华中科技大学(白翔团队)提出 Aster:具有柔性矫正功能的注意力机制场景文本识别方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:SIGAI
SIGAI特约作者
Johnny
研究方向:计算机视觉

简介
场景文本识别的难点在于处理倾斜、弯曲或不规则布局的文本。尤其是三维透视文本和弯曲文字在自然场景中很常见,很难识别。当下的弯曲文字的识别一般是先进行文字区域检测,然后再进行文本图片矫正、识别。

常见的弯曲、倾斜等不规则文字
本文介绍一种端到端神经网络模型ASTER,它由国内知名OCR团队, HUST的白翔老师课题组提出,并进行了代码开源与专利注册。
ASTER的网络结构由一个矫正网络和一个识别网络组成。
矫正网络自适应地将输入图像中的文本进行矫正并转换成一个新的图像。它基于Spatial Transformer Networks(STN)[2],以一个柔性薄板样条插值变换方法(Thin-Plate Spline)[1]作为核心,该方法负责处理各种不规则文本,预测出TPS变换的参数后,并在无人为标注的情况下进行训练。
识别网络是一个基于注意力机制的Seq2Seq的模型,它直接从矫正后的图像预测文本序列。整个模型进行端到端训练,只需要图像和它们的gt文本。通过大量的实验,验证了矫正网络的有效性,展现了ASTER识别规则与不规则的识别能力。此外,还证明了ASTER在端到端网络中的强大作用,它能够很好地增强文本识别的效果,使得水平方向文本识别器得以识别多方向文字。
ASTER主要是指在无矫正标注的情况,用识别的结果指导矫正网络。
主要贡献
此篇文章主要贡献为
提出显式图像矫正机制,可以在无额外标注的情况下显著地提升识别网络的识别效果。
针对识别网络,提出注意力机制的Seq2Seq模型,并引入双向解码器。
基于ASTER的文本矫正和识别的能力,提出一种可以增强端到端文本识别效果的方法。
相较于会议版本[3],此版本有3个改进之处
1)在训练时采用了多种不同分辨率的图像来进行TPS控制点预测,避免了之前STN会产生的矫正图像分辨率下降的问题。减少了定位网络中的非线性激活,保留了反向传播梯度,从而加速了训练过程的收敛。因此识别精度,图像的矫正质量,和对初始值的敏感度都有显著提示。
2)将识别解码器扩展为双向,以利用(leverage)两个方向之间的依赖关系。
