【论文解读】基于copy机制的端到端实体关系抽取模型
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要9分钟
跟随小博主,每天进步一丢丢


每日英文
Weep no more, no sigh, nor groan. Sorrow calls no time that's gone.
别哭泣,别叹息,别呻吟。悲伤唤不回流逝的时光。
Recommender:云不见
作者:Chevalier
学校:华南理工大学
方向:自然语言处理

为了构建大规模结构化的知识库,目前有很多工作专注于从自然语言文本中抽取关系事实。关系事实通常用三元组表示:(实体1,关系,实体2),比如(Chicago,country,UnitedStates)。
目前为止,有很多方法专注于关系抽取或关系分类任务,该任务是识别两个预先给出的实体之间的关系。这类方法假设实体已经给定,忽略了实体的抽取。早期的实体关系抽取方法是pipeline的,即先进行NER,然后再进行RE。这种流水线的方法将两个任务独立开来,忽略了两个任务之间的相关性。紧接着,就有人提出联合抽取实体关系的方法。早期的联合方法依赖于特征工程和NLP工具。随着深度学习的兴起,后期的工作开始用CNN或RNN来联合抽取实体关系。比如Miwa、Gupta、Zhang等人将关系抽取任务建模为槽填充问题。Zheng等人将联合抽取问题转换为序列标注问题。
实体关系三元组在句中通常是比较复杂的,存在关系重叠现象,根据关系重叠度可以分为三种类型:Normal,EntityPairOverlap(EPO),SingleEntityOverlap(SEO)。如下图所示。
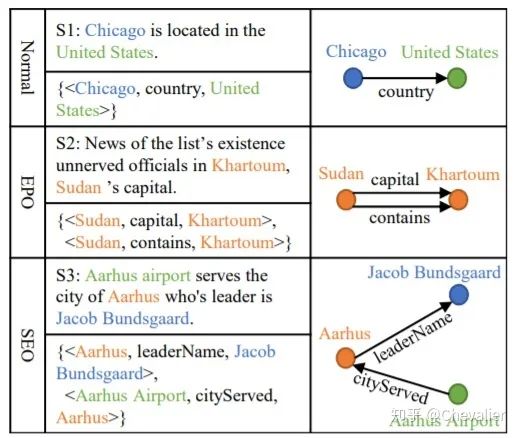
之前的工作主要专注于抽取Normal类型的实体关系三元组,特别是17年ACL那篇(传送门),将实体关系抽取问题转化为序列标注问题,完全忽略了关系重叠问题。因此,作者就提出了基于Seq2Seq拷贝机制的端到端模型,可以抽取任意类型的实体关系三元组。该模型主要由两部分组成:编码器和解码器。编码器将自然语言文本转换成定长的语义向量,解码器根据该语义向量生成三元组。具体细节见Model部分。
本节我们将介绍基于copy机制的Seq2Seq模型,端到端地抽取多个实体关系三元组。该模型主要由两部分组成:编码器和解码器。编码器将自然语言文本转换成定长的语义向量,解码器根据该语义向量生成三元组。解码器根据数量不同可以分为OneDecoder和MultiDecoder。顾名思义,OneDecoder就是用一个解码器来生成所有三元组,而MultiDecoder就是由多个解码器组成,一个解码器生成一个三元组。
OneDecoder Model
OneDecoder模型的整个结构如图二所示。
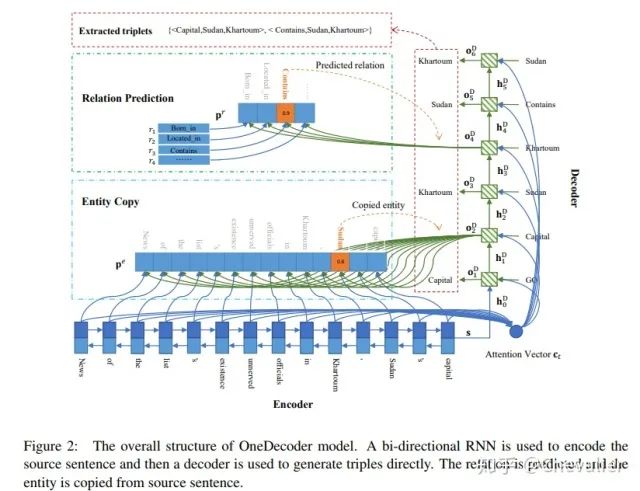
Encoder
首先我们将输入的句子 





