一份不可多得的深度学习技巧指南

来源:52AI人工智能
常言道,师傅领进门,修行靠个人,相信很多人或多或少是在别人的建议或带领下步入深度学习这个大坑,然后师傅说深度学习是个玄学,后面就靠个人修行,瞬间就懵了对不对?可能后面经过自己的磨盘滚打,不断实验积累相关经验,会有一些自己的学习心得。本文可谓是深度学习中的一份秘籍,帮助你少走一些弯路。在本文中,列举了一些常用的机器学习的训练技巧,目的是对这些技巧进行简单的介绍并说明它们的工作原理。另外一些建议是斯坦福的CS231n课程及之前总结的网络结构。
本文的目录如下:
数据预处理
初始化
训练
正则化
网络结构
自然语言处理
增强学习
网络压缩
数据预处理
(本部分原作者没有写,以个人的理解及相关补充这部分内容)
What:输入神经网络数据的好坏直接关系着网络训练结果,一般需要对数据进行预处理,常用的数据预处理方式有:
去均值:每个原始数据减去全部数据的均值,即把输入数据各个维度的数据都中心化到0;
归一化:一种方式是使用去均值后的数据除以标准差,另外一种方式是全部数据都除以数据绝对值的最大值;
PCA/白化:这是另外一种形式的数据预处理方式,一种方式是降维处理,另外一种是进行方差处理;
Why:通过对数据进行预处理能够使得它们对模型的影响具有同样的尺度或其他的一些目的。
Ref:CS231n Convolutional Neural Networks for Visual Recognition.
初始化
What:权重若初始化合理能够提升性能并加快训练速度,偏置一般设置为0,对于权重而言,建议统一到一定区间内:
对于线性层[1]:区间为[-v,v],v = 1/sqrt(输入尺寸),sqrt表示开根号;
对于卷积层[2]:区间为[-v,v],v = 1/sqrt(卷积核的宽度x卷积核的高度x输入深度);
批量标准化[3]在某些方面的应用降低了调整权值初始化的需要,一些研究结果页提出了相应的替代公式。
Why:使用默认的初始化,每个神经元会随着输入数量的增多而存在一个方差,通过求根号缩放每个权重能确保神经元有近似的输出分布。
Ref:
1.Stochastic Gradient Descent Tricks, Leon Bottou;
2.在Torch中默认这么操作;
3.Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, S. Ioffe and C. Szegedy;
What:对于长短期记忆网络(LSTM),遗忘偏置一般设置为1,可以加快训练过程。
Why:直觉是训练开始时,想要信息在细胞之间传播,故不希望细胞忘记它的状态。
Ref:An Empirical Exploration of Recurrent Network Architectures, Rafal Jozefowicz et al.
What:对于t-分布领域嵌入算法(t-SNE),原作者建议对于大小为5000~10000之间的数据集,将困惑度设置为5和50之间[1],对于更大的数据集,相应的困惑度也会增。
Why:困惑度决定了每个点的高斯分布的方差大小,更小的困惑度将获得更多的集群,大的困惑度与之相反,太大的困惑度没有任何意义;另外需要考虑的是画出的聚类不能保留原有的规模,聚类之间的距离不一定代表原始的空间几何,不同的困惑度能在数据结构上提供互补的信息,每次运行都会产生不同的结果[2]。
Ref:
1.Visualizing High-Dimensional Data Using t-SNE, L.J.P. van der Maaten.
2.How to Use t-SNE Effectively, Wattenberg, et al., Distill, 2016.
训练
What:除了使用真值硬化目标外,同样可以使用软化目标(softmax输出)训练网络。
Ref:Distilling the Knowledge in a Neural Network / Dark knowledge, G. Hinton et al.
What:学习率可能是需要调参中最重要的一个参数,一种策略是选择一些参数均有随机化学习率,并观察几次迭代后的测试误差。
参数 |
什么情况下增加性能 |
原因 |
注意事项 |
隐藏节点的数量 |
增加 |
增加隐藏节点的数量提升了模型的表示能力 |
隐藏节点的增加会增加模型每次操作的时间和内存代价 |
学习率 |
调整优化 |
一个不合适的学习率会导致模型效率很低 |
|
卷积核的宽度 |
增加 |
增大核宽度提升模型的参数个数 |
更宽的核导致一个更窄的输出维度 |
隐性的零填充 |
增加 |
在卷积前补零保持大尺寸的表示 |
增加了大多数操作的时间和内存代价 |
权值衰减系数 |
降低 |
降低权值衰减系数释放模型的参数 |
|
Dropout的概率 |
降低 |
丢失更少的节点使得单元有更多的机会去拟合训练集 |
Ref:Some advice for tuning the hyperparameters. Ref: Goodfellow et al 2016 Book
正则化
What:在RNN中使用Dropout,它仅仅应用于非循环连接[1],但是一些最近的文章提出了一些技巧使得Dropout能应用于循环连接[2]。
Ref:
1.Recurrent Neural Network Regularization, Wojciech Zaremba et al.
2.Recurrent Dropout without Memory Loss, Stanislau Semeniuta et al.
What:批量标准化(Batch Normalization, BN),增添了一个新的层,作者给出一些额外的技巧加速BN层的工作:
增大学习率;
移除/减少dropout:在不增加过拟合发生的条件下加快训练;
移除/减少L2范数权值归一化;
加快学习率衰减速度:使得网络训练更快;
移除局部响应归一化;
将训练样本打乱地更彻底:防止相同的样本总出现在小批量中(验证集上提高了1%);
减少光度失真;
Why:一些好的解释在此。