3)探索了ASTER在端到端文本识别的表现,实验结果超出会议版本很多,并且具有更好的适应性。
网络结构
一、矫正网络
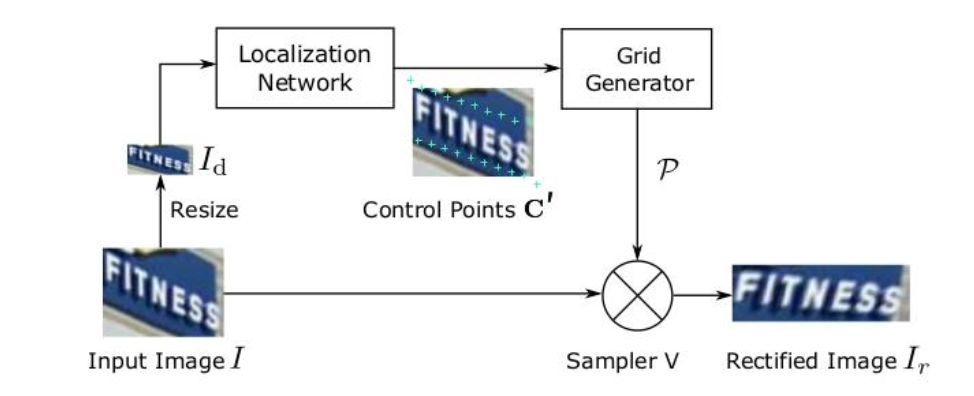
STN网络的核心是将图片空间矫正过程构建成可学习模型,流程如图所示。先将输入图片downsample到Id,定位网络与格点生成器生成TPS变换的参数,再通过采样器(sampler)生成矫正后的图片Ir 。
TPS(Thin Plate Spline)[1]可对图片进行柔性变换,对于透视和弯曲这两种典型的不规则文字的矫正效果很好。
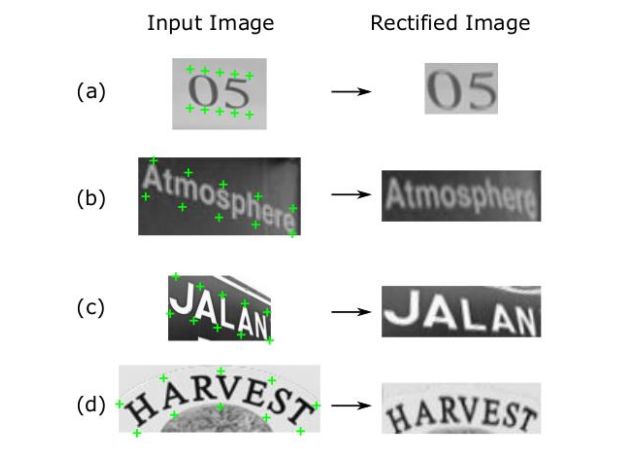
TPS分别对a)松散分布(loosely bounded)、
b)倾斜、c)透视、d)弯曲文本的矫正效果
TPS插值法是指在对薄板中的N个点An形变到对应的N个点Bn时,采用的使得薄板弯曲能量最小的插值方法。弯曲变形能量小意味着薄板整体的变形较为平滑,凸起与凹痕不是非常剧烈。对于二维的图片来说,采用弯曲能量最小的原则,意味着变形后的图像更加平滑,不易出现文字的扭曲变形。

z为薄板经过强制扭曲后垂直于薄板面方向的位移变内化,弯曲能量表达式为
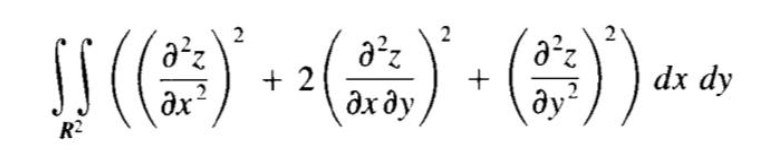
满足弯曲能量最小的表达式即为差值曲线,具体证明过程略过。
对求插值函数参数的数学原理过程感兴趣的同学可以阅读文献[1]
定位网络
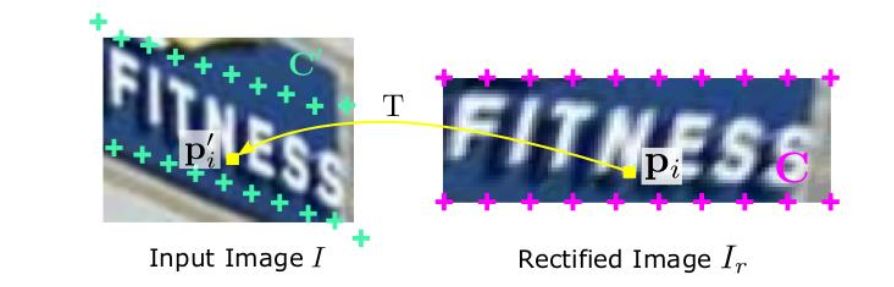
定位网络分别由2个含有K个基准点的坐标集合组成。K个基准点的坐标用C表示,C =[c1,… ,cK]∈R2xK。预测出的坐标用C'表示,C' =[c'1,… ,c'K]∈R2xK。
定位网络由一个CNN网络预测出控制点坐标,并且在训练过程中无需任何坐标标注,只依赖识别网络的文本gt,完全由反向传播的梯度监督。(本文最大亮点之一)
格点生成器
根据文献[2],基础函数φ(r) = r 2 log(r),(相比文献[2]这里漏了个平方,怀疑是笔误,原文为U(r) = r 2 log(r2))
TPS变换矩阵为:
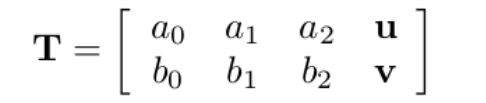
对于输入点p,可以由如下表达式得到其对应坐标p',其中基础函数φ为φ(r) = r 2 log(r)。范数为欧氏距离。
