旷视IPO在即,看清“AI第一股”的商业真相
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

AI公司是软件公司吗?是SaaS、PaaS还是传统软件厂商?
AI公司是解决方案商吗?是集成商?还是外包公司?
AI公司的壁垒究竟在哪里?真的是“深度学习”所代表的的AI技术?
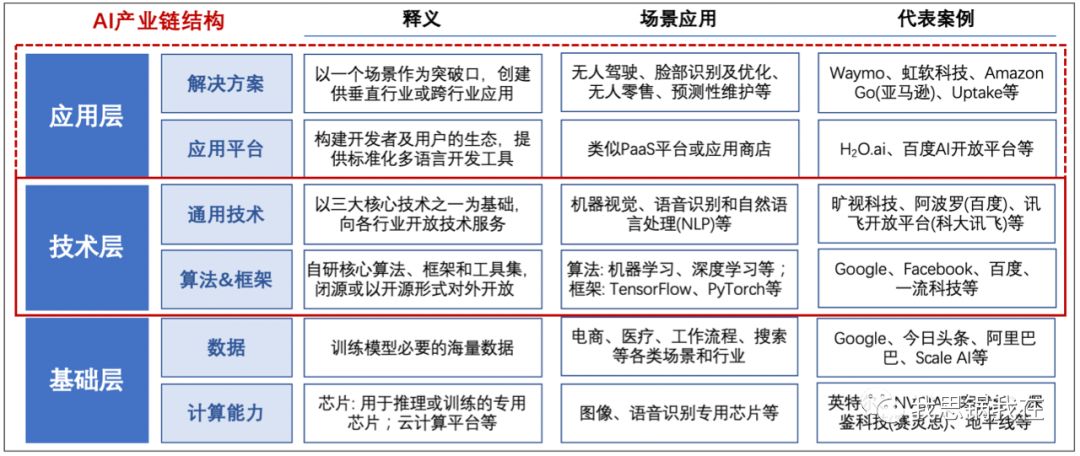
以一个场景(如人脸识别)作为突破口,通过连接企业客户内部系统或自建场景入口如传感器等方式获取数据,基于多维度的数据不断训练模型、优化算法,在某一个场景问题中找到最佳解,再向其他行业中相似的场景复制;
以一种通用技术(如机器视觉)作为突破口,深耕算法和底层框架,尤其当机器学习被工业界接纳后,从底层驱动训练模型,不仅能提升方案在不同场景下的普适性和运算效率,也最终提升了实际应用效果。
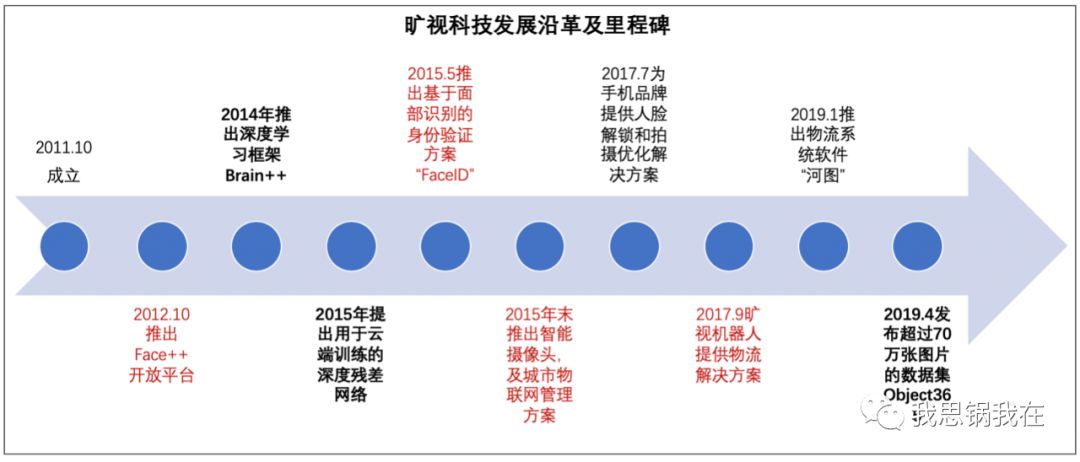
