【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【导读】当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开幕。Google Brain 研究科学家 Ian Goodfellow 在会上作为主题为《生成对抗网络(Generative Adversarial Networks)》的Tutorial 最新演讲, 介绍了GAN的原理和最新的应用。为此,专知内容组整理了的Goodfellow的slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新ICCV 2017 GAN slide。
GANs
「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial Networks),这几年,他每到大会就会讲 GAN,毕竟对抗生成网络之父的头衔在呢,这块也是这几年机器学习、计算机视觉等方向的研究热点之一。

Ian Goodfellow 是世界上最重要的 AI 研究者之一,他在 OpenAI(谷歌大脑的竞争对手,由 Elon Must 和 Sam Altman 创立)工作过不长的一段时间,今年3月重返 Google Brain, 加入Google Brain,其正在建立了一个探索“生成模型”(generative models)的新研究团队。
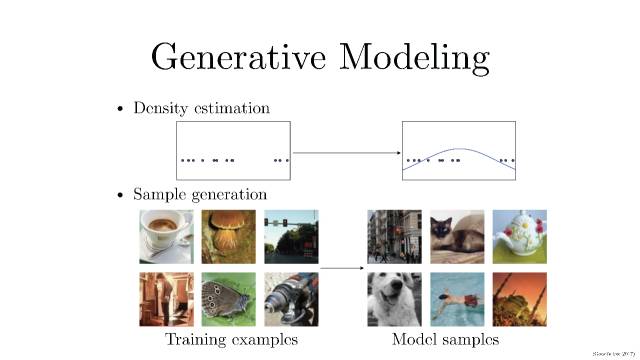
生成模型的概念大家应该都很熟悉,大概有两种玩法:
· 密度(概率)估计:就是说在不了解事件概率分布的情况下,先假设随机分布,然后通过数据观测来确定真正的概率密度是怎样的。
· 样本生成:这个就更好理解了,就是手上有一把训练样本数据,通过训练后的模型来生成类似的「样本」。
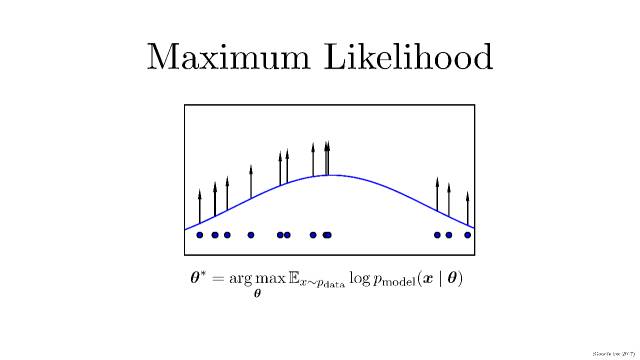
在生成模型这一过程中,首先需要提到概率领域一个方法:最大似然估计,
现实生活中,我们可能并不知道每个 P(概率分布模型)到底是什么,我们已知的是我们可以观测到的源数据。所以,最大似然估计就是这种给定了观察数据以评估模型参数(也就是估计出分布模型应该是怎样的)的方法。
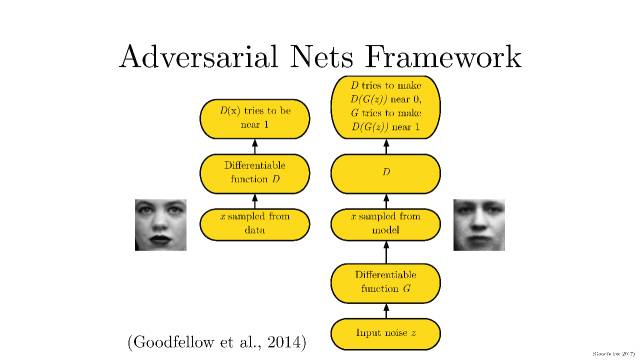
我们在理解生成对抗模型(GAN),首先要知道生成对抗模型拆开来是两个东西:一个是判别模型,一个是生成模型。就需要提及Ian Goodfellow在2014发表的文章。文章标题:Generative Adversarial Networks。文章链接:https://arxiv.org/abs/1406.2661。
具体如下:
简单打个比方就是:两个人比赛,看是 A 的矛厉害,还是 B 的盾厉害。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。A 拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。B 则拼命地想把真实数据和假数据区分开。
这里,A 就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 B。而 B 则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出 A 的骗人技巧。
如此这般,随着 B 的鉴别技巧的越来越牛,A 的骗人技巧也是越来越纯熟。
一个造假一流的 A,就是我们想要的生成模型!

