打造的商店,那些自己感兴趣的商品会被自动移动到前面,而不太感兴趣的商品则被移动到远处。Amazon.com 的推荐系统根据你当前的情况以及浏览、购买等历史,从上亿个项目中选出你可能会喜欢的少量商品。
Amazon.com 在 1998 年推出了基于项目的协同过滤算法(item-based collaborative filtering),使推荐系统能够基于上百万的商品目录为数百万用户提供推荐服务。2003 年,Greg Linden、Brent Smith 和 Jeremy York 将该算法发表在“IEEE Internet Computing”杂志上,论文名称为“Amazon.com Recommendations: Item-to-Item Collaborative Filtering”。随后,该算法在网络上被广泛地使用在不同的产品中,包括 Youtube、Netflix 和很多其他产品。该算法的成功在于:简单、可扩展、能提供让人惊奇且有用的推荐、能根据用户的新信息快速地更新推荐结果以及能够以易于理解的方式解释推荐内容。
在过去的十多年中,该算法面临了很多挑战,也得到了很多改进。这里,该算法的其中两名原作者 Brent Smith 和 Greg Linden 将描述其中的一些更新、改进和修改,并对协同过滤、推荐系统和个性化的未来进行展望。
在 20 世纪 90 年代中期,协同过滤通常是基于用户的,也就是说算法的第一步是搜索其他用户以查找具有类似兴趣(例如类似的购买模式)的人,然后查看那些类似用户已经发现而你尚未发现的项目。基于项目的协同过滤算法与此相反,它首先对目录中的每个项目寻找相关项目。“相关”可以有好几种含义,但是在这里,我们把它定义为“购买一个物品的人非常有可能购买另一个物品”。所以,对于每个物品,相关物品是那些购买了的人频繁购买的项目。
一旦建立了这个相关项目表,我们就可以通过一系列的查询快速生成推荐。根据客户当前的浏览记录和以往的兴趣,对每一个项目,查询它的相关项目中那些未曾浏览过或购买过的项目作为最终的推荐列表。
与旧的基于用户的协同过滤相比,该算法有很多优点。最重要的是,大部分计算(如批量构建相关项目)是离线完成的,而通过查询而生成的推荐可以实时完成。这些推荐是高质量和有用的,特别是在给定足够数据的情况下,并且即使与过去二十年中出现的较新算法相比,它仍然在感知质量方面保持着竞争力。该算法可以扩展到数亿用户和数千万个项目,而无需采样或采用其他会降低推荐质量的技术。当个人兴趣有了新的信息时,该算法能立即更新。而且,它可以很直观地解释这些推荐结果,因为这是由客户所记住购买的项目列表引起的。
在 2003 年,当我们将该算法发表于 IEEE 时,基于项目的协同过滤已经广泛地部署在 Amazon.com 上。主页根据用户以前的购买记录和在商店浏览的商品,突出显示推荐结果。搜索结果页面推荐与用户搜索相关的项目。购物车推荐其他可添加到用户购物车的项目,也许用户在最后时刻会冲动地购买,也可能补充用户已经考虑过的商品。在订单结束时会出现更多的推荐,提示稍后可购买的商品。使用电子邮件、浏览页面、产品详细信息页面等许多页面上,Amazon.com 都会提供一些推荐内容,让用户开始接触商店。
还有不少公司也使用了该算法。2010 年,YouTube 报道使用它来推荐视频。许多开源代码和第三方供应商都包含了这个算法,它在网络零售、旅游、新闻、广告等方面都广泛出现。在以后的几年中,这些推荐结果被 Amazon.com 广泛使用,微软研究报告曾估计 Amazon.com 有 30%的网页浏览量来自于推荐。同样地,Netflix 也广泛应用推荐系统,他们的首席产品官 Neil Hunt 表示,Netflix 有 80%以上的电影观看都是通过推荐生成的,而且 Netflix 推荐系统每年产生的价值超过 10 亿美元。