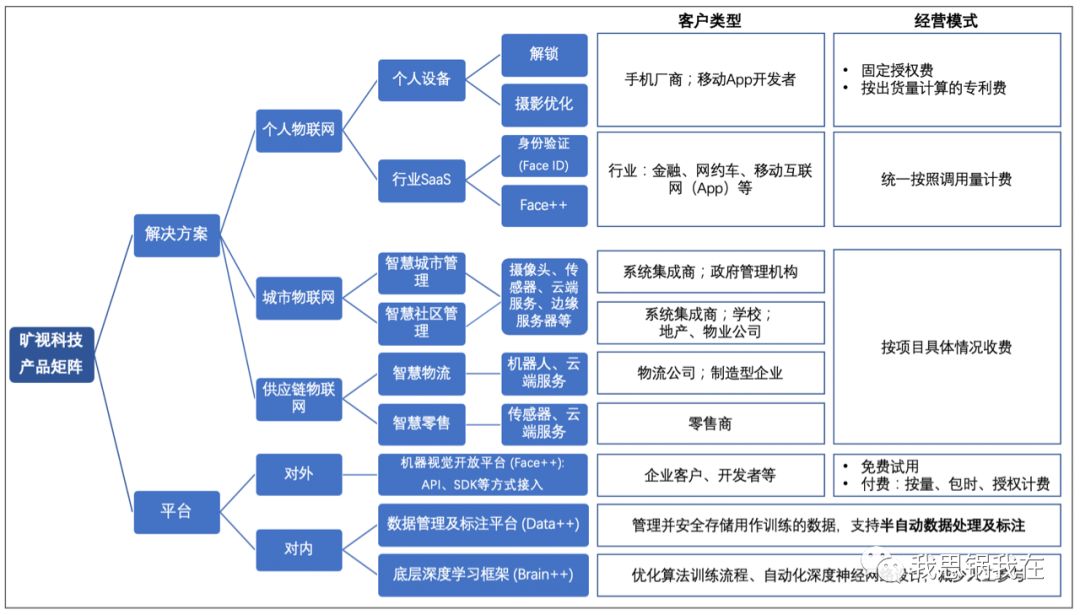
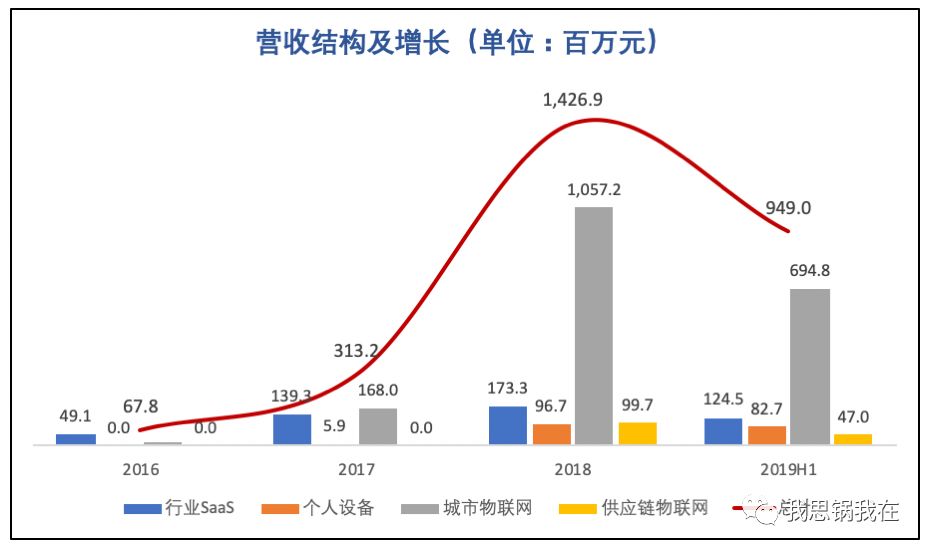
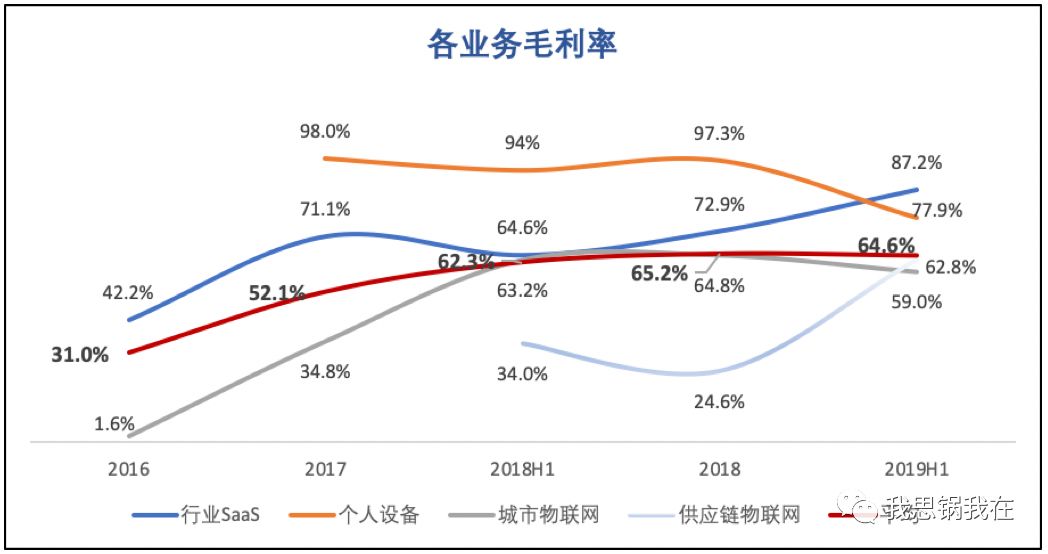
面向垂直行业提供云端身份识别的“行业SaaS”毛利率波动较大,不同于美国一系列典型SaaS上市公司的毛利率表现;
“个人设备”业务毛利率在2019年骤降,照理来说,越早商业化的业务毛利率应该随边际成本下降而上升或至少保持稳定;
城市与供应链物联网解决方案是当前商业化的主战场,但以偏传统的项目制模式对抗市场中的各路玩家,旷视能继续保持同样的竞争力吗?

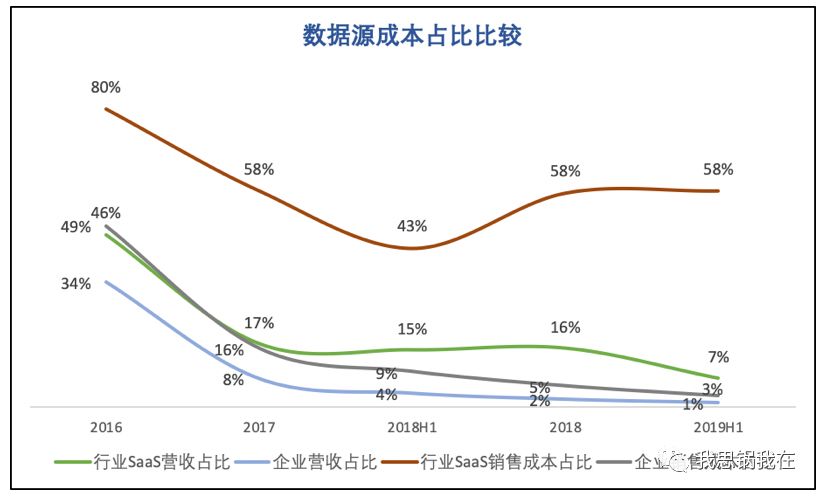
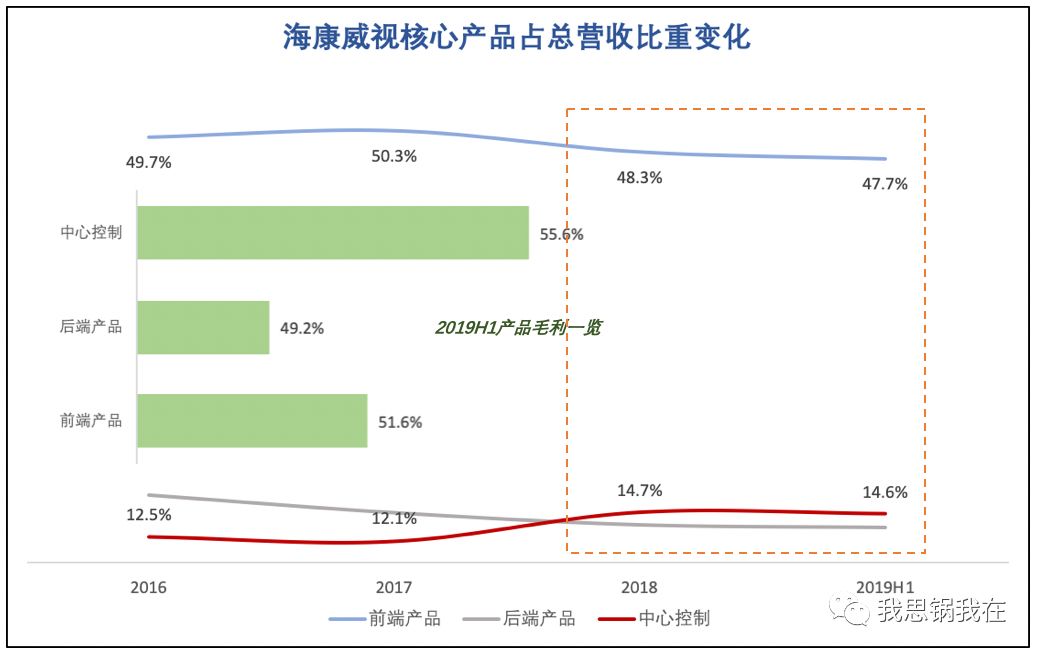
(上图为数据源成本占行业SaaS、总营收和成本比重对比,
下图为总销售成本中各类成本占比情况)
