CVPR 2020(Oral) | 旷视提出DynamicRouting:针对语义分割的动态路径选择网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文是旷视 CVPR 2020 论文系列解读第6篇,也是 CVPR 2020 Oral 论文之一,它提出了针对语义分割任务的的动态路径选择(Dynamic Routing)网络,可根据每个图像中物体尺寸的分布情况,动态生成与这些数据相关的网络传播路径。一系列消融实验展示了本文动态网络相对于静态架构的优势。在Cityscapes和PASCAL VOC 2012数据集上的实验也证明了本文方法的有效性,模型以小得多的计算成本在性能上取得了与当前最佳工作相当的表现。 论文代码已开源。
本文是旷视 CVPR 2020 论文系列解读第6篇,也是 CVPR 2020 Oral 论文之一,它提出了针对语义分割任务的的动态路径选择(Dynamic Routing)网络,可根据每个图像中物体尺寸的分布情况,动态生成与这些数据相关的网络传播路径。一系列消融实验展示了本文动态网络相对于静态架构的优势。在Cityscapes和PASCAL VOC 2012数据集上的实验也证明了本文方法的有效性,模型以小得多的计算成本在性能上取得了与当前最佳工作相当的表现。 论文代码已开源。

论文名称:Learning Dynamic Routing for Semantic Segmentation
论文链接:https://arxiv.org/abs/2003.10401
论文代码:https://github.com/yanwei-li/DynamicRouting
目录
导语
简介
动态路径选择
路径空间
路径选择过程
实验
动态路径选择
Cityscapes
PASCAL VOC 2012
结论
参考文献
往期解读
导语
图像语义分割的目标是对每个像素都进行语义分类,它是当前计算机视觉领域最重要、最具挑战性的任务之一。语义分割的问题之一来自于其处理的图像中存在尺寸不一的物体及背景区域,这种尺寸分布的差异给特征表示和关系建模带来了不少困难。