当我们最初开发基于项目的协同过滤时,Amazon.com 主要是一个书店。此后,亚马逊的销售额已经增长了一百多倍,并扩张为以非媒介物品为主导,覆盖笔记本电脑到女性衣服等各种商品。这种增长挑战了我们原始算法中的许多假设,需要适应新的和不断变化的环境。基于过去的经验,我们还找到了改进算法的方法,为许多新应用程序提供更相关的推荐。
推荐结果的质量在很大程度上取决于对“相关”这一术语的定义。例如,假设用户已经购买了 X,如何定义该用户也“非常可能”购买项目 Y?当我们观察到客户购买了 X 和 Y 时,我们可能会想知道如果这两个项目是无关的,有多少购买了 X 的买家会随机购买 Y。推荐系统最终是统计学的应用。人的行为是带噪声的,而挑战就在于如何从随机性中发现有用的模式。
一种估计既购买 X 又购买 Y 的客户数量 Nxy 的自然方式是,假设 X 买家与一般人有着相同的购买 Y 的概率,P(Y)=|Y 买家|/|所有买家|,并用|X 买家|*P(Y) 作为我们对购买了 X 和 Y 的客户数量的期望值 Exy 的估计。我们发表于 2003 年的文章以及 2003 年以前的大部分工作,都使用了类似的计算。
然而,对于几乎任意两个项目 X 和 Y,购买 X 的客户都比一般人更有可能购买 Y。想像一个大手笔的买家购买了目录中的所有物品。 当我们寻找所有购买 X 的客户时,该客户一定会被选中。同样地,购买过 1,000 次的客户被选中的概率是购买过 20 次的客户的 50 倍;抽样随机购买不能给出选择客户的统一概率。所以我们得到一个有偏见的样本。对于任何项目 X,购买 X 的客户将可能比一般人多买其他项目。
这种非统一分布的客户购买历史分布意味着,当我们试图估计我们预期有多少 X 买家会随机购买 Y 时,我们不能忽略谁购买了 X。我们发现,建模中认为客户有很多机会购买 Y 是很有用的。例如,对于购买过 20 次的客户,我们认为这 20 次中的每一次都有独立购买 Y 的机会。
这里我们用更正式的语言来描述。对于购买 X 的给定客户 c(由 c∈X 表示),我们可以估计 c 购买 Y 的概率为
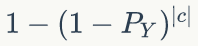
其中|c|表示 c 购买的非 X 物品的数量,Py=|Y 购买|/|所有购买| 或随机选择时购买 Y 商品的概率。然后,我们可以通过对所有 X 买家进行求和并使用二项式扩展来计算 X 买家中 Y 买家的预期数量(见图 1)。

图 1. 预期购买 X 和 Y 项目的客户数量的推算,包含每个 X 买家购买 Y 的可能性

我们还可以考虑其他一些选择和参数,用于相关性分数和从相关项目中创建推荐。我们的经验是,没有一个分数能在所有设置中都得到最好的成绩。最终,推荐结果好坏基于用户所感知的质量;用户认为有用的推荐才是真的有用。
机器学习和受控的在线实验可以了解客户的实际偏好,挑选最佳的参数以便具体使用推荐。我们不仅可以衡量哪些推荐是有效的,而且还可以提供关于人们所喜欢、点击和回馈到我们的算法中的那些推荐的信息,了解哪些帮助对客户最有效。