通过使用双向的RNN捕捉每个词的上下文信息,我们可以得到 


Decoder
解码器用于直接输出三元组,三元组输出顺序为:首先生成三元组的关系类型,然后从句中找到该关系的头实体,最后从句中找到该关系对应的尾实体。重复该流程,解码器就可以生成多个三元组。一旦生成了所有正确的三元组,接着就生成NA三元组,意味着解码结束。NA三元组由NA关系类型和NA实体类型组成。
如图3中的a所示,每个时刻t,我们会计算解码器的输出 


其中g表示单向的RNN, 



其中, 

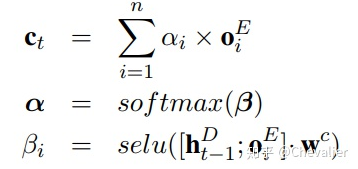
最终,我们得到了解码器时刻t的输出 
Predict Relation:上一步骤我们得到了解码器的输出



Copy the First Entity:和关系预测差不多,通过全连接层得到每个单词的得分。然后取最大概率的实体词的Embedding作为下一时刻的输入


Copy the Second Entity:复制第二个实体与复制第一个实体类型,唯一的不同是复制第二个实体时,复制结果不能是第一个实体。因为一个正确的三元组的头实体和尾实体是不一样的。处理方式也简单,计算概率的时候把第一个实体词mask掉就行。