传统的解决方法是通过设计精巧的模型结构来缓解这种差异,然而无论是人工设计还是基于NAS模型搜索得到的网络,都尝试在单个网络框架中编码所有的像素区域。以这种模式来应对真实环境中尺度多样化分布的物体时会缺乏足够的自适应性。因此,需要更加可定制化的网络来对每一张图像进行处理。
简介
本文中,旷视研究院针对语义分割任务提出一个全新的理念:动态路径选择(Dynamic Routing)。具体而言,动态路径选择会在推理过程中根据输入图像生成前向传播路径,也就是说随着输入数据的不同,网络也会自适应地生成不同的结构进行特征编码。利用该方法,网络可以将不同尺寸的物体(或背景)分配到对应分辨率的层级上,以实现有针对性的特征变换。
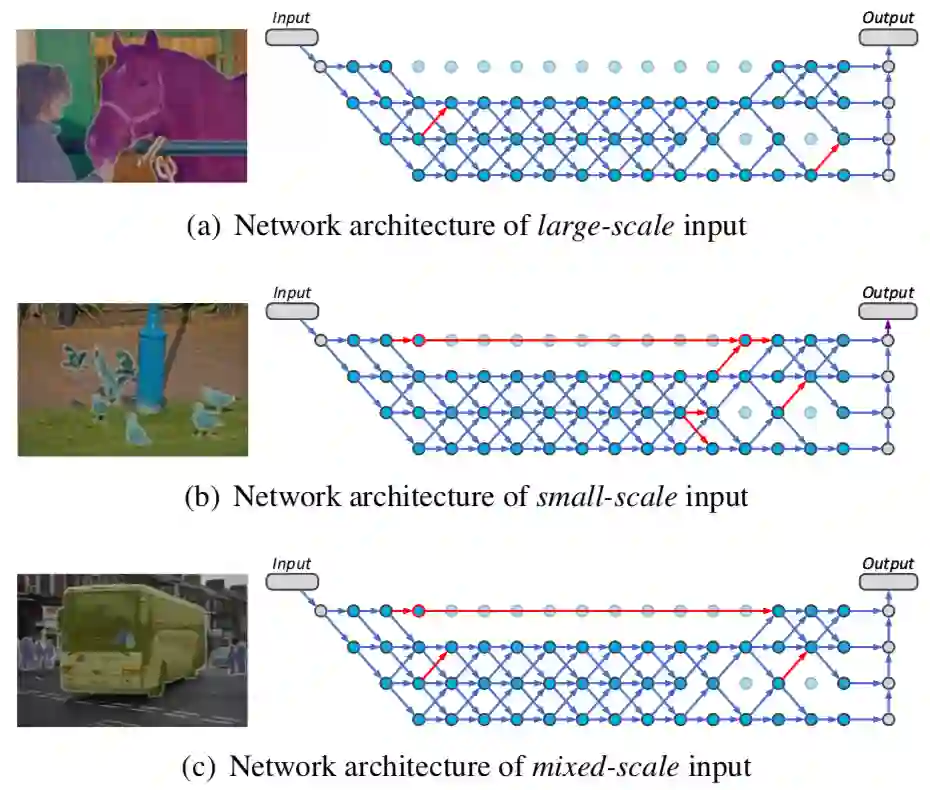
图1:根据输入尺寸的不同,本文提出的方法选择相应的前向计算路径
如图1所示,模型会根据图像所包含的物体尺寸分布情况选择不同路径。与之前用于高效物体识别的动态网络结构研究不同的是,本文聚焦于语义表征,目的是缓解来自画面物体尺寸差异所带来的影响,从而提升网络性能和效率。
在图像分类任务中,特征分辨率往往随着网络层级的增大成递减趋势,而这在语义分割任务中并不适用。本文针对语义分割任务提出一个容量更大的路径空间,其包含多个独立的计算节点。不同于之前工作的是,本文所提出的路径空间可支持多路径传播与跳跃链接,而这种连接方式已被证明在语义分割中起着相当重要的作用。因此,本文可以在所提出的路径空间中对多个经典网络结构都进行建模,如图3所示。
就动态路径选择而言,本文设计了一种路径选择门控网络,称为软条件门控(Soft Conditional Gate),该门控网络可根据输入图像自适应地选择特征变换路径。此外,该路径选择门控还能被建模为一个可微分模组,从而结合给定的计算资源对网络结构进行端到端的优化。
动态路径选择
与静态网络结构相比,所提出的动态网络具有模型容量大、性能好、资源消耗少等优点。
路径空间
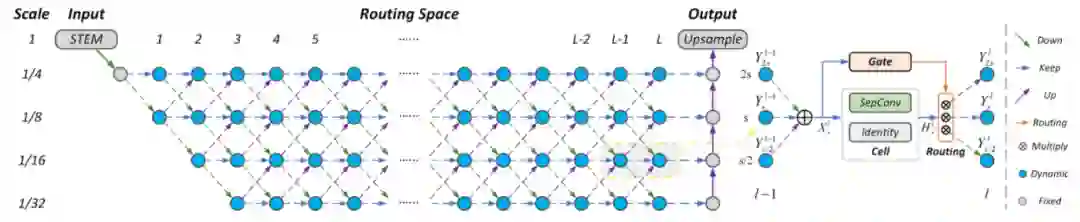
图2:本文方法的框架图
如图2所示,为了释放动态网络结构的潜能,本文提供了相邻层间的全连接通路。按照经典的神经网络设计模式,网络开始阶段是一个由固定的3层网络所组成的STEM模块,其将输入图像的分辨率下降到1/4;之后是用于动态路径选择的路径空间,它由L层网络构成。在这个空间中,相邻节点间的分辨率放缩步长设为2,这也是在基于ResNet的模型中广泛采用的设置。因此,最小的下采样尺度被设为1/32。