相对云服务成本,数据源成本占行业SaaS销售成本大头,接近60%。由于2018年全年平均比例大于2018年上半年,我们有理由认为2019年全年平均比例也会比2019年上半年的数字有所提升,近两年呈上升趋势;
从占行业SaaS营收比重来看,数据源成本的确呈下降的趋势。但是to B行业普遍在下半年进入业务高峰,同样参照数据源成本在2018年的表现,即便2019年上半年成本比例已经下降到7%,并不能说明2019年全年平局比例会显著下降;
当前行业解决方案大多以人脸识别为典型使用场景,而当识别技术拓展到人体、物体、文字等其他种类的时候,自然需要采购丰富且必要的第三方数据用以模型训练,那么未来数据源成本占比可能不会延续逐年下降的趋势;
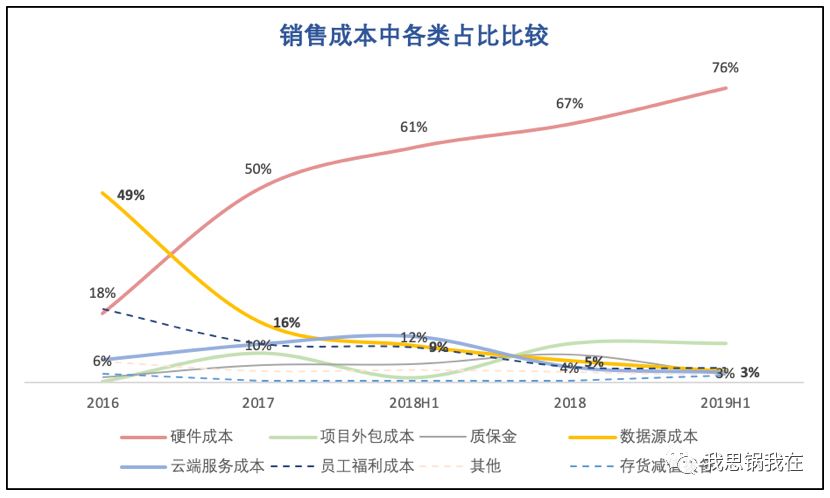
最后从公司整体销售成本结构来看,除了硬件,外包、云服务和数据源是剩下的三大成本。而AI三要素:算法、算力和数据,后两者都与之息息相关。
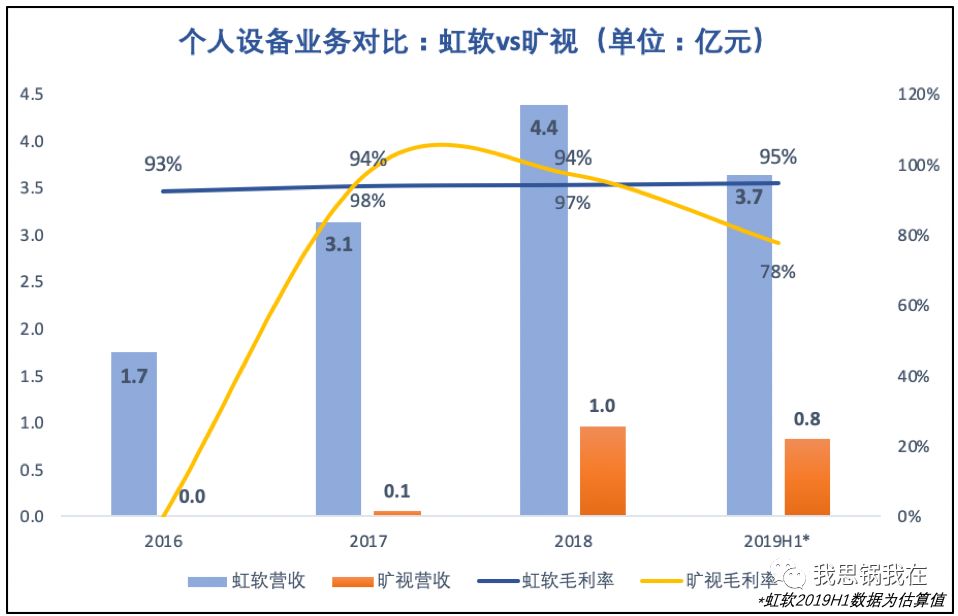