Ref:Accelerating Deep Network Training by Reducing Internal Covariate Shift, S. Ioffe and C. Szegedy.
网络结构
What:使用跳跃式连接,直接将中间层连接到输入/输出层。
Why:作者的观点是通过减少神经网络的底端与顶端之间的处理步骤使得训练深层网络更加简单,并减轻梯度消失问题。
When:在一些CNN结构中或RNN中一些重要的层。
Ref:Generating Sequences With Recurrent Neural Networks, Alex Grave et al.
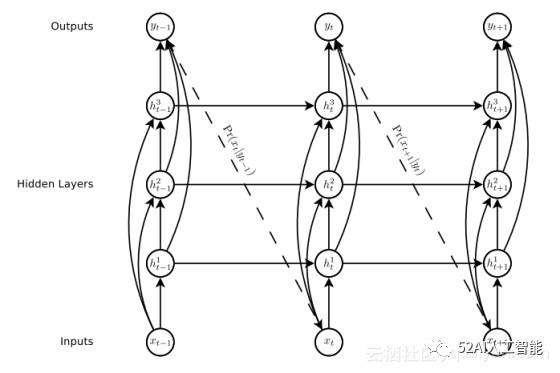
RNN的跳跃式连接例子
What:为LSTM增加窥视孔连接(连接之前输出到门的输入),根据作者的观点,这个操作对长时间依赖关系有用。
Ref:Learning Precise Timing with LSTM Recurrent Networks, Felix A. Gers et al.
What:大多数的深度学习框架提供了一个结合SoftMax和Log的函数或者是在损失函数中计算SoftMax(在Tensorflow中是softmax_cross_entropy_with_logits,在Torch中是nn.LogSoftMax),这些应该被更好地使用。
Why:Log(SoftMax)在数值上不稳定是小概率,从而导致溢出等不良结果。另外一种流行的方法是在Log中加入一些小数避免不稳定。
自然语言处理(NLP)
What:对于RNN和seq2seq模型的一些技巧:
嵌入尺寸:1024或620。更小的维度比如256也能导致很好的表现,但是更高的维度不一定导致更好的表现;
对于译码器而言:LSTM>GRU>Vanilla-RNN;
2-4层似乎普遍足够,但带有残差的更深网络看起来很难收敛,更多去挖掘更多的技巧;
Resd(密集的残差连接)>Res(近连接先前层)>无残差连接;
对于编码器而言:双向>单向(反向输入)>单向;
注意力(加法)>注意力(乘法)>无注意力;
使用光束会导致更好的结果;
Ref:Massive Exploration of Neural Machine Translation Architectures, Denny Britz, Anna Goldie et al.
What:对于seq2seq而言,翻转输入序列的顺序,保持目标序列的完整。
Why:根据作者的观点,这种简单的数据变换极大提升了LSTM的性能。
Ref:Sequence to Sequence Learning with Neural Networks, Ilya Sutskever et al.
What:对于seq2seq而言,为编码器和译码器网络使用不同的权值。
Ref:Sequence to Sequence Learning with Neural Networks, Ilya Sutskever et al.
What:当训练时,强制更正译码器的输入;在测试时,使用先前的步骤,这使得训练在开始时非常高效,Samy等人提出了一种基于模型转变的改进方法[1]。
Ref:1.Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks, Samy Bengio et al.
What:以无监督的方式训练一个网络去预测文本的下一个字符(char-RNN),该网络将学习一种能用来监督任务的表示(比如情感分析)。
Ref:Learning to Generate Reviews and Discovering Sentiment, Ilya Sutskever et al.
增强学习
What:异步:以不同的勘探政策同时训练多个代理,提升了鲁棒性。
Ref:Asynchronous Methods for Deep Reinforcement Learning, V. Mnih.
What:跳帧:每隔4帧计算一次动作,而不是每帧都计算,对于其它帧,重复这个动作。
Why:在Atari游戏中工作得很好,并且使用这个技巧以大约4倍的速度加快了训练过程。
Ref:Playing Atari with Deep Reinforcement Learning, V. Mnih.
What:历史:不是仅仅将当前帧作为输入,而是将最后的帧与输入叠加,结合间隔为4的跳帧,这意味着我们有一个含t、t-4、t-8及t-12的帧栈。
Why:这允许网络有一些动量信息。
Ref:Deep Reinforcement Learning with Double Q-learning, V. Mnih.
What:经验回放:为了避免帧间的相关性,作为一个代理不是更新每一帧,最好是在过渡时期的历史中采样一些样本,该思想类似于有监督学习中训练前打乱数据集。
Ref:Prioritized Experience Replay, Tom Schaul et al.
What:Parallel Advantage Actor Critic(PAAC):通过代理的经验以及使用一个单一的同步更新模型使得简化A3C算法成为可能。
Ref:Efficient Parallel Methods for Deep Reinforcement Learning, Alfredo V. Clemente et al.
网络压缩
What:在推理中,为了减少层数,通过批量归一化(BN)层能够吸收其它的权值。这是因为在测试时批量归一化进行地是一个简单的线性缩放。
作者信息

Conchylicultor,谷歌大脑参与者,专注于机器学习和软件开发。
Linkedin:https://www.linkedin.com/in/potetienne/
Mail:etiennefg.pot@gmail.com
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Deep Learning Tricks》,作者:Conchylicultor,译者:海棠,审阅:
文章为简译,更为详细的内容
请查看:http://www.52ai.com/AIjiaocheng/3832.html



点击下方“阅读原文”下载同声译
↓↓↓