在这些约束之下,每一层的候选节点数量最多可为4,且对于每一个候选节点,都有3种尺度变换通路,即上采样、尺度保持和下采样。每个候选节点包含了计算单元和路径选择门控,分别用于特征聚合和前向路径的选择,如图2所示。在网络末端,固定着一个逐层上采样的模组,用于生成最终的预测结果。
与Auto-DeepLab每个节点只选择一条路径不同,本文对路径空间进行了扩展,使得每个候选节点在前向推断中都支持多通路选择与跳跃链接。如图3所示,在更加通用的空间下,许多经典架构都能够通过该框架来模拟。
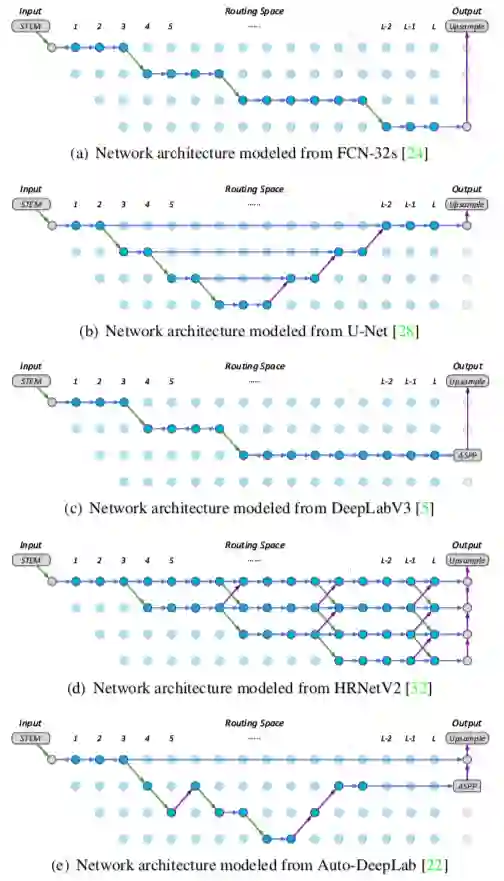
图3:经典结构在动态网络空间中的建模示意图
路径选择过程
给定一个有着多个独立节点的路径选择空间,本文在每个节点中都内置了一个基本的计算单元和一个对应的条件门控,分别用来聚合多尺度特征和进行路径选择,图2可视化了这个过程。
计算单元操作:对于输入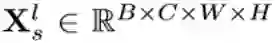
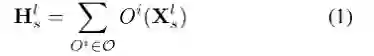
然后生成的特征图 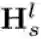
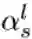
软条件门控网络:每一条路径的选择概率都由Gate函数生成,如图2右图所示。具体而言,在门控网络中采用了轻量级的卷积操作,以学习数据自适应的特征向量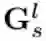
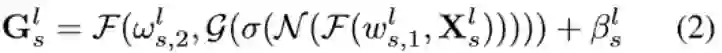
然后,为了实现通路选择,本文提出使用软条件门控进行可微的路径选择。具体而言,对于特征向量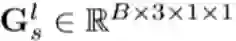
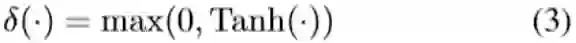
因此,激活系数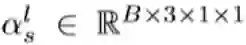
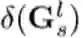