2018年个人设备业务营收已占总营收96%,可以认为虹软的主营业务就是为手机厂商提供视觉技术方案,与旷视“个人设备”业务基本一致;
虹软的个人设备业务通过合约的方式授权给手机厂商,允许客户将相关算法软件或软件包装载在约定型号的设备上,以此收取技术和软件授权使用费,收费模式也与旷视一致;
此块业务的营收成本主要来自工资薪金及相关费用计入公司营业成本的技术人员,而数量占公司总人数比例较低(2018年仅为10%),且公司授权许可的相关算法软件或软件包一般无需实体硬件的生产、包装及运输,因此毛利较高。
充分考虑移动终端上的硬件限制,在不牺牲效果的基础上对算法进行了大量简化和优化;
累积了大量模块化的产品和底层算法库;
与摄像头产业链深度合作,比如开发的智能模组产线标定方案、智能手机组装线标定方案为厂商节省了大量硬件和制造成本,达成快速量产。
由于旷视目前业务规模仍相对较小,不具备与摄像头厂商深度合作的能力,那么为了提升向手机厂商的交付效率同时保证品质,需要向摄像头厂商提前采购摄像头模组,用于快速研发并适配特定手机型号的视觉算法,组装测试后再向手机厂商统一发货;
因此,旷视个人设备业务在2019年上半年出现毛利率下降的情况可能是暂时的,硬件成本的支出增加只是当下在供应链策略上的临时选择,未来销量达到一定规模后,毛利率将可能恢复到与虹软相似的水平。
结合这项调研和对AI的基本认识,我认为主要原因如下:
模型训练需要引入机器学习甚至深度学习,由于深度学习用到的多层神经网络仍是“黑箱”型,即技术人员很难彻底了解深层网络的内核,也无法完全掌握输入与输出、各参数间相互影响等关系,因此调参并优化是一个非常缓慢的过程;
深度学习需要大量的数据或样本,并且数据量越大,对数据质量的要求也越高,需要尽可能覆盖真实场景中的极端案例(corner case)。比如在客服场景中,用户问“我想查一下在前天下午去星巴克买卡布奇诺之前在学校食堂花了多少钱?”,而一般第三方数据公司提供的问题集很难达到如此细的颗粒度,想要进一步优化算法,便需要在系统内部或真实场景中补全极端案例了。
数据获取成本将随着算法升级而越来越高;
同时数据很可能会过时,老旧的数据需要及时被剔除或重新标注。