我们现在能使用GANs做什么,这几年各种围绕关于GANs的研究应用很多很多。
· 学习训练数据的分布;
· 在更多的情况是,我们会面临缺乏数据的情况,我们可以通过生成模型来补足。比如,用在半监督学习中;
· 多标签预测(同时完成real/fake, 样本类别等的预测);
· 根据环境需要生成相应数据(比如,看到一个美女的背影,猜她正面是否会让你失望……)
· 可以模拟预测未来数据(用于具有时序关系的图像)
· 解决模型推断问题
· 学习不错的embedding(特征表示)信息

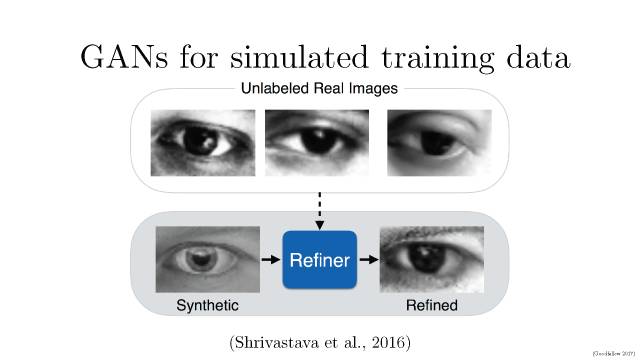
以保密为文化传统的苹果一贯不喜欢对外公布自己的研究成果。但2016年在机器学习的顶级大会NIPS上,苹果AI团队的负责人RussSalakhutdinov宣布,公司已经允许自己的AI研发人员对外公布论文成果。这则消息刚刚宣布没多久,苹果就发表了自己的第一篇论文,题目叫做《通过对抗训练从模拟与无监督图像中学习》,论文描述了如何利用计算机生成的图像而不是真实图像改进算法识别图像能力的训练。此举一方面可以提高苹果在AI界的存在感,同时如果其研究成果出色的话,也能在学术界赢得同行认可,并吸引到AI方面的人才。苹果第一篇AI论文一经投放,便在2017年7月22日,斩获CVPR 2017最佳论文。

谷歌新论文使用生成对抗网络的无监督像素级域适应, 发表在CVPR 2017
Unsupervised Pixel-Level Domain Adaptation WithGenerative Adversarial Networks
对于许多任务而言,收集标注良好的数据集去训练现代的机器学习算法是极其昂贵
的。渲染合成数据倒是一个吸引人的选择,本文的方法能以无监督的方式学习一个像素空间中从一个域到另一个域的变换。基于生成对抗网络(GAN)的方法能够使源域(source-domain)图像看起来就像是来自目标域(target domain)的一样。这个模型不仅能生成看似可信的样本,而且表现还极大超越了许多当前最佳的无监督域适应情况。

开始介绍面临缺乏数据的情况,我们可以通过生成模型来补足。

内容识别填充(: Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。在这篇博客中,我会介绍 RaymondYeh 和 Chen Chen 等人的一篇论文,“基于感知和语境损失的图像语义修补(Semantic Image Inpainting with Perceptual and ContextualLosses)”。论文在2016年7月26号发布于 arXiv 上,介绍了如何使用 DCGAN 网络来进行图像补全。

体验一下半监督学习。

将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类别标签。我们在一个数据集上训练一个产生式模型 G 以及 一个判别器 D,输入是N类当中的一个。在训练的时候,D被用于预测输入是属于 N+1的哪一个,这个+1是对应了G的输出。这种方法可以用于创造更加有效的分类器,并且可以比普通的GAN 产生更加高质量的样本。
文章标题:Semi-Supervised Learning with Generative Adversarial Networks;文章链接:https://arxiv.org/abs/1606.01583。
文章标题:Improved Techniques for Training GANs
文章链接:https://arxiv.org/abs/1606.03498

开始介绍多标签预测(同时完成real/fake, 样本类别等的预测);
转自:专知
完整内容请点击“阅读原文”