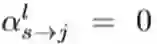
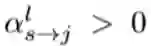
给定资源约束:考虑到实际场景中有限的计算资源,本文将给定的资源约束纳入优化过程中以生成高效的动态网络结构。结合所提出的条件门控网络,本文将单个节点中的计算消耗建模为
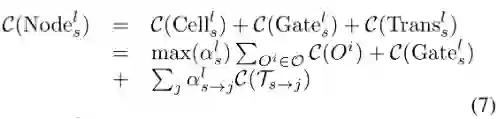
因此,整个路径选择空间中的计算消耗期望可使用以下方法进行表示:
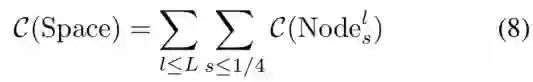
在给定计算约束C和衰减系数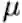
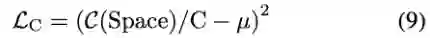
实验
动态路径选择
为了展示动态路径选择的优越性,旷视研究院在路径空间中用传统手工设计和模型搜索设计的网络(FCN-32s、U-Net、DeepLabV3、HRNetV2以及Auto-DeepLab)的连接方式进行了静态路径建模,可视化如图3所示。
另外,为了实现公平的性能对比,本文用对动态网络模型的计算量进行约束,从而生成了表1中的三个网络Dynamic-A、B、C。与手工设计和模型搜索得来的网络进行对比,本文提出的动态路径选择方法在相似计算消耗的前提下取得了显著的性能提升。
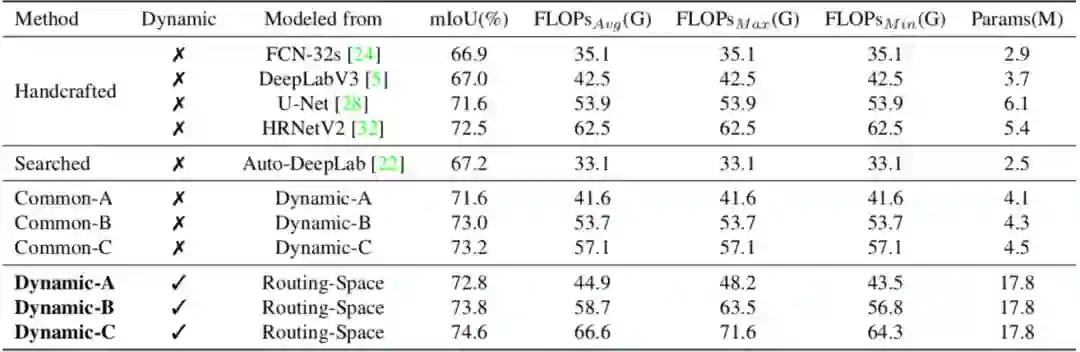
表1:Cityscapes验证集上的对比
此外,如表1所示,本文根据不同的资源限制从动态网络中抽取出了3个静态的通用网络连接(Common-A、B、C,可视化结果见图4),它们均保留了相应动态网络中最常用的前向推断通路。通过将这三个网络纳入对比,可以发现在相似计算消耗下,拥有动态路径选择的网络性能依然好于静态网络结构。
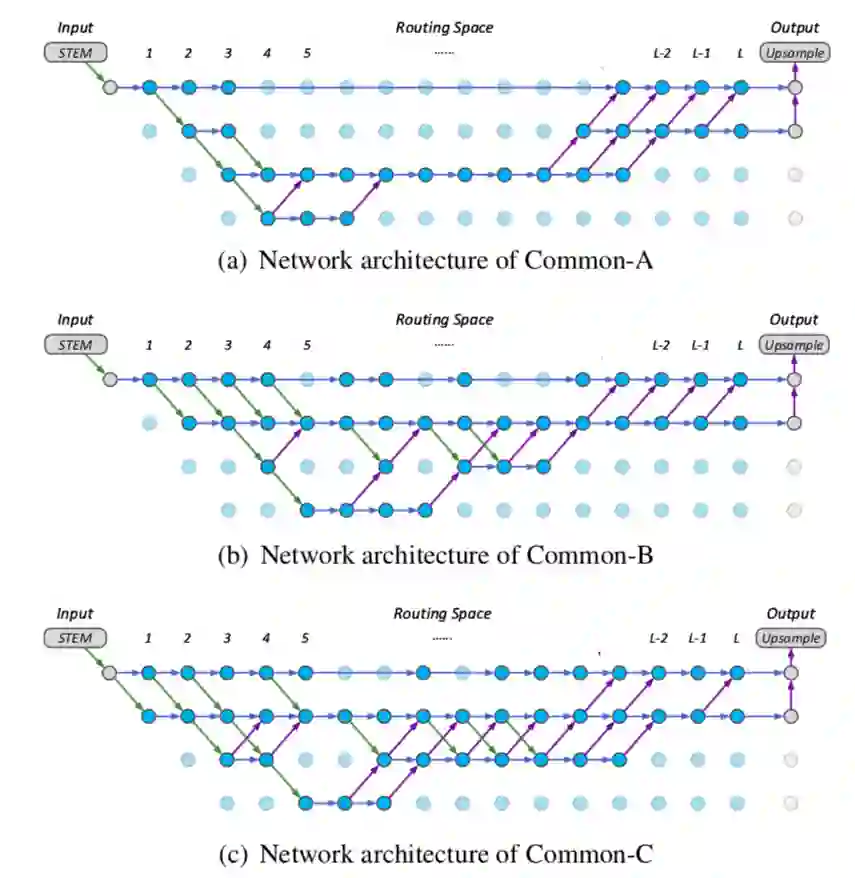
图4:Common-A, B, C的网络架构
Cityscapes
本文在Cityscapes数据集上进行了实验,如表5所示。通过将动态网络与在验证集上训练的有着不同设置的固定backbone进行对比,可以发现本文方法均取得了更佳性能。同时,如果采用Scheduled Drop Path并进行ImageNet预训练,动态网络的性能还可以进一步提升。