例如,兼容性很重要。我们可能会观察到,购买某一款数码相机的客户很有可能购买某种存储卡,但这并不能保证这种存储卡与该款相机兼容。客户购买存储卡的原因很多,而观察到的相关性可能是随机的。事实上,Amazon.com 的目录中有成千上万的存储卡,其中许多是与相机随机相关的。许多电子商务网站手工构建兼容性知识库,维护起来很昂贵且容易出错,像 Amazon.com 这种规模的大型网站情况尤甚。我们发现,给定足够的数据和关于项目相关性的强大指标,兼容性可能会从人们的行为中体现出来。
奇怪的是,我们发现相关项目的含义也可能与时间关系密切,它会从数据中产生并被客户自己发现。譬如,考虑人们浏览的物品与他们购买的物品。对于书籍、音乐和其他低成本物品,人们倾向于查看和购买相同的东西。而对于许多昂贵的物品,特别是非媒体物品,人们浏览的物品与实际购买的物品可能完全不同。例如,人们往往会浏览许多电视机,但只购买一台电视机。他们在浏览电视的时候看的东西往往是其他的电视机。而他们在购买电视那段时间购买的东西往往是购买特定电视机后的用户体验的补充(如蓝光播放器和壁挂安装套件)。
了解时间的作用对于提高推荐的质量很重要。例如,当计算相关项目表时,某一次购买与另一次购买的相关性在很大程度上取决于它们在时间上的接近程度。如果客户购买一本书、五个月之后购买了另一本书,那么,与客户在同一天购买了另一本书相比,前者的相关性更弱一些。时间方向性也可以有所帮助。例如,客户倾向于在购买相机之后再购买存储卡,而不是相反。这可能是一个很好的提示,当有人购买存储卡时,我们不应该推荐相机。有时,人们购买物品是有顺序的,例如书籍、电影或电视剧,推荐商品应该基于人们下一步要做的事情。
Amazon.com 的目录在不断变化。 每天,成千上万的新物品到达,许多其他的物品逐渐过时。这个周期在某些类别中尤其明显。 例如,服装有季节性潮流,消费电子技术创新迅速。新项目可能处于劣势,因为它们还没有足够的数据与其他项目产生很强的相关性。这被称为冷启动问题,并且通常需要一个探索或利用过程来给尚未有很多展示机会的物品获得展示的机会。诸如新闻或社交媒体帖子等是冷启动问题种特别具有挑战性的一部分,通常需要把基于内容的算法(使用主题、话题和文本)生成的数据与基于行为的算法(使用购买、视图或评级)生成的数据相混合。
客户也有生命周期,并存在自己的冷启动问题。长期以来,当我们对新客户的兴趣了解甚少时,向客户推荐什么一直是一个问题。什么时候利用有限的信息、什么时候通过常见的项目作出稳妥的推荐,的确是一个很难得到正确答案的微妙的问题。
即使对于成熟的客户,在正确的时间进行建模对推荐的质量也有很大的影响。随着年龄的增长,以前的购买与客户当前的兴趣可能不太相关。例如,有些采购(如帆船航海手册)可能表明持久的长期兴趣。其他购买(如洗碗机修理工具)可能与以后的项目无关。有一些购买,如婴儿摇铃,推荐结果经过一段很长的时间后需要做出改变:四年后,我们应该推荐平衡自行车和书籍,而不是婴儿奶瓶和牙胶。有些物品,如书籍,通常只买一次。其他物品,如牙膏,会一次又一次地被购买,而且购买之间的时间间隔是可以预测的。
推荐的质量不仅取决于过去购买的时间,而且取决于购买的东西。我们发现单次购买书籍可以显示客户的很多兴趣信息,让我们可以推荐几十个高度相关的项目。但是,非媒体类别的许多购买行为能够体现的客户信息却甚少。譬如,从购买订书机可以获得哪些见解?买一双袜子可以做出什么令人惊奇和有见地的建议?推荐胶带分配器或更多的内衣在当下可能是有帮助的,但长期来看却没有太多帮助。因此,我们必须开发新技术来学习哪些购买行为能带来有用的建议,以及何时应该忽略某些建议。