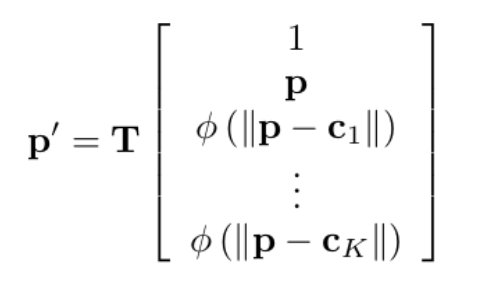
其中TPS变换矩阵可以由下式求出
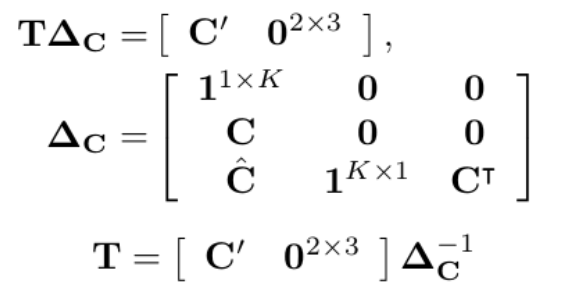
采样器
在校正网络输出端,采样器生成校正后的图像:
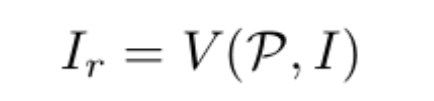
采样器通过插值p′的邻点像素来计算p的值。由于p′可能落在图像外部,所以在采样之前会进行裁剪,以限制采样点在图像边界内。
二、识别网络
作者使用双向解码器扩展的seq2seq模型来解决识别问题。由于seq2seq模型的输出是由RNN生成的,因此它获取了字符依赖关系,从而将语言建模融入识别过程。此外,双向解码器可以在两个方向上捕获字符依赖关系,从而利用更丰富的上下文并提高性能。下图描述了单向版本的结构。根据经典的Seq2Seq模型,识别网络的模型由编码器和解码器组成。
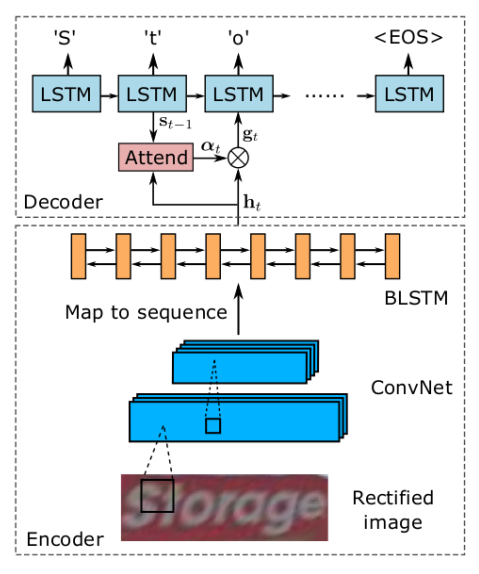
编码器
编码器结构为卷积循环神经网络,通过CNN提取特征图后,可以得到输入图像中比较鲁棒的,比较高级的特征图。这里会将这些特征图转化成一个序列,序列的长度就是特征图的宽度。这样一来,我们就得到了按照从左到右的顺序排列的特征向量。
B-LSTM:在两个方向上分析一个序列的独立性,并输出另一个同样长度的序列,h={h1,h2,…hl}。
解码器
序列到序列模型将特征序列转换为字符序列。它能够输入和输出任意长度的序列。这种模型,因其简单,序列建模能力强,并且能够获取输出依赖关系。
注意序列对序列模型是一个单向递归网络。它对T步迭代工作,产生长度为T的符号序列,表示为(y1,...,yT)。
在步骤t时, 解码器预测一个字符或一个停止符号(EOS),根据编码器的输出H,内部状态st−1,和上一步的预测结果yt−1 。在这一步中,解码器首先计算注意力权重,αt∈Rn,通过其注意机制公式:
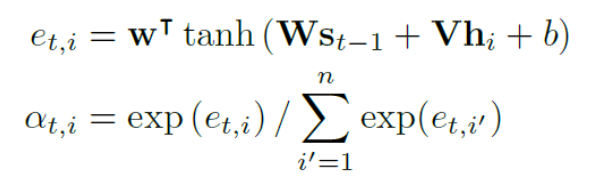
其中,w,W,V 是可训练的权重
注意权值有效地表示编码器输出的每一项的重要性。解码器以权值为系数,将H的列线性组合成向量,称为glimpse:
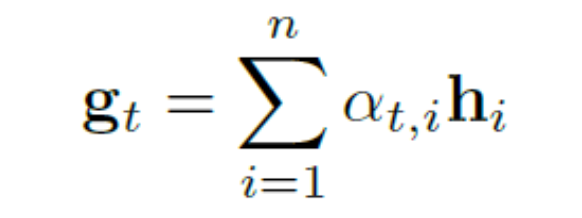
随着时序t的变化,每一个step对输出都是不同的
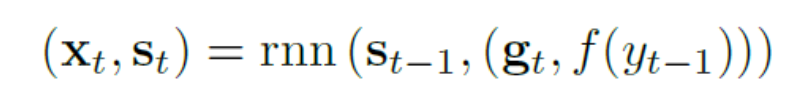