并且,由于越往后算法迭代的耗时越长,一方面会导致服务器成本(通常在云端)呈非线性增长,另一方面在数据处理上人为干预就很可能是必要的。

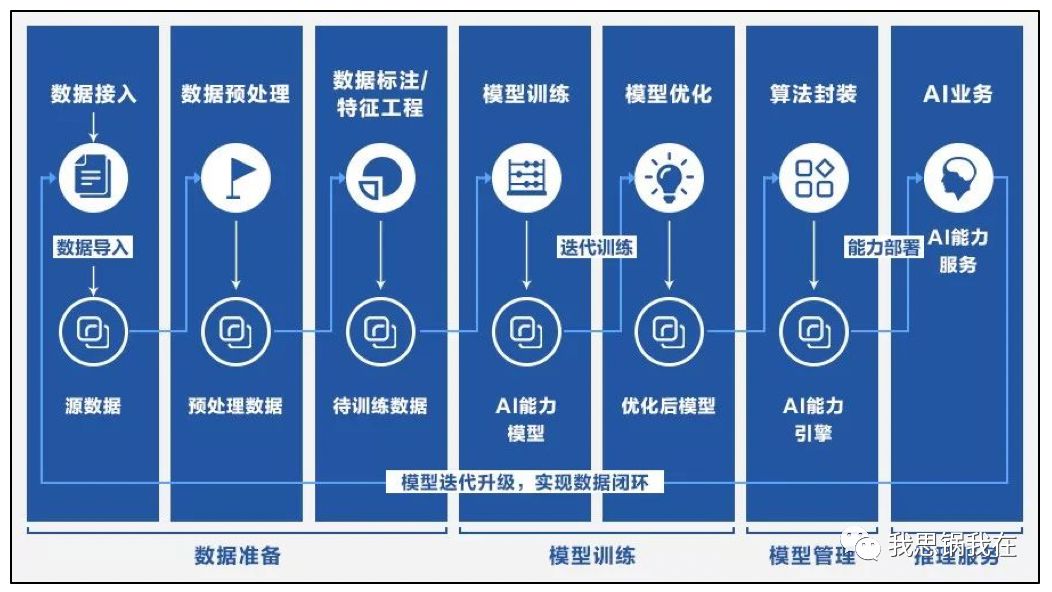
根据旷视研究院的相关介绍,Brain++已经发展成为一个支撑算法研究和开发的基础底层,由三个模块组成:深度学习框架MegEngine、深度学习云计算平台MegCompute和数据管理平台MegData(也就是后来的Data++),对应AI的三大要素。覆盖的功能从数据的获取、清洗、预处理等,到研究人员设计算法架构、实验环节、搭建训练环境、训练、调参、模型效果评估,再到最终的模型分发和部署应用,其中特别强调了几个独特的优势:
针对计算机视觉任务做了定制化的优化,尤其面对大量图像或视频训练任务;
AutoML技术自动化设计深度神经网络,将算法的生产自动化,从而让研究人员用最少的人力和时间针对垂直领域碎片化的需求定制多种算法组合,包括“长尾需求”(即极端案例);