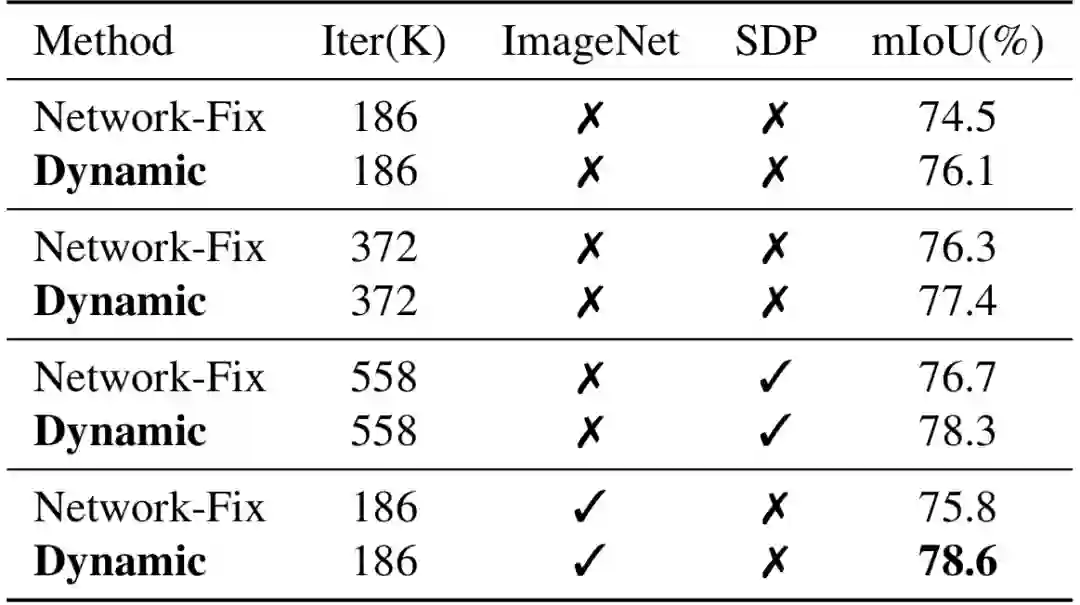
表5:不同设置下Cityscapes验证集的实验结果
另外,表6展示了本文方法与此前其它工作的对比情况。可以发现,在计算消耗相似的前提下,动态网络在验证集上的mIoU,较精心设计的BiSenet高出了3.8%。在简单的尺度变换模组的支持下,动态网络(L=33)用更少的计算消耗取得了与当前最佳模型相当的表现。
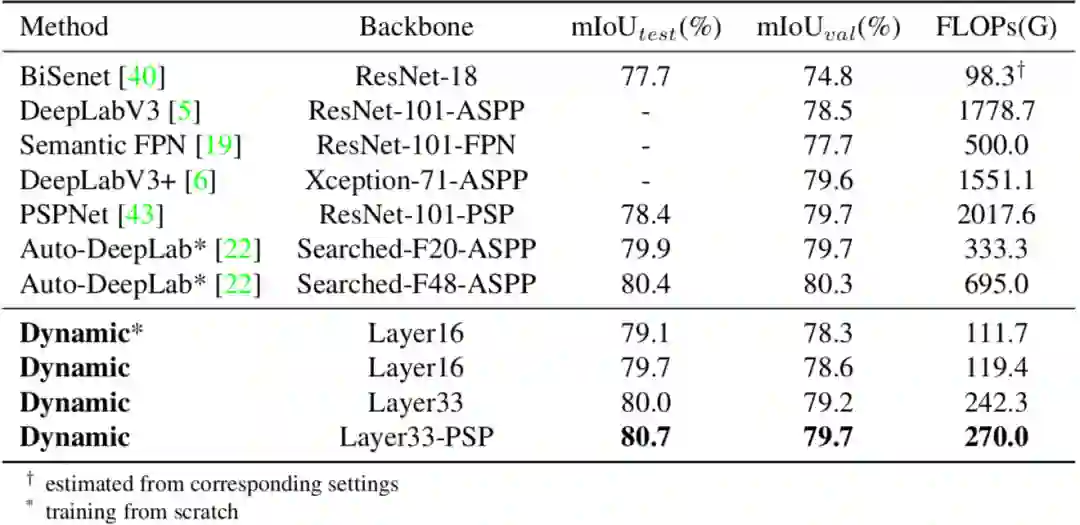
表6:Cityscapes数据集上的实验对比
此外,结合通用的场景关系建模方法(如PSP模块),所提出的动态网络能够获得进一步的性能提升,在Cityscapes测试集上 mIoU 达到了80.7%。
PASCAL VOC 2012
类似的对比方法也应用在了PASCAL VOC 2012数据集上,取得了同样的优异结果。
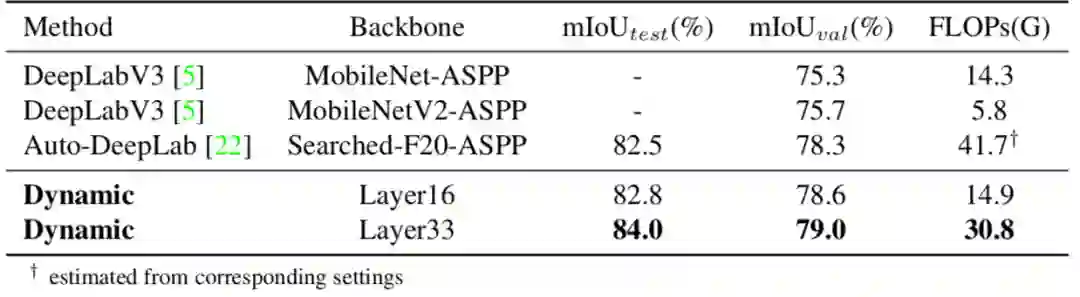
表7:PASCAL VOC 2012数据集上的实验对比
结论
在本文工作中,旷视研究院提出了针对语义分割任务的的动态路径选择模型。与以往工作相比,最主要的区别在于它能够根据每个图像中出现的物体尺寸分布情况,有针对性地生成与数据相关的网络连接。
为了实现这一目标,本文提出软条件门控,其能以端到端的方式来选择进行尺寸变换的路径,并在给定计算资源下舍弃无意义的计算消耗,从而获取性能及效率的提升。
另外,一系列消融实验也验证了本文所提出的动态架构相对于静态网络的优势。在Cityscapes和PASCAL VOC 2012数据集上的实验证明了本文方法的有效性,模型以更小的计算成本在性能上得到了与当前最佳工作相当的表现。
论文下载
在CVer公众号后台回复:DR,即可下载本论文
参考文献
Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. TPAMI, 2017.
Liang-Chieh Chen, Maxwell Collins, Yukun Zhu, George Papandreou, Barret Zoph, Florian Schroff, Hartwig Adam, and Jon Shlens. Searching for efficient multi-scale architec- tures for dense image prediction. In NeurIPS, 2018.
Liang-ChiehChen,YukunZhu,GeorgePapandreou,Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. InECCV, 2018.
Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan L Yuille, and Li Fei-Fei. Auto- deeplab: Hierarchical neural architecture search for semantic image segmentation. In CVPR, 2019.
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InCVPR, 2015.
VladimirNekrasov,HaoChen,ChunhuaShen,andIanReid. Fast neural architecture search of compact semantic segmen- tation models via auxiliary cells. In CVPR, 2019.
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E Gonzalez. Skipnet: Learning dynamic routing in convolutional networks. In ECCV, 2018.
论文下载
在CVer公众号后台回复:DR,即可下载本论文
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1300人!涵盖语义分割、实例分割和全景分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加群
▲长按关注我们
麻烦给我一个在看!