损失函数
本端到端网络仅使用文本groundtruth作为label,目标函数表达式为
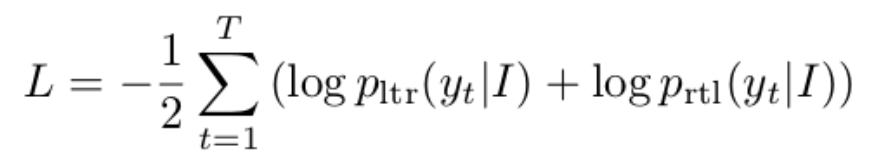
其中y1..yt为文本序列的groundtruth,目标函数是两个方向解码器的平均值。
实验介绍
数据集:
训练集采用了Synth90k的全部图片与SynthText根据bounding box抠出来的图片。
测试集采用了五个标准文字识别数据集IIIT5k-Words(IIIT5k),Street View Text(SVT),ICDAR 2003 (IC03),ICDAR 2013 (IC13),ICDAR 2015 Incidental Text (IC15)。
与两个不规则文本数据集:SVT-Perspective (SVTP)数据集以透视文字为主,CUTE80 (CUTE)以弯曲文本为主。
矫正网络实验
作者在IIIT5k, SVT, IC03, IC13, SVTP, CUTE这6个数据集进行了无矫正网络与有矫正网络的识别结果对比,识别精度对比结果如表格所示。
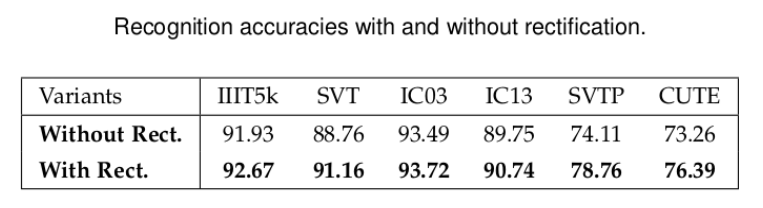
在有矫正网络的情况下,识别精度在不同数据集上都有明显提高。
如图展示了在SVT-Perspective 和CUTE80数据集上的矫正输出图片与识别结果。

识别网络实验
注意力机制分析
为了了解解码器的行为,作者提取了attention权值。即将它们可视化到图所示的几个例子中。在每个图像之上,一个attention权重矩阵在2维特征图中被可视化。映射的第t行对应于第t解码步骤的注意权重。除了非常短的单词,我们可以观察到注意力权重和字符之间的清晰对齐。这说明了该识别网络的隐式字符识别能力。

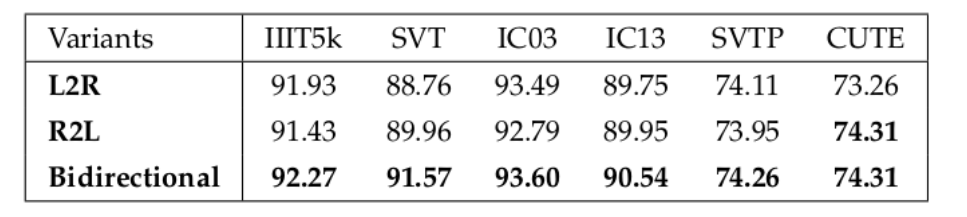
双向解码
为了评估双向解码器的有效性,提出了三种模型变体,即L2R, 从左到右的顺序识别; R2L,从右到左的顺序;双向文本识别。这些变体也使用4.1节中描述的相同训练设置从零开始进行训练。表5比较了它们的识别精度。
端到端识别
最后作者提出了ASTER网络与检测相结合的指导意义:
1.在端到端的检测+识别网络中,ASTER的识别得分可以用于筛选过滤检测框。
2.ASTER网络可以用于矫正检测框。