通过对基础设施、数据存储和计算的智能调动来保证多用户多任务操作,提升训练效率,也变相降低了云服务成本;
我不是AI专家,在这里对Brain++的性能和技术高度不展开讨论。但之前的疑问逐渐得到了解答,旷视之所以如此重视对Brain++的投入并称之为公司的“核心竞争力”,是因为深度学习框架在我看来像一个操作系统,帮助研究人员根据场景应用的不同、终端硬件条件的差异以及投入回报的高低而尽可能自动化地寻找最优方案。同时Data++所支持的半自动数据处理和标注功能,允许多个人同时访问同一套数据进行训练,目的也是希望从根本上降低带宽和标注成本。
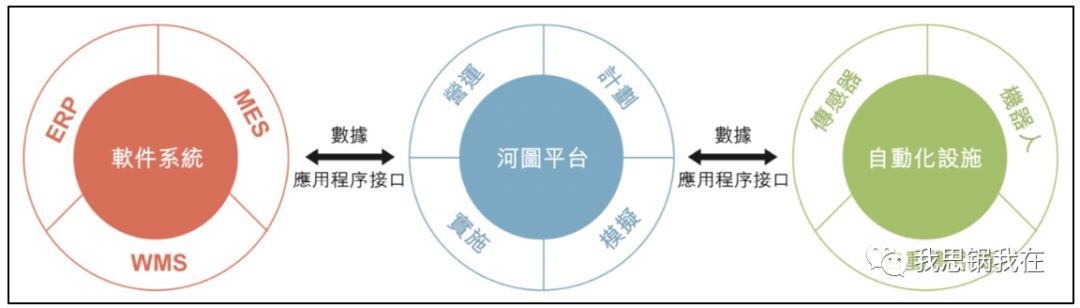 (“河图平台”的生态连接设计)
(“河图平台”的生态连接设计)
“AI”真的会成为旷视的“成本中心”吗?公司该如何解决看似无法消除的数据源及云服务成本问题?
旷视提到的“行业SaaS”真的是SaaS吗?而曾经被高呼的“AIaaS”到底是什么模式?
“AIaaS”的护城河究竟在哪里?旷视又是如何做的?