2. MultiDecoder Model
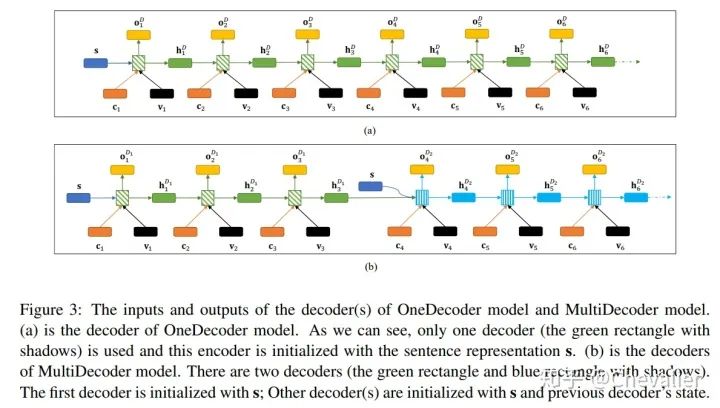
MultiDecoder模型是OneDecoder模型的拓展,如图3的b所示,主要的不同是, MultiDecoder解码期间一个解码器生成一个三元组,而OneDecoder是一个解码器生成所有的三元组。
计算解码器的输出时大部分与OneDecoder的一样,只不过在计算关系的输出时,也就是新的三元组开始预测时,这里要换新的一个解码器,需要传入初始的隐藏层状态。
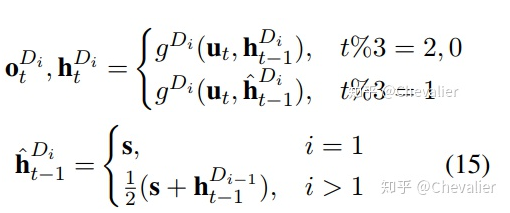
1.Dataset
NYT:一个远程监督数据集
WebNLG
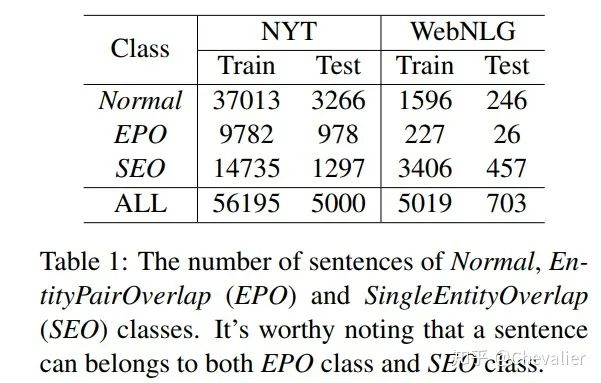
2. Evaluation Metrics
Precision,Recall,F1
baseline模型:17年ACL基于新颖的标注机制模型:NovelTagging。
3. Result
从实验结果看,作者提出MultiDecoder的F1显著优于baseline模型,这说明了作者提出模型的有效性。可以看到baseline模型precision很高,recall很低,这是因为该模型忽略了关系重叠问题,一个词最多只能属于一个三元组。而作者的模型考虑了关系重叠问题,较好地权衡了precision和recall。
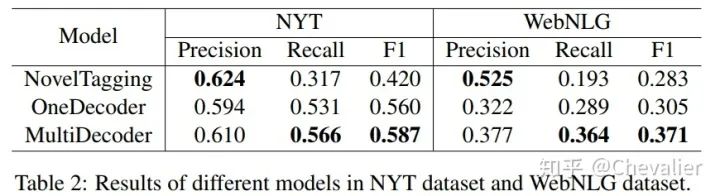
为了验证MultiDecoder模型和OneDecoder模型在解决关系重叠问题的有效性,作者进一步做了实验。可以看到作者提出的两个模型在关系重叠的两种情况(EPO和SEO)是显著优于baseline模型的。NovelTagging模型在Normal Class取得了最优的性能,这是因为该模型的设计更能处理Normal Class这种情况。
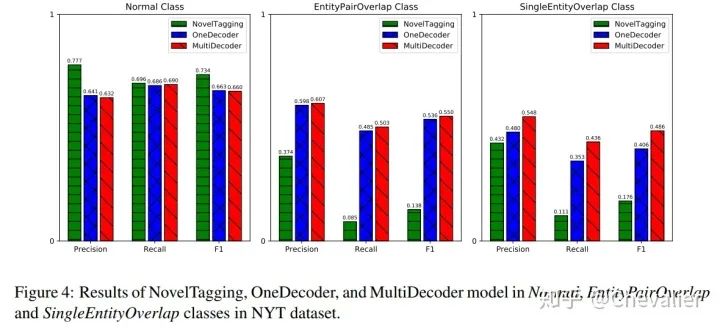
接下来,还比较了模型从包含不同数量的三元组的句子中抽取关系的能力。可以看到,当句中包含的三元组数量越来越多时,Noveltagging模型的性能下降地很快。
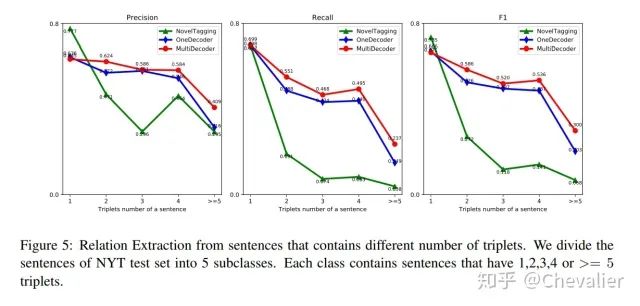
接着比较了OneDecoder和MultiDecoder模型。从结果看,两个模型是差不多的。但是在实体生成方面,MultiDecoder是要优于OneDecoder。作者认为MultiDecoder用了不同的解码器来生成三元组,所以实体生成的结果更加多样性一点。

作者提出了基于copy机制的Seq2Seq端到端模型,同时抽取实体和关系;
通过copy机制解决了关系重叠问题;
在两个数据集上的实验表明验证了作者提出的模型的有效性。
有一些细节不是很懂,作者在预处理NYT数据集时,过滤了句长100个单词的句子,这是因为作者提出的模型难以处理长文本么?
我一直以为实体关系联合抽取是NER+RE,但是17年ACL基于新颖的标注机制这篇抽取实体的时候不考虑实体类型,我有点搞不懂,紧接着许多follow这篇的工作都没考虑实体类型了= =。这篇就更厉害了,这篇抽实体的时候只抽实体的最后一个单词= =。
作者生成三元组的时候没有考虑关系之间的相关性。19年ACL:GraphRel就提出了这个问题,具体解释如下文章。
Chevalier:《基于关系图的实体关系联合抽取》论文笔记

由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记