对此,作者在IC15上分别用TextBoxes、TextBoxes+ASTER无矫正、TextBoxes+ASTER有矫正进行了实验对比。
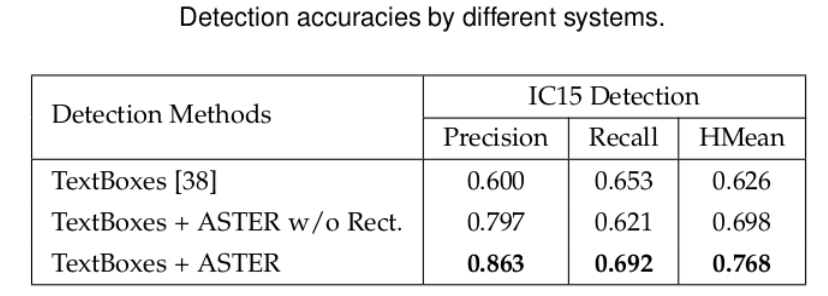
实验结果证明:ASTER对于文本检测具有很好的指导意义,在端到端文本识别中的优势非常明显。
总结
ASTER的提出,无疑是OCR领域的一个重要进展。
它提出了显式图像矫正机制,可以在无额外标注的情况下显著地提升识别网络的识别效果。对空间透视、弯曲等不规则文本具有较好的识别效果。
针对识别网络,提出注意力机制的Seq2Seq模型,并引入双向解码器,能够更好地利用上下文关系,提升识别精度。
与检测网络结合成为端到端识别网络,可以增强文本检测效果的方法,并对不规则文本加以矫正。
参考文献
[1]F. L. Bookstein. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell., 11(6):567–585, 1989.
[2]M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu.Spatial transformer networks. In NIPS, 2015.
[3]B. Shi, X. Wang, P. Lyu, C. Yao, and X. Bai. Robust scene text recognition with automatic rectification. In CVPR, pages 4168–4176, 2016.
[4]Baoguang S , Mingkun Y , Xinggang W , et al.ASTER:An Attentional Scene Text Recognizer with Flexible Rectification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018:1-1.
重磅!CVer-场景文本检测&识别群成立啦
扫码添加CVer助手,可申请加入CVer-场景文本检测&识别交流群,同时还可以加入目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如场景文本检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!