最后,多样性推荐的重要性是众所周知的。有时最好给出许多相关的项目,而不是一个种类很少的列表。 Amazon.com 有着数量庞大且种类丰富的产品目录,在书店等单一产品类别商店中都没有遇到过这种挑战。 例如,向阅读量大的读者推荐更多的书籍可能会提高销售额,但是人们可能通过在另一个产品系列中发现他们以前从未考虑过的项目来长期受益。即时意图(immediate intent)也是多样性的一个因素。当有人明确寻找特定商品时,推荐应该缩小范围以帮助他们快速找到需要的东西。但是,当意图不明确或不确定时,目标应该在于发现有价值的项目。在多样性的推荐中找到适当的平衡,需要实验和长期优化。
推荐的未来会怎么样?我们相信未来将会有比过去更多的机会等着我们。我们可以想象智能互动服务,到那时购物就像对话一样容易
未来推荐系统将不再局限于键入搜索关键字和浏览网站。推荐系统应该就像与你的朋友交谈一样,它认识你、知道你的喜好、在选择的每一步都能给你提供意见并且能对你的需求做出预测。
这是我们对于智慧无处不在的愿景。 每一次互动都应该反映出你是谁、你喜欢什么,并帮助你找到其他与你喜好类似的人已经发现的东西。当你看到一些明显不是你感兴趣的东西时,应该感到空虚和可悲;难道你现在不认识了我吗?
我们需要采用一种新的思维方式来考虑推荐才能做到这一点。未来不应该有推荐功能和推荐引擎。相反,理解你、理解其他人和可用性应该成为每次互动的一部分。
推荐和个性化存在于遍布全球的数据海洋中,包括我们找到的内容、我们发现的内容以及我们喜爱的内容。我们相信未来的推荐将进一步建立在利用人类集体智慧的智能计算机算法上。未来将继续由计算机来协助人们去帮助其他人。
近二十年前,Amazon.com 向数以百万计的客户推出了数百万项目的推荐,帮助人们发现自己可能找不到的内容。从那时起,最初的算法已经扩展到大部分的网络应用,被用来帮助人们寻找想看的视频或感兴趣的新闻,受到其他算法和技术的挑战,同时在提高多样性、发现度、新旧程度、时间敏感或序列项目以及许多其他问题上都得到了改进。由于其简单性、可扩展性、可解释性、适应性和相对高质量的建议,基于项目的协同过滤仍然是当今最流行的推荐算法之一。
然而,推荐系统仍然是一个开放领域。使每个客户都拥有个性化体验的愿景并没有完全实现。仍然有很多的机会和可能性来为每个推荐系统的每一个部分添加智能和个性化,使推荐系统体验起来真的像一个认识你、知道你的喜好、了解其他人喜好并清楚可以给你提供什么选择的朋友。推荐就是发现,通过发现新事物给你带来惊喜和喜悦。每一次互动都应该是一次推荐。
Brent Smith 在 Amazon.com 进行了 17 年的个性化和推荐工作,领导团队致力于快节奏的面向客户的创新。Smith 拥有加利福尼亚大学圣地亚哥分校数学学士学位和华盛顿大学数学硕士学位。
Greg Linden 是 Microsoft 的数据科学家(以前曾在 Amazon.com、Google 和几家创业公司工作过)。他以前的工作领域主要是推荐、个性化、人工智能、搜索和广告。Linden 拥有华盛顿大学的计算机科学硕士学位和斯坦福大学的工商管理硕士学位。
查看英文原文:
https://www.computer.org/csdl/mags/ic/2017/03/mic2017030012.html
今日荐文
点击下方图片即可阅读

行进中换轮胎:万字长文解析美团和大众点评两大数据平台是怎么融合的
作为大数据先行者的 TalkingData,将在 9 月 11 日 TalkingData T11 智能数据峰会上,用自己的方式为企业讲述如何聆听数据的奥妙,将传统行业与新兴技术结合,完成向数据驱动型企业的转型升级。更多精彩点击「 阅读原文 」查看详情,报名从速,精彩享不停。