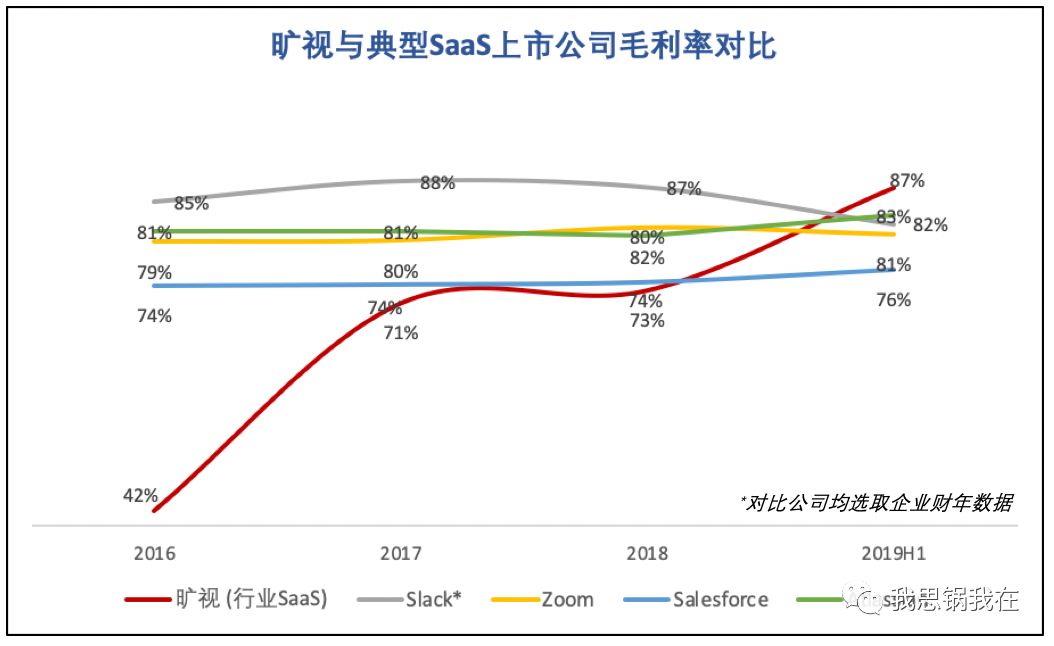
我们仍不能把旷视当前业务中的“行业SaaS”与市场上普遍理解的“SaaS”产品画上等号,原因在于暂时无法避免的数据源成本导致不可预测的毛利率波动;
数据在算法模型迭代的过程中并不会产生理想化的网络效应,要避免数据、计算等资源成为成本中心,自动化的算法生成和数据标注可能是最高效的解决办法,所以这更考验公司在深度学习等底层技术上的造诣以及战略规划;
AI公司在商业化上将会遇到各路阻力,唯有将产品销售思路转为可持续性的服务模式,才有机会突围。核心在于从战略上一开始便进行智能系统层的设计,建立生态连接。
开源(或部分开源)Brain++:当前两大开源深度学习框架Google的TensorFlow和Facebook的PyTorch正打得不可开交,性能优劣不予置评。而有意思的是,先进入主流的TensorFlow凭借性能稳定与安全牢牢占据着工业界,而后入者PyTorch则通过易上手和操作简单在学术界撕开了一道裂缝。对比之下,旷视的优势一定在引以为豪的机器视觉垂直方向上,而保持该领域领先地位的重要方式则是建立开发者生态。基于国内得天独厚的数据及商业场景的优势,未来如果当机器学习甚至深度学习成为下一代IT建设的标配时,至少在视觉领域旷视便可占尽天时、地利与人和;
为模型训练创造一套标准语言并向生态开放:听闻从2018年起团队就在规划一种用于深度学习训练的编程语言,用于协调训练所需要的灵活性以及推理所需的性能要求。去年2月Facebook首席AI科学家Yann LeCun也提到了是否需要一种比Python更灵活的语言来进行深度学习设计。所以行业内的探索在国内外都尚处早期,既然在机器视觉上旷视乃至国内同行都能与国际巨头不分伯仲,我相信这个机会属于提早布局的人;
布局制造业:制造业占我国GDP近三分之一的比重,机器视觉最先在国外进入工业领域,主要用于尺寸测量与外观检测。如今在硬件端,从自然光、红外到激光,从2D到3D摄像头,百花齐放。海康威视也于2017年发布了工业相机产品系列。而在软件端AI的探索才刚刚开始。尽管样本数量与质量的匮乏对深度学习的落地造成了一定阻碍,或许这正好是旷视和其开放生态的机会。待真实场景和需求明确之前,提前进行相关布局,这又是一个百亿级的市场。

 读到这里,想必对旷视的业务逻辑、商业创新以及竞争力有了基本认识。
读到这里,想必对旷视的业务逻辑、商业创新以及竞争力有了基本认识。
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!





